来源:Amazon AWS Certified Solutions Architect - Associate SAA-C03 Exam
65 题 (No.386 ~ No.450) 只记录了 21 道首次碰到的、错误的或有疑问的题目,仅供自己复习使用。
与正式考试题量一样,总共耗时 98/(130+30) 分钟,正确率为 49/65。
如果侵权请联系删除。
一、PoLP with CloudFormation stack
A new employee has joined a company as a deployment engineer. The deployment engineer will be using AWS CloudFormation templates to create multiple AWS resources. A solutions architect wants the deployment engineer to perform job activities while following the principle of least privilege.
Which combination of actions should the solutions architect take to accomplish this goal? (Choose two.)
- Have the deployment engineer use AWS account root user credentials for performing AWS CloudFormation stack operations.
- Create a new IAM user for the deployment engineer and add the IAM user to a group that has the PowerUsers IAM policy attached.
- Create a new IAM user for the deployment engineer and add the IAM user to a group that has the AdministratorAccess IAM policy attached.
- ✅ Create a new IAM user for the deployment engineer and add the IAM user to a group that has an IAM policy that allows AWS CloudFormation actions only.
- ✅ Create an IAM role for the deployment engineer to explicitly define the permissions specific to the AWS CloudFormation stack and launch stacks using that IAM role.
✨ 关键词:
4️⃣ 5️⃣ ✅
💡 解析:这里的操作时只赋予开发者操作
CloudFormation的权限,然后再创建一个拥有CloudFormation堆栈操作权限的角色并允许用户代入角色。
CloudFormation 堆栈策略堆栈策略可以帮助防止堆栈资源在堆栈更新期间被意外更新或删除。堆栈策略是一个 JSON 文档,用于定义可在指定资源上执行的更新操作。默认情况下,任何具有cloudformation:UpdateStack权限的 IAM 委托人都可以更新 AWS CloudFormation 堆栈中的所有资源。
👨👨👦👦 社区讨论:Option D, creating a new IAM user and adding them to a group with an IAM policy that allows AWS CloudFormation actions only, ensures that the deployment engineer has the necessary permissions to perform AWS CloudFormation operations while limiting access to other resources and actions. This aligns with the principle of least privilege by providing the minimum required permissions for their job activities.
Option E, creating an IAM role with specific permissions for AWS CloudFormation stack operations and allowing the deployment engineer to assume that role, is another valid approach. By using an IAM role, the deployment engineer can assume the role when necessary, granting them temporary permissions to perform CloudFormation actions. This provides a level of separation and limits the permissions granted to the engineer to only the required CloudFormation operations.
二、User session save
A company hosts a three-tier ecommerce application on a fleet of Amazon EC2 instances. The instances run in an Auto Scaling group behind an Application Load Balancer (ALB). All ecommerce data is stored in an Amazon RDS for MariaDB Multi-AZ DB instance.
The company wants to optimize customer session management during transactions. The application must store session data durably.
Which solutions will meet these requirements? (Choose two.)
- ✅ Turn on the sticky sessions feature (session affinity) on the ALB.
- ❌ Use an Amazon DynamoDB table to store customer session information.
- Deploy an Amazon Cognito user pool to manage user session information.
- ✅ Deploy an Amazon ElastiCache for Redis cluster to store customer session information.
- Use AWS Systems Manager Application Manager in the application to manage user session information.
✨ 关键词:
1️⃣ 2️⃣ ❌ -> 1️⃣ 4️⃣ ✅
💡 解析:重点在于使用什么服务保存用户 Session 使用户在多个运行在不同
EC2实例的节点中保持登陆状态。
用DynamoDB当时是可以实现的,但是官方给了更好的方案:会话管理使用像 Amazon ElastiCache 这样的完全托管服务在云中进行缓存,可以很轻松上手。它消除了设置、管理和实施缓存的复杂性,使您能够专注于能为组织创造价值的任务。立即注册 Amazon ElastiCache。
👨👨👦👦 社区讨论:It is A and D. Proof is in link below.
https://aws.amazon.com/caching/session-management/
三、RPO
A company needs a backup strategy for its three-tier stateless web application. The web application runs on Amazon EC2 instances in an Auto Scaling group with a dynamic scaling policy that is configured to respond to scaling events. The database tier runs on Amazon RDS for PostgreSQL. The web application does not require temporary local storage on the EC2 instances. The company’s recovery point objective (RPO) is 2 hours.
The backup strategy must maximize scalability and optimize resource utilization for this environment.
Which solution will meet these requirements?
- Take snapshots of Amazon Elastic Block Store (Amazon EBS) volumes of the EC2 instances and database every 2 hours to meet the RPO.
- Configure a snapshot lifecycle policy to take Amazon Elastic Block Store (Amazon EBS) snapshots. Enable automated backups in Amazon RDS to meet the RPO.
- ✅ Retain the latest Amazon Machine Images (AMIs) of the web and application tiers. Enable automated backups in Amazon RDS and use point-in-time recovery to meet the RPO.
- ❌ Take snapshots of Amazon Elastic Block Store (Amazon EBS) volumes of the EC2 instances every 2 hours. Enable automated backups in Amazon RDS and use point-in-time recovery to meet the RPO.
