前言
Crawlab 也是我用了很长时间的爬虫调度平台,但是最后由于爬虫依赖的环境越来越复杂,不得不放弃它转而使用自建容器并结合 K3s 来管理爬虫任务。
而在这次重构中,考虑到可观测性,最终还是选回 Crawlab 来作为爬虫调度平台,而环境则完全配置在 Crawlab Worker 容器中。
方案概述
- 在单独的虚拟机上使用 Docker 部署
Crawlab服务端 - 在
K3s集群中部署Crawlab Worker来执行爬虫任务 - 创建测试爬虫以验证整个流程
部署架构
- Crawlab 服务端(Master 节点)部署在独立的虚拟机上,使用 Docker Compose 来运行服务。
- K3s 集群拥有 1 个控制节点和 2 个工作节点,Worker 部署在工作节点上,以便利用集群的计算资源。
- Crawlab 服务端(Master 节点)需要的 MongoDB 数据库运行在了其他机器上。
| 角色 | 主机名 | IP 地址 | 备注 |
|---|---|---|---|
| MongoDB 数据库 | crawlab-mongo | 192.168.1.104 | 存储 Crawlab 的数据 |
| Crawlab Master | crawlab-master | 192.168.1.103 | 负责调度任务、提供 Web UI |
| K3s Server(控制节点) | k3s-server | 192.168.1.100 | 配置 Crawlab Worker 的部署任务,不直接运行 Worker |
| K3s Agent(工作节点) | k3s-agent-01 | 192.168.1.101 | 运行 Crawlab Worker |
| K3s Agent(工作节点) | k3s-agent-02 | 192.168.1.102 | 运行 Crawlab Worker |
操作步骤
一、在独立的虚拟机上使用 Docker 部署 Crawlab 服务端
Docker 的安装可以参考我的另一篇文章:Ubuntu 20.04 从官方源安装最新的 Docker
创建工作目录并编写 docker-compose.yml 文件:
mkdir -vp /opt/crawlab/.crawlab # 持久化 crawlab 元数据
mkdir -vp /opt/crawlab/data # 持久化 crawlab 数据
mkdir -vp /opt/crawlab/logs # 持久化 crawlab 任务日志
cd /opt/crawlab
nano docker-compose.yml我已经有了预先安装好的
MongoDB:部署 MongoDB 并结合 Prometheus 和 Grafana 进行监控
当然也需要先创建好crawlab数据库和用户,授权给crawlab用户访问crawlab数据库的权限:mongoshuse admin // 先使用 admin 数据库进行认证 db.auth("admin", "<your_password>") // 切换到 crawlab 数据库 use crawlab // 创建 crawlab 用户并授权 db.createUser({ user: "crawlab", pwd: "crawlab", roles: [{ role: "readWrite", db: "crawlab" }] })
version: '3.3'
services:
master:
image: crawlabteam/crawlab:latest
container_name: crawlab-master
restart: always
environment:
CRAWLAB_NODE_MASTER: "Y"
