前言
Proxmox VE 是我目前本地服务的底层虚拟化平台,上面跑着若干 LXC 容器和 KVM 虚拟机。
随着需要监控的服务越来越多,趁着这次统一接入 Prometheus + Grafana 的机会,也顺带把 PVE 本身的节点状态、虚拟机资源占用以及存储用量一并纳入监控。
方案概述
- 搭建
Prometheus+Grafana监控平台(已完成) - 在 PVE 中创建只读 API 用户并分配权限
- 使用 Python3 安装并启动
pve-exporter - 配置
Prometheus抓取pve-exporter的指标 - 在
Grafana中导入 Dashboard 展示 PVE 指标
操作步骤
一、搭建 Prometheus + Grafana 监控平台
直接参考我的另一篇文章:搭建 Prometheus + Grafana 监控平台并使用 Node Exporter 监测服务器状态
二、在 PVE 中创建只读 API 用户并分配权限
pve-exporter 通过调用 PVE 的 REST API 来采集指标,因此需要在 PVE 中先创建一个专用的只读用户。
1、创建用户
在 PVE Web UI 中依次进入 Datacenter > Users > Add:
- User name:
prometheus - Realm:
Proxmox VE authentication server(即pve) - Password:设置一个强密码并记录下来
或者直接在 PVE 宿主机的 Shell 中执行:
pveum user add prometheus@pve --password <your-password>2、创建只读角色并分配权限
# 创建一个名为 pve-exporter 的角色,仅赋予审计权限
pveum role add pve-exporter --privs "VM.Audit Sys.Audit Datastore.Audit Pool.Audit"
# 将该角色赋予刚才创建的用户,作用范围为整个 Datacenter(/)
pveum acl modify / --user prometheus@pve --role pve-exporter确认权限配置正确:
pveum acl list能看到 prometheus@pve 对应的条目即可。
三、使用 Python3 安装并启动 pve-exporter
pve-exporter 的官方仓库:prometheus-pve/prometheus-pve-exporter
这里通过 pip3 直接安装,并使用 systemd 进行管理。
1、安装 pve-exporter
PVE 基于 Debian,新版系统对 pip 有”externally managed”限制,直接 pip install 会报错。这里使用虚拟环境来隔离安装:
# 安装 venv 模块(如果还没有的话)
apt-get install -y python3-venv
# 创建虚拟环境
python3 -m venv /opt/pve_exporter
# 在虚拟环境中安装 pve-exporter
/opt/pve_exporter/bin/pip install prometheus-pve-exporter安装完成后,验证可执行文件是否存在:
/opt/pve_exporter/bin/pve_exporter --help2、创建配置文件
mkdir -vp /etc/pve_exporter
nano /etc/pve_exporter/pve.ymldefault:
user: prometheus@pve
password: <your-password>
# 如果你的 PVE 使用自签名证书,将此项设置为 false
verify_ssl: false这里的
default是模块名,与后续 Prometheus 抓取配置中的module参数对应。
如果你有多套 PVE 环境,可以在此文件中添加多个模块分别配置。
配置文件权限收紧,避免密码泄露:
chmod 600 /etc/pve_exporter/pve.yml3、创建 systemd 服务
nano /etc/systemd/system/pve_exporter.service[Unit]
Description=Prometheus PVE Exporter
After=network-online.target
Wants=network-online.target