✨ 关键词:2 hours
4️⃣ ❌ -> 3️⃣ ✅
💡 解析:运行在
RDS上的数据库只能丢 2 小时的数据,意味着最少 2 小时也要备份一下。 需要明确的是RDS是支持 point-in-time 恢复的:Point-in-time recovery and continuous backup for Amazon RDS with AWS Backup,但是没有必要对EBS卷进行备份,因为数据不存在EC2本地。
3️⃣ 创建AMI用以恢复是更合理的。
在需要对EC2进行灾备的场景下,使用AMI是更好的选择。
👨👨👦👦 社区讨论:that if there is no temporary local storage on the EC2 instances, then snapshots of EBS volumes are not necessary. Therefore, if your application does not require temporary storage on EC2 instances, using AMIs to back up the web and application tiers is sufficient to restore the system after a failure.
Snapshots of EBS volumes would be necessary if you want to back up the entire EC2 instance, including any applications and temporary data stored on the EBS volumes attached to the instances. When you take a snapshot of an EBS volume, it backs up the entire contents of that volume. This ensures that you can restore the entire EC2 instance to a specific point in time more quickly. However, if there is no temporary data stored on the EBS volumes, then snapshots of EBS volumes are not necessary.
四、20,000 IOPS
A company is running a multi-tier ecommerce web application in the AWS Cloud. The application runs on Amazon EC2 instances with an Amazon RDS for MySQL Multi-AZ DB instance. Amazon RDS is configured with the latest generation DB instance with 2,000 GB of storage in a General Purpose SSD (gp3) Amazon Elastic Block Store (Amazon EBS) volume. The database performance affects the application during periods of high demand.
A database administrator analyzes the logs in Amazon CloudWatch Logs and discovers that the application performance always degrades when the number of read and write IOPS is higher than 20,000.
What should a solutions architect do to improve the application performance?
- Replace the volume with a magnetic volume.
- Increase the number of IOPS on the gp3 volume.
- ✅ Replace the volume with a Provisioned IOPS SSD (io2) volume.
- Replace the 2,000 GB gp3 volume with two 1,000 GB gp3 volumes.
✨ 关键词:2,000 GB of storage、read and write IOPS is higher than 20,000
3️⃣ ✅
💡 解析:总共 2 TB 的存储,需要将 IOPS 提升到 20,000。
在 2024 年RDS已经支持了 io2 类型的卷:Amazon RDS now supports io2 Block Express volumes for mission-critical database workloadsAmazon RDS 提供三种存储类型:预调配 IOPS SSD(也称为 io1 和 io2 Block Express)、通用型 SSD(也称为 gp2 和 gp3)和磁性存储(也称为标准存储)。
👨👨👦👦 社区讨论:Answer is C, io2 volumes are supported
https://aws.amazon.com/blogs/aws/amazon-rds-now-supports-io2-block-express-volumes-for-mission-critical-database-workloads/
五、An hour job
An ecommerce company needs to run a scheduled daily job to aggregate and filter sales records for analytics. The company stores the sales records in an Amazon S3 bucket. Each object can be up to 10 GB in size. Based on the number of sales events, the job can take up to an hour to complete. The CPU and memory usage of the job are constant and are known in advance.
A solutions architect needs to minimize the amount of operational effort that is needed for the job to run.
Which solution meets these requirements?
- ❌ Create an AWS Lambda function that has an Amazon EventBridge notification. Schedule the EventBridge event to run once a day.
- Create an AWS Lambda function. Create an Amazon API Gateway HTTP API, and integrate the API with the function. Create an Amazon EventBridge scheduled event that calls the API and invokes the function.
- ✅ Create an Amazon Elastic Container Service (Amazon ECS) cluster with an AWS Fargate launch type. Create an Amazon EventBridge scheduled event that launches an ECS task on the cluster to run the job.
- Create an Amazon Elastic Container Service (Amazon ECS) cluster with an Amazon EC2 launch type and an Auto Scaling group with at least one EC2 instance. Create an Amazon EventBridge scheduled event that launches an ECS task on the cluster to run the job.
✨ 关键词:an hour
1️⃣ ❌ -> 3️⃣ ✅
💡 解析:
Lambda函数最大运行时间为 15 分钟。
👨👨👦👦 社区讨论:The requirement is to run a daily scheduled job to aggregate and filter sales records for analytics in the most efficient way possible. Based on the requirement, we can eliminate option A and B since they use AWS Lambda which has a limit of 15 minutes of execution time, which may not be sufficient for a job that can take up to an hour to complete.
Between options C and D, option C is the better choice since it uses AWS Fargate which is a serverless compute engine for containers that eliminates the need to manage the underlying EC2 instances, making it a low operational effort solution.
Additionally, Fargate also provides instant scale-up and scale-down capabilities to run the scheduled job as per the requirement.Therefore, the correct answer is:
C. Create an Amazon Elastic Container Service (Amazon ECS) cluster with an AWS Fargate launch type. Create an Amazon EventBridge scheduled event that launches an ECS task on the cluster to run the job.
