前言
之前的数据一直是直接走 PostgreSQL 批量写入的,随着爬虫节点越来越多,高峰期的写入冲突和堆积开始影响到其他业务。
这次打算引入 Kafka 作为中间的消息缓冲层,在家里的一台内网虚拟机上单机跑起来,所有外部访问(生产者、消费者、Prometheus + Grafana、公网 Kafka UI)统一走 Tailscale kafka.ts.net 私网域名接入。
方案概述
- 使用 Docker 单机部署
Kafka(KRaft 模式) - 创建业务所需的 Topic
- 大数据量的主要数据管道
- 小数据量的辅助消息管道
- 连通性与性能测试
- 针对 4H 8G 的资源进行性能调优
- 使用
Prometheus+Grafana对Kafka进行监控- 为
Kafka容器挂载JMX Exporter抓取 broker / JVM 指标 - 部署
kafka-exporter抓取 Topic 和 Consumer Lag 指标 - 配置
Prometheus抓取两套指标 - 在
Grafana中导入 Dashboard
- 为
- 在公网服务器上部署
Kafka UI并通过Tailscale反向连接- 编写
Kafka UI的docker-compose.yml - 验证能通过
Tailscale连接到内网Kafka - 配置
Caddy反向代理以公网访问
- 编写
部署架构
这次涉及到 Kafka 部署节点、已有的监控节点以及公网 UI 入口三处,统一列一下(所有节点都已加入 Tailscale):
| 角色 | 主机名 | 公网 IP | 内网 IP | Tailscale 域名 | 备注 |
|---|---|---|---|---|---|
| Kafka 单机节点 | kafka | - | 192.168.2.10 | kafka.ts.net | 4H 8G 400GB SSD,运行 Kafka 容器、JMX Exporter、kafka-exporter |
统一走 Tailscale 域名的好处是:无论客户端物理上在哪个网络、哪个机房,Kafka 的连接串都只有一个,后续机器搬家、网段变更、甚至整套环境迁移都不用改任何客户端配置。
我的
Tailscale是通过自建的Headscale管理的,部署过程参考:部署 Headscale 和 DERP 以通过 Tailscale 实现无公网 IP 服务器之间的组网。
业务上一开始只规划 2 个 Topic,以后有需要再加:
main-stream:主要数据管道,峰值 6 万条/s,单条消息很小只有几百字节。message-stream:辅助消息管道,峰值 100 条/s,单条消息较大平均 10 KB,主要用来传输一些日志、错误信息等。
消费者数量暂定为 3 ~ 5 个,Topic 的分区数要 ≥ 消费者数量,否则多出来的消费者会空转。
操作步骤
一、在 pve-cz-kafka 上使用 Docker 单机部署 Kafka
Docker 的安装可以参考我的另一篇文章:Ubuntu 20.04 从官方源安装最新的 Docker
从 Kafka 3.3 开始,KRaft 模式成为生产可用;而 Kafka 4.0 更是彻底移除了 Zookeeper,官方镜像也已经默认以 KRaft 模式启动。
部署前,需要先生成一个用于标识这个 KRaft 集群的唯一 ID:
docker run --rm apache/kafka:latest /opt/kafka/bin/kafka-storage.sh random-uuid输出类似:
MkU3OEVBNTcwNTJENDM2Qk如果一时拿不到镜像,也可以任意生成一个 22 位的 Base64 字符串,例如:
openssl rand -hex 16 | head -c 22
创建工作目录并准备持久化目录:
mkdir -vp /opt/kafka/data # 持久化 Kafka 的日志数据
chown -R 1000:1000 /opt/kafka/data
cd /opt/kafka
nano docker-compose.yml不设置目录权限的话,Kafka 容器内的
kafka用户(UID 1000)是没有权限写入数据目录的,启动后会一直重启失败:kafka | Bootstrap metadata: BootstrapMetadata(records=[ApiMessageAndVersion(FeatureLevelRecord(name=‘metadata.version’, featureLevel=29) at version 0), ApiMessageAndVersion(FeatureLevelRecord(name=‘eligible.leader.replicas.version’, featureLevel=1) at version 0), ApiMessageAndVersion(FeatureLevelRecord(name=‘group.version’, featureLevel=1) at version 0), ApiMessageAndVersion(FeatureLevelRecord(name=‘share.version’, featureLevel=1) at version 0), ApiMessageAndVersion(FeatureLevelRecord(name=‘streams.version’, featureLevel=1) at version 0), ApiMessageAndVersion(FeatureLevelRecord(name=‘transaction.version’, featureLevel=2) at version 0)], metadataVersionLevel=29, source=format command) Formatting metadata directory /var/lib/kafka/data with metadata.version 4.2-IV1. Error while writing meta.properties file /var/lib/kafka/data: java.nio.file.AccessDeniedException: /var/lib/kafka/data/bootstrap.checkpoint.tmp
version: "3.8"
services:
kafka:
image: apache/kafka:latest
container_name: kafka
restart: always
ports:
# 9092 绑到 0.0.0.0 后,Tailscale 接口自然也能访问
# 所有外部客户端(生产者 / 消费者 / Prometheus / Kafka UI)全部走 Tailscale 域名 + 9092
- "9092:9092"
volumes:
- /opt/kafka/data:/var/lib/kafka/data
- /etc/timezone:/etc/timezone:ro
- /etc/localtime:/etc/localtime:ro
environment:
# ====== KRaft 模式核心配置 ======
# 当前节点既是 broker 又是 controller,单机部署必须这样配
KAFKA_PROCESS_ROLES: "broker,controller"
KAFKA_NODE_ID: 1
# 把上一步生成的集群 ID 填到这里
CLUSTER_ID: "MkU3OEVBNTcwNTJENDM2Qk"
# 由于是单机,controller quorum 里只有自己
KAFKA_CONTROLLER_QUORUM_VOTERS: "1@localhost:9093"
KAFKA_CONTROLLER_LISTENER_NAMES: "CONTROLLER"
# ====== 监听器 ======
# EXTERNAL 暴露在 :9092,广播为 Tailscale 域名,供所有外部客户端接入
# DOCKER 仅 docker 容器内网络使用(主要是同一 compose 里的 kafka-exporter),不对宿主机暴露端口
# CONTROLLER 仅容器内使用
KAFKA_LISTENERS: "EXTERNAL://0.0.0.0:9092,DOCKER://0.0.0.0:29092,CONTROLLER://0.0.0.0:9093"
KAFKA_ADVERTISED_LISTENERS: "EXTERNAL://kafka.ts.net:9092,DOCKER://kafka:29092"
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: "EXTERNAL:PLAINTEXT,DOCKER:PLAINTEXT,CONTROLLER:PLAINTEXT"
# 单机部署没有实际的 broker 间通信,随便指一个已经存在的即可
KAFKA_INTER_BROKER_LISTENER_NAME: "DOCKER"
# ====== 数据目录 ======
KAFKA_LOG_DIRS: "/var/lib/kafka/data"
# ====== 单机必备的几个默认值 ======
# 单节点不可能有 3 副本,全部降到 1
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_DEFAULT_REPLICATION_FACTOR: 1
KAFKA_MIN_INSYNC_REPLICAS: 1
# 自动创建 Topic 关掉,Topic 都由我们手动精确建
KAFKA_AUTO_CREATE_TOPICS_ENABLE: "false"
# 默认数据保留 7 天
KAFKA_LOG_RETENTION_HOURS: 168
# ====== 针对 4H 8G 的 JVM 堆限制 ======
# 默认是 1G,这里给到 3G
# 剩余留给页缓存(Kafka 的读写大量依赖 Linux page cache)
KAFKA_HEAP_OPTS: "-Xms3g -Xmx3g"启动:
docker compose up -d
docker compose logs -f kafka看到类似 Kafka Server started 的输出,就说明启动成功了。
关于
advertised.listeners的坑:Kafka 客户端首次连接 broker 时拿到的是 broker 广播出来的地址,而不是你连的那个地址。
所以EXTERNAL监听必须广播为kafka.ts.net:9092,否则客户端第一次握手拿到的会是kafka:29092这种容器内地址从而连不上。
进入容器内,先列一下有没有 Topic,应该是空的:
docker exec -it kafka /opt/kafka/bin/kafka-topics.sh \
--bootstrap-server localhost:9092 \
--list再看下集群元信息:
docker exec -it kafka /opt/kafka/bin/kafka-metadata-quorum.sh \
--bootstrap-server localhost:9092 describe --status只要能打印出 LeaderId: 1 之类的信息,说明 KRaft 控制器已经正常选举完毕。
二、创建业务所需的 Topic
所有命令都在宿主机上直接
docker exec进去执行即可。
1、大数据量的主要数据管道
这是流量大头,6 万条每秒,必须让分区数 ≥ 消费者最大数量,这里直接开到 6 个分区(对应最多 6 个消费者并发消费):
docker exec -it kafka /opt/kafka/bin/kafka-topics.sh \
--bootstrap-server localhost:9092 \
--create \
--topic main-stream \
--partitions 6 \
--replication-factor 1 \
--config retention.ms=259200000 \
--config segment.bytes=1073741824 \
--config compression.type=lz4一些参数说明:
retention.ms=259200000:保留 3 天。按 6 万条每秒、每条 512 字节估算,3 天约 7.5TB,显然不现实。
这里只是给一个上限,真正靠下面的retention.bytes或segment.bytes滚动删除来控制磁盘占用。segment.bytes=1073741824:每 1GB 一个 segment,便于滚动清理。compression.type=lz4:价格数据一般是重复字段多的 JSON,lz4压缩比和速度平衡最好,实测能压到原始的 30% 左右。
再单独设置一下磁盘保留上限(总共给这个 Topic 最多 200GB,分到 6 个分区就是每分区约为 33GB):
docker exec -it kafka /opt/kafka/bin/kafka-configs.sh \
--bootstrap-server localhost:9092 \
--alter \