[Service]
Type=simple
ExecStart=/opt/pve_exporter/bin/pve_exporter --config.file /etc/pve_exporter/pve.yml
Restart=on-failure
RestartSec=5s
[Install]
WantedBy=multi-user.target重新加载 systemd 并启动服务:
systemctl daemon-reload
systemctl start pve_exporter
systemctl enable pve_exporter验证服务状态:
systemctl status pve_exporter验证 pve-exporter 是否正常采集到数据:
# 将 192.168.1.10 替换为你 PVE 宿主机的实际 IP
curl "http://localhost:9221/pve?target=192.168.1.10&module=default&cluster=1&node=1"如果能看到大量 pve_* 格式的文本指标,说明 pve-exporter 已经能够正常采集 PVE 的数据了。
四、配置 Prometheus 抓取 pve-exporter 的指标
pve-exporter 的工作方式与普通 Exporter 略有不同:它通过 HTTP 参数接收目标 PVE 地址,再代理去调用 PVE API,因此 Prometheus 这边需要做一些 relabel 处理。
编辑 Prometheus 的配置文件:
nano /opt/prometheus/prometheus.yml在 scrape_configs: 下添加如下配置:
- job_name: 'pve_exporter'
metrics_path: /pve
params:
module: [default]
cluster: ['1']
node: ['1']
static_configs:
- targets:
# 填写 PVE 宿主机的 IP 地址
- 192.168.1.10
relabel_configs:
# 将 target 地址作为请求参数传给 pve-exporter
- source_labels: [__address__]
target_label: __param_target
# 将 target 参数的值作为 instance 标签
- source_labels: [__param_target]
target_label: instance
# 将实际的抓取地址替换为 pve-exporter 的地址
- target_label: __address__
replacement: <pve-exporter-server-ip>:9221
cluster: ['1']:采集集群级别的指标(节点列表、资源汇总等)。node: ['1']:采集每个节点的详细指标(CPU、内存、磁盘、网络等)。__address__中填写的是 PVE 宿主机的 IP,而replacement中填写的是运行pve-exporter容器的主机 IP。- 如果有多台 PVE 节点,在
targets中追加各节点的 IP 即可,pve-exporter会分别处理。
重新加载 Prometheus 的配置:
curl -X POST http://localhost:9090/-/reload检查目标状态:
curl -s http://localhost:9090/api/v1/targets | python3 -m json.tool | grep -E '"job"|"health"'看到 "health":"up" 说明 Prometheus 已经成功拉取到 PVE 的指标数据了。
五、在 Grafana 中导入 Dashboard 展示 PVE 指标
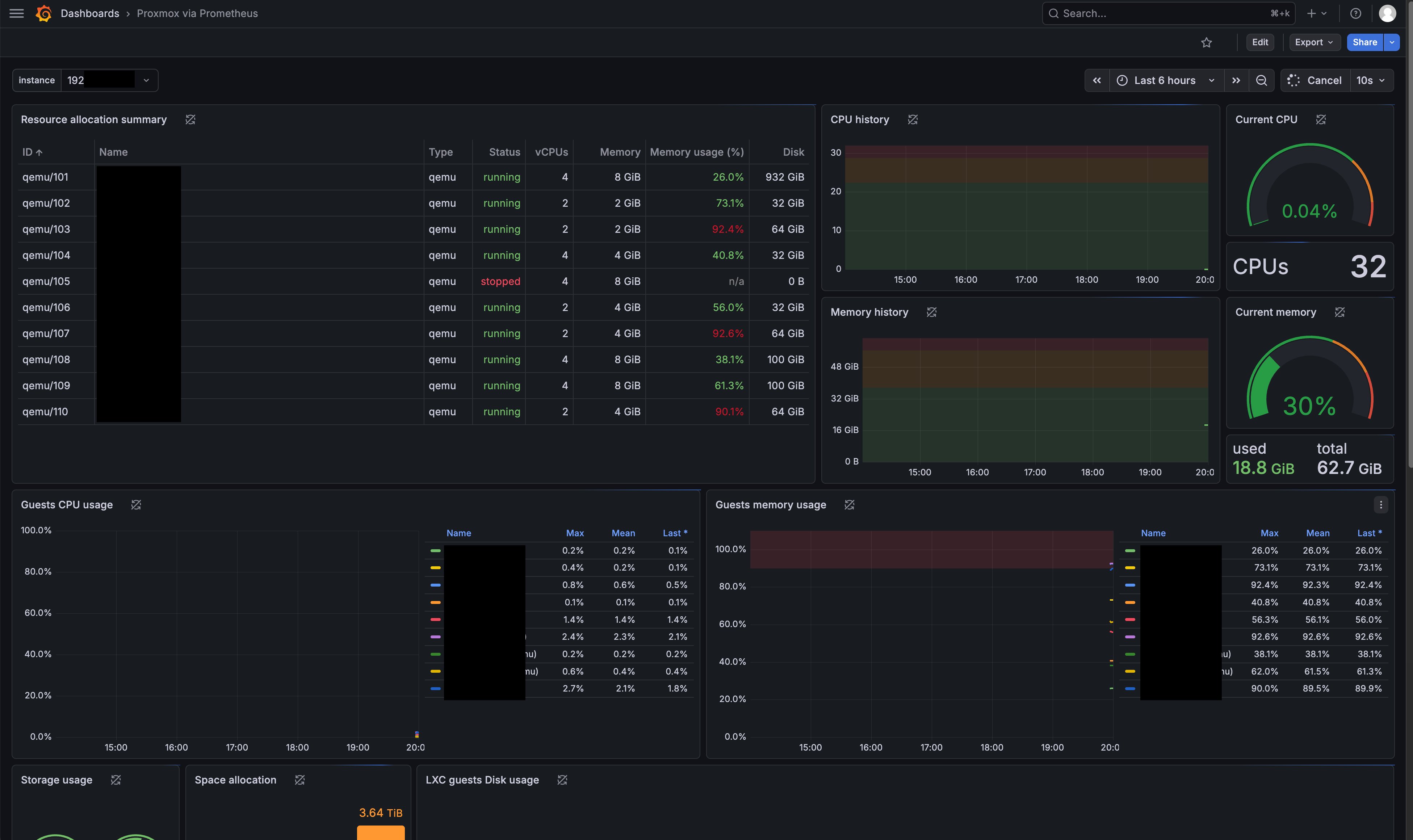
在 Dashboards > Import dashboard 中输入 Dashboard ID 10347,或直接使用 URL Proxmox via Prometheus (ID: 10347):
导入后选择已配置好的 Prometheus 数据源,保存即可。
Dashboard 中可以看到:
- 各节点的 CPU、内存、磁盘 I/O、网络流量
- 虚拟机和 LXC 容器的资源占用汇总
- 存储池使用情况
结束。