六、Auto Scaling
A solutions architect is designing the architecture for a software demonstration environment. The environment will run on Amazon EC2 instances in an Auto Scaling group behind an Application Load Balancer (ALB). The system will experience significant increases in traffic during working hours but is not required to operate on weekends.
Which combination of actions should the solutions architect take to ensure that the system can scale to meet demand? (Choose two.)
- ❌ Use AWS Auto Scaling to adjust the ALB capacity based on request rate.
- Use AWS Auto Scaling to scale the capacity of the VPC internet gateway.
- Launch the EC2 instances in multiple AWS Regions to distribute the load across Regions.
- ✅ Use a target tracking scaling policy to scale the Auto Scaling group based on instance CPU utilization.
- ✅ Use scheduled scaling to change the Auto Scaling group minimum, maximum, and desired capacity to zero for weekends. Revert to the default values at the start of the week.
✨ 关键词:
1️⃣ 5️⃣ ❌ -> 4️⃣ 5️⃣ ✅
💡 解析:选择指标中提到了有
ALB相关的指标:
ASGAverageCPUUtilization — Auto Scaling组的平均CPU利用率。ASGAverageNetworkIn– 单个实例在所有网络接口上收到的平均字节数。ASGAverageNetworkOut– 单个实例在所有网络接口上发送的平均字节数ALBRequestCountPerTarget– 每目标的应用程序负载均衡器请求计数。这意味着虽然不直接支持 1️⃣ 提到的
ALB容量,但是支持基于每个目标均衡后的请求数进行扩展,1️⃣ 是相对合理的。
但是 4️⃣ 更正确吧,毕竟ASG明确了支持 CPU 相关指标。
👨👨👦👦 社区讨论:Not A - “AWS Auto Scaling” cannot adjust “ALB capacity” (https://aws.amazon.com/autoscaling/faqs/)
Not B - VPC internet gateway has nothing to do with this
Not C - Regions have nothing to do with scaling
七、Network share
A company has a business system that generates hundreds of reports each day. The business system saves the reports to a network share in CSV format. The company needs to store this data in the AWS Cloud in near-real time for analysis.
Which solution will meet these requirements with the LEAST administrative overhead?
- Use AWS DataSync to transfer the files to Amazon S3. Create a scheduled task that runs at the end of each day.
- ✅ Create an Amazon S3 File Gateway. Update the business system to use a new network share from the S3 File Gateway.
- ❌ Use AWS DataSync to transfer the files to Amazon S3. Create an application that uses the DataSync API in the automation workflow.
- Deploy an AWS Transfer for SFTP endpoint. Create a script that checks for new files on the network share and uploads the new files by using SFTP.
✨ 关键词:
3️⃣ ❌ -> 2️⃣ ✅
💡 解析:系统将 .csv 文件保存给网络共享存储。
2️⃣ 的操作更简单些。
👨👨👦👦 社区讨论:Both Amazon S3 File Gateway and AWS DataSync are suitable for this scenario.
But there is a requirement for ‘LEAST administrative overhead’.
Option C involves the creation of an entirely new application to consume the DataSync API, this rules out this option.
八、OLTP
A rapidly growing global ecommerce company is hosting its web application on AWS. The web application includes static content and dynamic content. The website stores online transaction processing (OLTP) data in an Amazon RDS database The website’s users are experiencing slow page loads.
Which combination of actions should a solutions architect take to resolve this issue? (Choose two.)
- Configure an Amazon Redshift cluster.
- ✅ Set up an Amazon CloudFront distribution.
- Host the dynamic web content in Amazon S3.
- ✅ Create a read replica for the RDS DB instance.
- ❌ Configure a Multi-AZ deployment for the RDS DB instance.
✨ 关键词:
2️⃣ 5️⃣ ❌ -> 2️⃣ 4️⃣ ✅
💡 解析:需要解决 OLTP 带来的数据库负载升高而影响用户加载页面。
OLAP 与 OLTP 有何区别?联机分析处理 (OLAP) 系统和联机事务处理 (OLTP) 系统都是帮助您存储和分析业务数据的数据处理系统。您可以收集和存储来自多个来源的数据,例如网站、应用程序、智能电表和内部系统。
- OLAP 对数据进行合并和分组,因此您可以从不同的角度对其进行分析。
- OLTP 能够可靠、高效地存储和更新大量事务数据
OLTP 数据库可以成为 OLAP 系统的多个数据来源之一。
OLTP 确实是非只读操作的。
但是考试的侧重点是:只读副本重点提高性能,跨区域部署强调高可用和容灾。
因此 4️⃣ 和 5️⃣ 中选 4️⃣。
👨👨👦👦 社区讨论:To resolve the issue of slow page loads for a rapidly growing e-commerce website hosted on AWS, a solutions architect can take the following two actions:
- Set up an Amazon CloudFront distribution
- Create a read replica for the RDS DB instance
Configuring an Amazon Redshift cluster is not relevant to this issue since Redshift is a data warehousing service and is typically used for the analytical processing of large amounts of data.
Hosting the dynamic web content in Amazon S3 may not necessarily improve performance since S3 is an object storage service, not a web application server. While S3 can be used to host static web content, it may not be suitable for hosting dynamic web content since S3 doesn’t support server-side scripting or processing.