# 替换为你 MongoDB 的实际 IP 和端口
CRAWLAB_MONGO_HOST: "192.168.1.104"
CRAWLAB_MONGO_PORT: "27017"
CRAWLAB_MONGO_DB: "crawlab"
CRAWLAB_MONGO_USERNAME: "crawlab"
# 修改为你设置的 MongoDB 用户 crawlab 的密码
CRAWLAB_MONGO_PASSWORD: "crawlab"
CRAWLAB_MONGO_AUTHSOURCE: "crawlab"
ports:
- "8080:8080" # Web UI
- "9666:9666" # GRPC 端口,用于 Worker 连接
volumes:
- /opt/crawlab/data:/data
logging:
driver: "json-file"
options:
max-size: "500m"
max-file: "3"然后启动服务端:
docker compose up -d确认无误后,你可以在浏览器中访问 http://192.168.1.103:8080,默认的用户名和密码都是 admin。
二、在 K3s 集群中部署 Crawlab Worker
接下来,我们需要在 K3s 集群中部署 Crawlab Worker 节点。
首先我们创建一个存放配置的目录并编写部署文件:
mkdir -vp /root/k3s/crawlab/crawlab-worker
nano /root/k3s/crawlab/crawlab-worker/worker-deployment.yaml填入以下内容:
---
# 声明并创建 crawlab 命名空间
apiVersion: v1
kind: Namespace
metadata:
name: crawlab
---
# 实际的部署配置
apiVersion: apps/v1
kind: Deployment
metadata:
name: crawlab-worker
namespace: crawlab
spec:
# 设置副本数,可以根据集群规模随意扩展
replicas: 2
# 每次重新部署都构建新的 Pod
strategy:
type: Recreate
selector:
matchLabels:
app: crawlab-worker
template:
metadata:
labels:
app: crawlab-worker
spec:
# 启用主机网络以访问 Tailscale 私网其他服务
hostNetwork: true
# 在做了集群级别的分流的基础上,只需保持默认的 DNS 策略即可
dnsPolicy: ClusterFirstWithHostNet
affinity:
nodeAffinity:
# 增加节点亲和性配置,确保 Worker 只调度到非控制平面的节点上
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node-role.kubernetes.io/control-plane
operator: DoesNotExist
- key: node-role.kubernetes.io/master
operator: DoesNotExist
# 增加 Pod 反亲和性配置,强制要求 Pod 调度到不同的机器上
# 如果副本数超过了节点数,Kubernetes 会尽力调度,但可能会有部分 Pod 处于 Pending 状态,直到有足够的资源可用
# 因此推荐副本数和节点数保持一致
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: crawlab-worker