Configuring a Multi-AZ deployment for the RDS DB instance will improve high availability but may not necessarily improve performance.
十、Savings Plan
A company uses Amazon EC2 instances and AWS Lambda functions to run its application. The company has VPCs with public subnets and private subnets in its AWS account. The EC2 instances run in a private subnet in one of the VPCs. The Lambda functions need direct network access to the EC2 instances for the application to work.
The application will run for at least 1 year. The company expects the number of Lambda functions that the application uses to increase during that time. The company wants to maximize its savings on all application resources and to keep network latency between the services low.
Which solution will meet these requirements?
- Purchase an EC2 Instance Savings Plan Optimize the Lambda functions’ duration and memory usage and the number of invocations. Connect the Lambda functions to the private subnet that contains the EC2 instances.
- Purchase an EC2 Instance Savings Plan Optimize the Lambda functions’ duration and memory usage, the number of invocations, and the amount of data that is transferred. Connect the Lambda functions to a public subnet in the same VPC where the EC2 instances run.
- ✅ Purchase a Compute Savings Plan. Optimize the Lambda functions’ duration and memory usage, the number of invocations, and the amount of data that is transferred. Connect the Lambda functions to the private subnet that contains the EC2 instances.
- Purchase a Compute Savings Plan. Optimize the Lambda functions’ duration and memory usage, the number of invocations, and the amount of data that is transferred. Keep the Lambda functions in the Lambda service VPC.
✨ 关键词:
3️⃣ ✅
💡 解析:Savings Plans
Compute Savings Plans的灵活性最高,最高可帮助您节省 66% 的费用。这些计划会自动应用于 EC2 实例用量,不分实例系列、大小、可用区、区域、操作系统或租期,并且还适用于 Fargate 和 Lambda 的使用。 例如,注册 Compute Savings Plans 后,您可以随时从 C4 实例更改为 M5 实例,将工作负载从欧洲(爱尔兰)区域转移到欧洲(伦敦)区域,或者将工作负载从 EC2 迁移到 Fargate 或 Lambda,并继续自动支付 Savings Plans 价格。EC2 Instance Savings Plans可提供最低的价格,最高可提供 72% 的折扣,以换取在单个区域内使用单个实例系列的承诺(例如在弗吉尼亚北部区域使用 M5 实例)。这会自动降低您在该区域的选定实例系列成本,不分可用区、实例大小、操作系统或租期。借助 EC2 Instance Savings Plans,您可以灵活地在该区域的一个实例系列中更改实例的使用情况。例如,您可以从运行 Windows 的 c5.xlarge 实例迁移到运行 Linux 的 c5.2xlarge 实例,并自动享受 Savings Plan 价格。
Compute Savings Plans可以更改实例类型,更灵活;EC2 Instance Savings Plans不能更改实例类型,但是更便宜。
但是由于Compute Savings Plans还适用于Lambda函数和Fargate,因此在这个场景下更省钱,选 3️⃣。
👨👨👦👦 社区讨论:Answer C is the best solution that meets the company’s requirements.
By purchasing a Compute Savings Plan, the company can save on the costs of running both EC2 instances and Lambda functions. The Lambda functions can be connected to the private subnet that contains the EC2 instances through a VPC endpoint for AWS services or a VPC peering connection. This provides direct network access to the EC2 instances while keeping the traffic within the private network, which helps to minimize network latency.
Optimizing the Lambda functions’ duration, memory usage, number of invocations, and amount of data transferred can help to further minimize costs and improve performance. Additionally, using a private subnet helps to ensure that the EC2 instances are not directly accessible from the public internet, which is a security best practice.
十一、Policy Principal
A solutions architect needs to allow team members to access Amazon S3 buckets in two different AWS accounts: a development account and a production account. The team currently has access to S3 buckets in the development account by using unique IAM users that are assigned to an IAM group that has appropriate permissions in the account.
The solutions architect has created an IAM role in the production account. The role has a policy that grants access to an S3 bucket in the production account.
Which solution will meet these requirements while complying with the principle of least privilege?
- Attach the Administrator Access policy to the development account users.
- ✅ Add the development account as a principal in the trust policy of the role in the production account.
- Turn off the S3 Block Public Access feature on the S3 bucket in the production account.
- ❌ Create a user in the production account with unique credentials for each team member.
✨ 关键词:
4️⃣ ❌ -> 2️⃣ ✅
在基于资源的 JSON 策略中使用 Principal 元素指定允许或拒绝访问资源的主体。
您必须使用基于资源的策略中的 Principal 元素。包括 IAM 在内的多项服务支持基于资源的策略。IAM 中唯一基于资源的策略类型是角色信任策略。在 IAM 角色中,在角色的信任策略中使用 Principal 元素来指定可担任该角色的对象。对于跨账户存取,您必须指定受信任账户的 12 位标识符。
在基于资源的策略中,将指定账户添加到
Principal中可以授权其访问资源。
👨👨👦👦 社区讨论:By adding the development account as a principal in the trust policy of the IAM role in the production account, you are allowing users from the development account to assume the role in the production account. This allows the team members to access the S3 bucket in the production account without granting them unnecessary privileges.
十二、Amazon RDS Multi-AZ DB cluster DR
A company wants to use an Amazon RDS for PostgreSQL DB cluster to simplify time-consuming database administrative tasks for production database workloads. The company wants to ensure that its database is highly available and will provide automatic failover support in most scenarios in less than 40 seconds. The company wants to offload reads off of the primary instance and keep costs as low as possible.
Which solution will meet these requirements?
- ❌ Use an Amazon RDS Multi-AZ DB instance deployment. Create one read replica and point the read workload to the read replica.
- Use an Amazon RDS Multi-AZ DB duster deployment Create two read replicas and point the read workload to the read replicas.
- Use an Amazon RDS Multi-AZ DB instance deployment. Point the read workload to the secondary instances in the Multi-AZ pair.
- ✅ Use an Amazon RDS Multi-AZ DB cluster deployment Point the read workload to the reader endpoint.
✨ 关键词:
1️⃣ ❌ -> 4️⃣ ✅
- Single-AZ Instance - The RPO with an Amazon RDS Single-AZ instance is typically 5 minutes.
- Multi-AZ instance - The amount of time it takes for failover is usually 1–2 minutes.
- Multi-AZ DB cluster - The Multi-AZ DB cluster combines automatic failover with two readable standby instances and provides up to 2x faster commit latencies and automated failovers, typically under 35 seconds.
4️⃣ 集群只需要最长 35 的灾难恢复时间,因此最符合。
👨👨👦👦 社区讨论:A - multi-az instance : failover takes between 60-120 sec
D - multi-az cluster: failover around 35 sec
十三、SFTP service
A company runs a highly available SFTP service. The SFTP service uses two Amazon EC2 Linux instances that run with elastic IP addresses to accept traffic from trusted IP sources on the internet. The SFTP service is backed by shared storage that is attached to the instances. User accounts are created and managed as Linux users in the SFTP servers.
The company wants a serverless option that provides high IOPS performance and highly configurable security. The company also wants to maintain control over user permissions.
Which solution will meet these requirements?
- Create an encrypted Amazon Elastic Block Store (Amazon EBS) volume. Create an AWS Transfer Family SFTP service with a public endpoint that allows only trusted IP addresses. Attach the EBS volume to the SFTP service endpoint. Grant users access to the SFTP service.
- ✅ Create an encrypted Amazon Elastic File System (Amazon EFS) volume. Create an AWS Transfer Family SFTP service with elastic IP addresses and a VPC endpoint that has internet-facing access. Attach a security group to the endpoint that allows only trusted IP addresses. Attach the EFS volume to the SFTP service endpoint. Grant users access to the SFTP service.
- Create an Amazon S3 bucket with default encryption enabled. Create an AWS Transfer Family SFTP service with a public endpoint that allows only trusted IP addresses. Attach the S3 bucket to the SFTP service endpoint. Grant users access to the SFTP service.
- ❌ Create an Amazon S3 bucket with default encryption enabled. Create an AWS Transfer Family SFTP service with a VPC endpoint that has internal access in a private subnet. Attach a security group that allows only trusted IP addresses. Attach the S3 bucket to the SFTP service endpoint. Grant users access to the SFTP service.
✨ 关键词:
4️⃣ ❌ -> 2️⃣ ✅
💡 解析:替换共享存储方案,同时保留对用户权限的控制。
这里理解错了,以为是需要找到可以挂载到EC2上的存储方案,其实要求的是替换掉通过EC2实现的 SFTP 服务。
由于 4️⃣ 的配置会导致其只能在内网访问,因此选 2️⃣。
👨👨👦👦 社区讨论:Not A - Transfer Family canj’t use EBS
B - Possible and meets requirement
Not C - S3 doesn’t guarantee “high IOPS performance”; also there is no “public endpoint that allows only trusted IP addresses” (you can assign a Security Group to a public endpoint but that is not mentioned here)
Not D - Endpoint would be in private subnet, not accessible from Internet at all
十四、Identity-based Policy
A solutions architect wants to use the following JSON text as an identity-based policy to grant specific permissions:

Which IAM principals can the solutions architect attach this policy to? (Choose two.)
- ✅ Role
- ✅ Group
- Organization
- ❌ Amazon Elastic Container Service (Amazon ECS) resource
- ❌ Amazon EC2 resource
✨ 关键词:identity-based
4️⃣ 5️⃣ ❌ -> 1️⃣ 2️⃣ ✅
💡 解析:题目总已经明确了是基于身份的策略,因此选 1️⃣ 和 2️⃣。
👨👨👦👦 社区讨论:identity-based policy used for role and group
十五、15,000 IOPS stroage
A company uses high block storage capacity to runs its workloads on premises. The company’s daily peak input and output transactions per second are not more than 15,000 IOPS. The company wants to migrate the workloads to Amazon EC2 and to provision disk performance independent of storage capacity.
Which Amazon Elastic Block Store (Amazon EBS) volume type will meet these requirements MOST cost-effectively?