topologyKey: "kubernetes.io/hostname"
containers:
- name: worker
image: crawlabteam/crawlab:latest
env:
# 将 K3s Agent 的名字作为 Crawlab Worker 的名字
- name: CRAWLAB_NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
# 非 Master 节点
- name: CRAWLAB_NODE_MASTER
value: 'N'
# 替换为你部署 Master 节点的虚拟机的 IP 和暴露的 GRPC 端口
- name: CRAWLAB_GRPC_ADDRESS
value: '192.168.1.103:9666'
# 配置和主节点文件同步的 API 地址
- name: CRAWLAB_FS_FILER_URL
value: 'http://192.168.1.103:8080/api/filer'
restartPolicy: Always应用此部署:
kubectl apply -f /root/k3s/crawlab/crawlab-worker/worker-deployment.yaml拉取失败的话,可以用下面的命令查看详细日志:
kubectl describe pod crawlab-worker-6bxxxxxbbfc-xxxx -n crawlab如果需要设置使用 Docker 镜像加速地址的话,不只是
K3s Server,你还需要登录到每个K3s Agent节点上进行设置:mkdir -vp /etc/rancher/k3s nano /etc/rancher/k3s/registries.yamlmirrors: "docker.io": endpoint: - "https://registry.example.com"然后重启服务:
systemctl restart k3s-agent
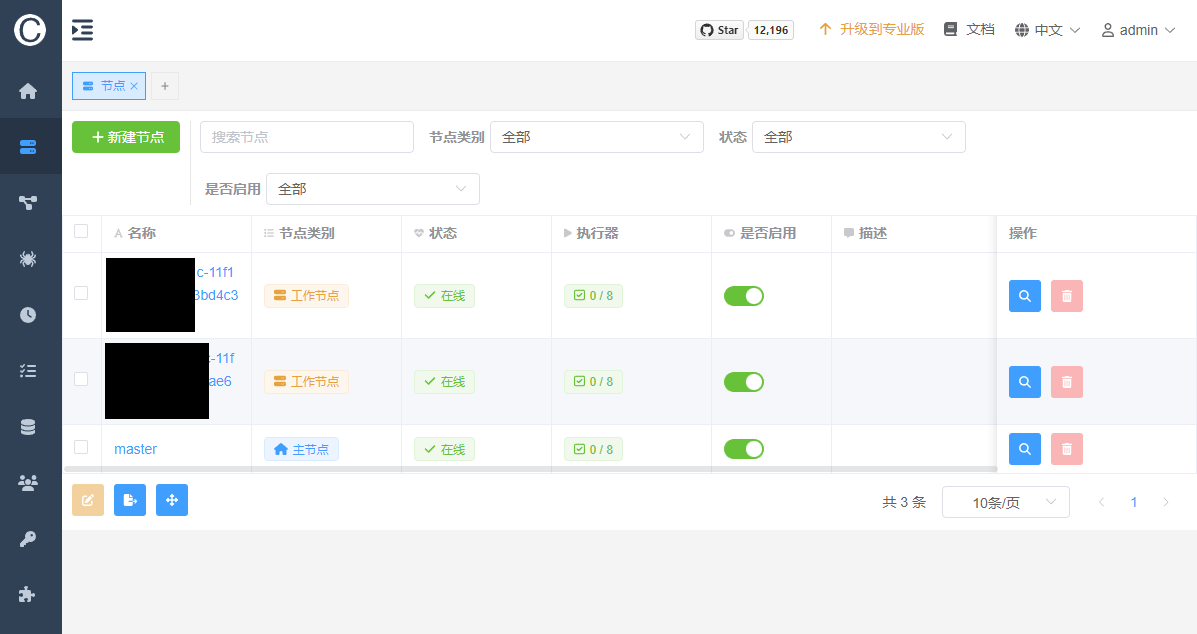
查看 Pod 状态以及是否成功运行:
kubectl get pods -n crawlab -l app=crawlab-worker如果 Pod 正常 Running,您可以回到 Crawlab UI 的节点页面,就可以看到有新的工作节点已经上线了:
你可以通过下面的方式找到所有
Crawlab Worker和K3s Agent的映射关系:kubectl get pods -n crawlab -l app=crawlab-worker -o wide kubectl logs crawlab-worker-6bxxxxxbbfc-xxxx -n crawlab日志中会打印 Worker 的 ID。
三、创建测试爬虫以验证整个流程
最后,我们在 Crawlab 界面中添加一个简单的爬虫脚本来验证分布式执行。
在左侧菜单选择爬虫,再点击 + 新建爬虫:
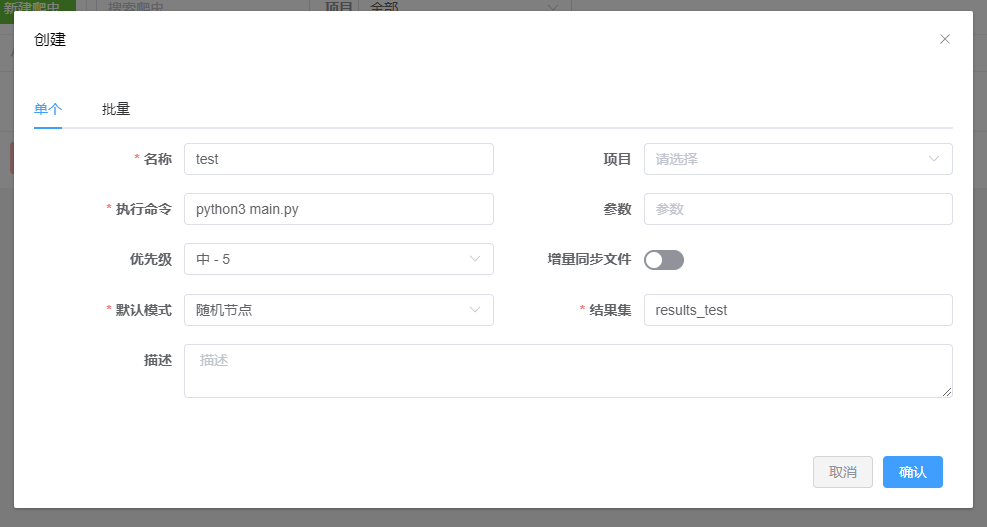 上传下面的测试爬虫脚本
上传下面的测试爬虫脚本 main.py:
import time
def main():
print("🚀 开始在 Kubernetes Worker 节点上执行爬虫任务...")
time.sleep(2)
print("✅ 数据抓取完成!")
if __name__ == "__main__":
main()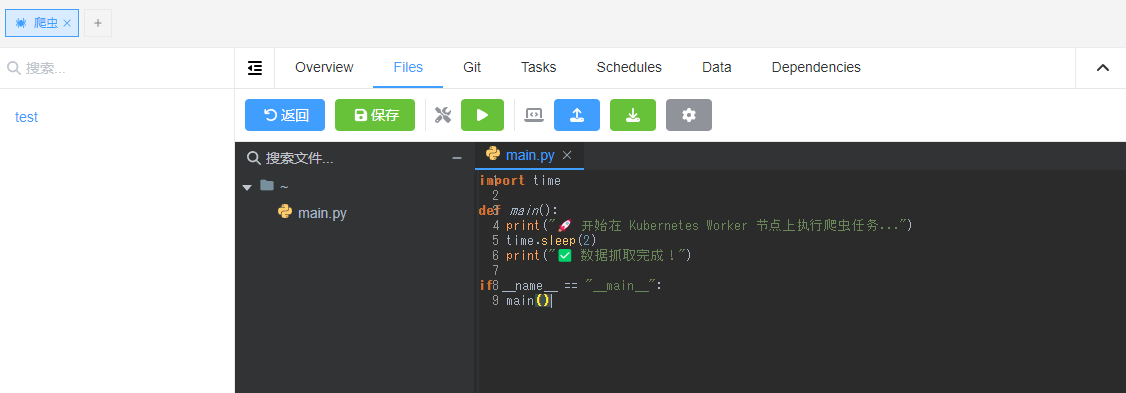
执行的时候,选中所有节点,一般不会有问题,最终有 3 次执行结果(2 个 Worker 节点和 1 个 Master 节点都执行了):

结束。