- GP2 volume type
- ❌ io2 volume type
- ✅ GP3 volume type
- io1 volume type
✨ 关键词:
2️⃣ ❌ -> 3️⃣ ✅
💡 解析:看下答案中各存储的 IOPS 和价格:Migrate your Amazon EBS volumes from gp2 to gp3 and save up to 20% on costs
类型 Max IOPS/volume Price gp3 16,000 $0.08/GiB-month gp2 16,000 $0.10/GiB-month io1 64,000 $0.125/GiB-month io2 256,000 $0.125/GiB-month gp 系列已经能达到 IOPS 需求,选 gp3 更便宜。
👨👨👦👦 社区讨论:Both GP2 and GP3 has max IOPS 16000 but GP3 is cost effective.
https://aws.amazon.com/blogs/storage/migrate-your-amazon-ebs-volumes-from-gp2-to-gp3-and-save-up-to-20-on-costs/
十六、Scoreboard in near-real time
A company has developed a new video game as a web application. The application is in a three-tier architecture in a VPC with Amazon RDS for MySQL in the database layer. Several players will compete concurrently online. The game’s developers want to display a top-10 scoreboard in near-real time and offer the ability to stop and restore the game while preserving the current scores.
What should a solutions architect do to meet these requirements?
- Set up an Amazon ElastiCache for Memcached cluster to cache the scores for the web application to display.
- ✅ Set up an Amazon ElastiCache for Redis cluster to compute and cache the scores for the web application to display.
- Place an Amazon CloudFront distribution in front of the web application to cache the scoreboard in a section of the application.
- Create a read replica on Amazon RDS for MySQL to run queries to compute the scoreboard and serve the read traffic to the web application.
✨ 关键词:top-10 scoreboard in near-real time
2️⃣ ✅
💡 解析:希望能够近乎实时地显示前10名的计分板,并提供在保留当前分数的情况下停止和恢复游戏的功能。
1️⃣ 和 2️⃣ 理论上都能解决问题,但是Amazon ElastiCache for Redis是官方推荐的解决方案:Build a real-time gaming leaderboard with Amazon ElastiCache for Redis
Amazon ElastiCache for Redis更强调拥有排序的特性,适合该场景:与 Redis OSS 兼容的 Amazon ElastiCache游戏排行榜
借助 Amazon ElastiCache,用户可以轻松创建实时游戏排行榜。可直接使用 Redis OSS 有序集数据结构,此结构实现了元素的唯一性,同时又可维护按元素分数排序的列表。创建实时排序表像用户分数在每次更改后进行更新一样简单。您也可以使用时间戳作为分数,使用有序集处理时间序列数据。社区还有人提到了
ElastiCache for Memcached不是持久的,没有备份和还原功能,这是真的,并且也应该是本题不选它的原因之一。
👨👨👦👦 社区讨论:Real-time gaming leaderboards are easy to create with Amazon ElastiCache for Redis. Just use the Redis Sorted Set data structure, which provides uniqueness of elements while maintaining the list sorted by their scores. Creating a real-time ranked list is as simple as updating a user’s score each time it changes. You can also use Sorted Sets to handle time series data by using timestamps as the score.
https://aws.amazon.com/cn/elasticache/redis/#:~:text=ElastiCache%20for%20Redis.-,Gaming,-Leaderboards
十七、DR in another region
A company hosts its application in the AWS Cloud. The application runs on Amazon EC2 instances behind an Elastic Load Balancer in an Auto Scaling group and with an Amazon DynamoDB table. The company wants to ensure the application can be made available in anotherAWS Region with minimal downtime.
What should a solutions architect do to meet these requirements with the LEAST amount of downtime?
- ✅ Create an Auto Scaling group and a load balancer in the disaster recovery Region. Configure the DynamoDB table as a global table. Configure DNS failover to point to the new disaster recovery Region’s load balancer.
- Create an AWS CloudFormation template to create EC2 instances, load balancers, and DynamoDB tables to be launched when needed Configure DNS failover to point to the new disaster recovery Region’s load balancer.
- ❌ Create an AWS CloudFormation template to create EC2 instances and a load balancer to be launched when needed. Configure the DynamoDB table as a global table. Configure DNS failover to point to the new disaster recovery Region’s load balancer.
- Create an Auto Scaling group and load balancer in the disaster recovery Region. Configure the DynamoDB table as a global table. Create an Amazon CloudWatch alarm to trigger an AWS Lambda function that updates Amazon Route 53 pointing to the disaster recovery load balancer.
✨ 关键词:minimal downtime
3️⃣ ❌ -> 1️⃣ ✅
💡 解析:3️⃣ 创建了一个
CloudFormation模板用以容灾,理论上也可以实现短时内在另一个区域启动相同的架构。
但是没有 1️⃣ 一直启动着相同架构来的快。
👨👨👦👦 社区讨论:With the LEAST amount of downtime = A
Cost effective = C , but risky some of EC2 types/capacity not available in Region at the time, when need to switch to DR
十八、Reserved DB instance
A company moved its on-premises PostgreSQL database to an Amazon RDS for PostgreSQL DB instance. The company successfully launched a new product. The workload on the database has increased. The company wants to accommodate the larger workload without adding infrastructure.
Which solution will meet these requirements MOST cost-effectively?
- ✅ Buy reserved DB instances for the total workload. Make the Amazon RDS for PostgreSQL DB instance larger.
- Make the Amazon RDS for PostgreSQL DB instance a Multi-AZ DB instance.
- Buy reserved DB instances for the total workload. Add another Amazon RDS for PostgreSQL DB instance.
- ❌ Make the Amazon RDS for PostgreSQL DB instance an on-demand DB instance.
✨ 关键词:
4️⃣ ❌ -> 1️⃣ ✅
💡 解析:工作负载已经增加了 (increased),并且之后架构不再增加了,可以使用预留实例了。
👨👨👦👦 社区讨论:“without adding infrastructure” means scaling vertically and choosing larger instance.
”MOST cost-effectively” reserved instances
十九、Add CIDR block to VPC
A solutions architect configured a VPC that has a small range of IP addresses. The number of Amazon EC2 instances that are in the VPC is increasing, and there is an insufficient number of IP addresses for future workloads.
Which solution resolves this issue with the LEAST operational overhead?
- ✅ Add an additional IPv4 CIDR block to increase the number of IP addresses and create additional subnets in the VPC. Create new resources in the new subnets by using the new CIDR.
- ❌ Create a second VPC with additional subnets. Use a peering connection to connect the second VPC with the first VPC Update the routes and create new resources in the subnets of the second VPC.
- Use AWS Transit Gateway to add a transit gateway and connect a second VPC with the first VPUpdate the routes of the transit gateway and VPCs. Create new resources in the subnets of the second VPC.
- Create a second VPC. Create a Site-to-Site VPN connection between the first VPC and the second VPC by using a VPN-hosted solution on Amazon EC2 and a virtual private gateway. Update the route between VPCs to the traffic through the VPN. Create new resources in the subnets of the second VPC.
✨ 关键词:
2️⃣ ❌ -> 1️⃣ ✅
- 默认情况下,您的 VPC 可以最多有 5 个 IPv4 CIDR 块和 5 个 IPv6 CIDR 块,但此限额可调整。
- 如果您的 VPC 关联了多个 IPv4 CIDR 块,则可以取消一个 IPv4 CIDR 块与 VPC 的关联。您不能将主 IPv4 CIDR 块取消关联。您只能将整个 CIDR 块取消关联;不能将 CIDR 块的子集或 CIDR 块的合并范围取消关联。必须首先删除 CIDR 块中的所有子网。
拓展下子网的 CIDR 也支持修改:
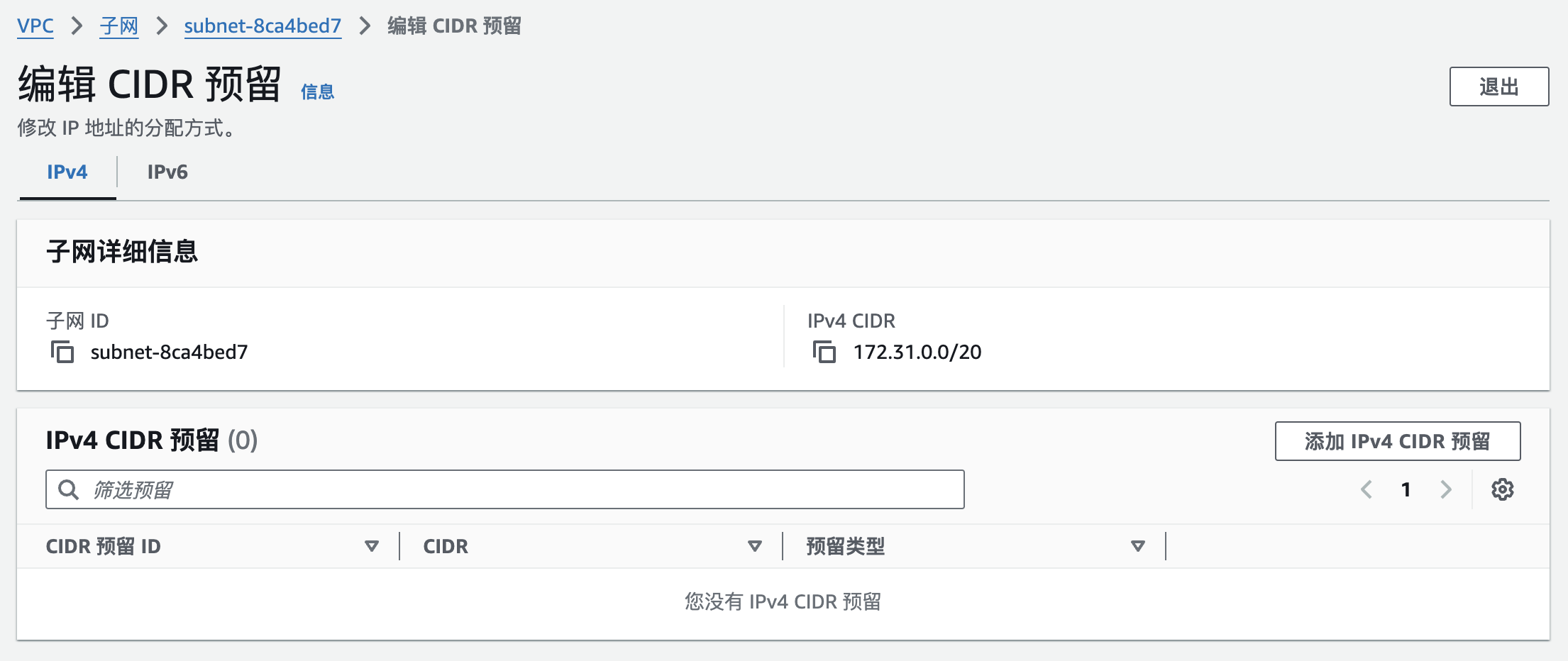
👨👨👦👦 社区讨论:A is correct: You assign a single CIDR IP address range as the primary CIDR block when you create a VPC and can add up to four secondary CIDR blocks after creation of the VPC.
二十、Rebuild DB instance
A company used an Amazon RDS for MySQL DB instance during application testing. Before terminating the DB instance at the end of the test cycle, a solutions architect created two backups. The solutions architect created the first backup by using the mysqldump utility to create a database dump. The solutions architect created the second backup by enabling the final DB snapshot option on RDS termination.
The company is now planning for a new test cycle and wants to create a new DB instance from the most recent backup. The company has chosen a MySQL-compatible edition of Amazon Aurora to host the DB instance.
Which solutions will create the new DB instance? (Choose two.)
- ✅ Import the RDS snapshot directly into Aurora.
- Upload the RDS snapshot to Amazon S3. Then import the RDS snapshot into Aurora.
- ✅ Upload the database dump to Amazon S3. Then import the database dump into Aurora.
- Use AWS Database Migration Service (AWS DMS) to import the RDS snapshot into Aurora.
- ❌ Upload the database dump to Amazon S3. Then use AWS Database Migration Service (AWS DMS) to import the database dump into Aurora.
✨ 关键词:
1️⃣ 5️⃣ ❌ -> 1️⃣ 3️⃣ ✅
💡 解析:将数据从外部 MySQL 数据库迁移到 Amazon Aurora MySQL 数据库集群
如果数据库支持 InnoDB 或 MyISAM 表空间,则可以使用以下选项将数据迁移到 Amazon Aurora MySQL 数据库集群:
- 您可以使用 mysqldump 实用程序创建数据的转储,然后将该数据导入现有的 Amazon Aurora MySQL 数据库集群。
- 您可以将完整备份文件和增量备份文件从数据库复制到 Amazon S3 桶,然后从这些文件还原到 Amazon Aurora MySQL 数据库集群。该选项可能比使用 mysqldump 迁移数据要快得多。
👨👨👦👦 社区讨论:A because the snapshot is already stored in AWS.
C because you dont need a migration tool going from MySQL to MySQL. You would use the MySQL utility.
二十一、Connect from local to AWS
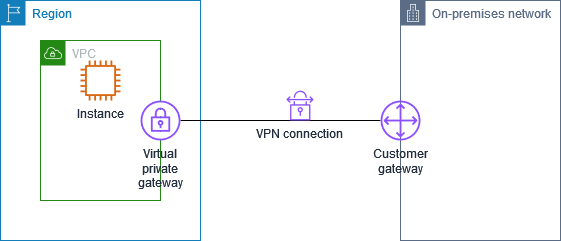
A company has two VPCs named Management and Production. The Management VPC uses VPNs through a customer gateway to connect to a single device in the data center. The Production VPC uses a virtual private gateway with two attached AWS Direct Connect connections. The Management and Production VPCs both use a single VPC peering connection to allow communication between the applications.
What should a solutions architect do to mitigate any single point of failure in this architecture?
- Add a set of VPNs between the Management and Production VPCs.
- ❌ Add a second virtual private gateway and attach it to the Management VPC.
- ✅ Add a second set of VPNs to the Management VPC from a second customer gateway device.
- Add a second VPC peering connection between the Management VPC and the Production VPC.
✨ 关键词:
2️⃣ ❌ -> 3️⃣ ✅
💡 解析:一个公司有两个
VPC,分别是 Management 和 Production。管理VPC通过客户网关使用 VPN 连接到数据中心的单个设备。生产 VPC 使用一个附加了 2 个AWS Direct Connect连接的虚拟私有网关。管理VPC和生产VPC都使用单个VPC对等连接,实现应用之间的通信。需要防止单点故障。
首先VPC对等连接不会出问题,然后 2 条AWS Direct Connect连接也保证了高可用,只有与管理VPC间的连接存在风险。
虚拟专用网关 (virtual private gateway) 是在 AWS 侧的,而客户网关是在本地的,两者通过 VPN 或者基于
AWS Direct Connect的 VPN 隧道进行连接。
所以在本题场景下,2️⃣ 的操作(在管理VPC新增一个虚拟专用网关)是没法让连接更加高可用的,只有增加一条本地到管理VPC的连接才行,只能选 3️⃣。
👨👨👦👦 社区讨论:C is the correct option to mitigate the single point of failure.
The Management VPC currently has a single VPN connection through one customer gateway device. This is a single point of failure.
Adding a second set of VPN connections from the Management VPC to a second customer gateway device provides redundancy and eliminates this single point of failure.