--entity-type topics --entity-name main-stream \
--add-config retention.bytes=354334801922、小数据量的辅助消息管道
这个管道流量很低,一天也就几万条,开 2 个分区就够了:
docker exec -it kafka /opt/kafka/bin/kafka-topics.sh \
--bootstrap-server localhost:9092 \
--create \
--topic message-stream \
--partitions 2 \
--replication-factor 1 \
--config retention.ms=604800000 \
--config compression.type=lz4保留 7 天,流量小就不设置
retention.bytes了。
创建完确认下:
docker exec -it kafka /opt/kafka/bin/kafka-topics.sh \
--bootstrap-server localhost:9092 \
--describe可以看到每个 Topic 的分区、副本、ISR 情况。
三、连通性与性能测试
从 Tailscale 私网内其他机器上测试生产和消费,验证 Kafka 的吞吐和稳定性,同时也能测试一下 Tailscale 链路的延迟和稳定性。
Kafka 自带压测工具,验证一下 6 万条每秒的峰值是不是真的能抗住:
docker run --rm apache/kafka:latest /opt/kafka/bin/kafka-producer-perf-test.sh \
--topic main-stream \
--num-records 600000 \
--record-size 512 \
--throughput 60000 \
--producer-props bootstrap.servers=kafka.ts.net:9092 acks=1 compression.type=lz4观察输出中的 records/sec 和 avg latency,如果能稳定达到 60000 条/s 且平均延迟在几十毫秒以内,就完全满足需求。
我实测下来,在这台 4H 8G 400GB SSD 上稳定跑 60000 条/s、单条 512B、lz4 压缩,发送吞吐量稳定在
29.25 MB/sec,CPU 和磁盘利用率完全在安全区间内。
走 Tailscale 链路的整体平均延迟仅为7.86ms(其中 P50 中位数延迟低至2ms,P95 延迟约60ms),这个网络性能和直连内网几乎没有体感差异,对于消息队列这种异步场景来说表现非常优秀。

四、针对 4H 8G 的资源进行性能调优
上面已经在 docker-compose.yml 里把 JVM 堆直接写到了 3g。除此之外,再补充两个容易被忽略的点。
1、预留充足的 page cache
Kafka 的高吞吐本质上依赖操作系统的 page cache,而不是 JVM 堆。
4H 8G 机器,3G 给 JVM 堆,剩下的 5G 一定要留给系统做 page cache,尽量避免在这台机器上跑其他占用内存的服务。
free -havailable 列至少要有 3G 以上,才算合格。
2、调大文件描述符上限
Kafka 每个分区都会对应多个文件(segment、index 等),默认 1024 的 ulimit 很容易被打满。
编辑 /etc/security/limits.conf:
sudo nano /etc/security/limits.conf* soft nofile 65535
* hard nofile 65535之后断开 当前 SSH 会话重新登录,并重启 Docker 服务让改动生效:
sudo systemctl restart docker五、使用 Prometheus + Grafana 对 Kafka 进行监控
搭建
Prometheus + Grafana监控平台可以参考:搭建 Prometheus + Grafana 监控平台并使用 Node Exporter 监测服务器状态
监控 Kafka 的指标主要分两块,缺一不可:
- Broker 自身的 JVM / 吞吐 / 副本等底层指标 → 通过
JMX Exporter(以javaagent方式注入到 Kafka 进程里) - Topic / 消费者组 / Consumer Lag 等业务指标 → 通过
kafka-exporter(独立容器,以普通 Kafka 客户端身份拉取)
1、为 Kafka 容器挂载 JMX Exporter
先在宿主机上下载 JMX Exporter 的 javaagent jar 和 Kafka 专用配置(jmx_exporter Releases):
# 这里的 jmx-exporter 是个 jar 包,就不按照我放置 Prometheus Exporter 的习惯(/usr/local/bin)放了,直接放在 Kafka 的目录里,挂载到容器里更方便
mkdir -vp /opt/kafka/jmx-exporter
cd /opt/kafka/jmx-exporter
# 截止我写文章的时间点最新版本是 1.5.0
wget https://github.com/prometheus/jmx_exporter/releases/download/1.5.0/jmx_prometheus_javaagent-1.5.0.jar -O jmx_prometheus_javaagent.jar
# 官方维护的 Kafka 抓取规则
wget https://raw.githubusercontent.com/prometheus/jmx_exporter/refs/heads/main/examples/kafka-2_0_0.yml -O kafka.yml然后修改 /opt/kafka/docker-compose.yml,在 kafka 服务下新增挂载、端口和 KAFKA_OPTS:
ports:
- "9092:9092"
- "9101:9101" # 新增:JMX Exporter 暴露的 metrics 端口(供 Prometheus 通过 Tailscale 抓取)
volumes:
- /opt/kafka/data:/var/lib/kafka/data
- /opt/kafka/jmx-exporter:/opt/jmx-exporter:ro # 新增:挂载 javaagent
- /etc/timezone:/etc/timezone:ro
- /etc/localtime:/etc/localtime:ro
environment:
# ... 原有配置保持不变 ...
# 新增:以 javaagent 方式注入 JMX Exporter,直接把指标暴露在 :9101
KAFKA_OPTS: "-javaagent:/opt/jmx-exporter/jmx_prometheus_javaagent.jar=9101:/opt/jmx-exporter/kafka.yml"重启 Kafka 容器让 javaagent 生效:
cd /opt/kafka
docker compose up -d等容器完全启动后,验证指标端口:
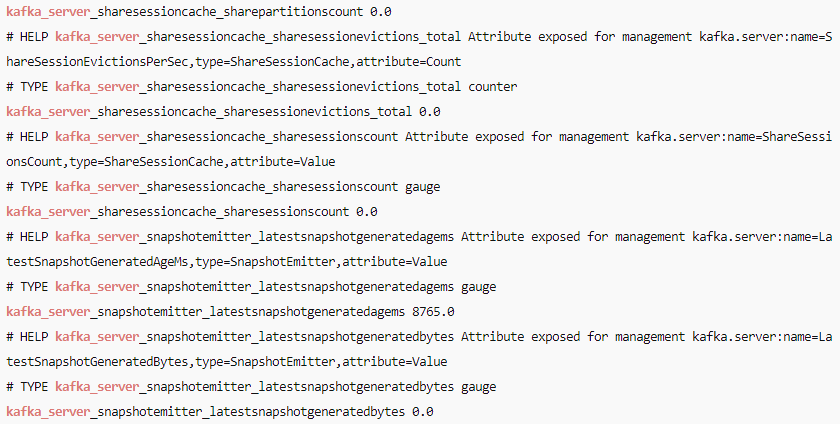
curl -s http://localhost:9101/metrics | grep kafka_server看到一堆 kafka_server_brokertopicmetrics_... 开头的指标就说明 broker 指标已经暴露成功:
2、部署 kafka-exporter 抓取 Topic 和 Consumer Lag 指标
在同一个 docker-compose.yml 里追加 kafka-exporter 服务。
它和 Kafka 在同一个 docker 网络,不需要走 Tailscale:
kafka-exporter:
image: danielqsj/kafka-exporter:latest
container_name: kafka-exporter
restart: always
depends_on:
- kafka
command:
# 走容器网络内的 DOCKER listener 连 Kafka,零延迟、零损耗
- --kafka.server=kafka:29092
# Kafka 4.x 的 API 版本,默认是旧版本会有兼容性提示
- --kafka.version=3.7.0
ports:
- "9308:9308"启动并验证:
docker compose up -d kafka-exportercurl -s http://localhost:9308/metrics | grep kafka_topic_partitions能看到 main-stream、message-stream 两个 Topic 的分区指标,说明 kafka-exporter 已经连上 Kafka 并在正常抓取。
3、配置 Prometheus 抓取两套指标
编辑 Prometheus 配置文件,增加两个抓取 job,目标地址统一用 Tailscale 域名:
nano /opt/prometheus/prometheus.yml - job_name: 'kafka-jmx'
static_configs:
- targets:
- 'kafka.ts.net:9101'
- job_name: 'kafka-exporter'
static_configs:
- targets:
- 'kafka.ts.net:9308'重载配置生效:
curl -X POST http://localhost:9090/-/reload4、在 Grafana 中导入 Dashboard
在 2026/04/24 的时候,社区里还没有完全适配 Kafka 4.x 的 Dashboard,所以暂时用 Kafka Dashboard 顶一下。
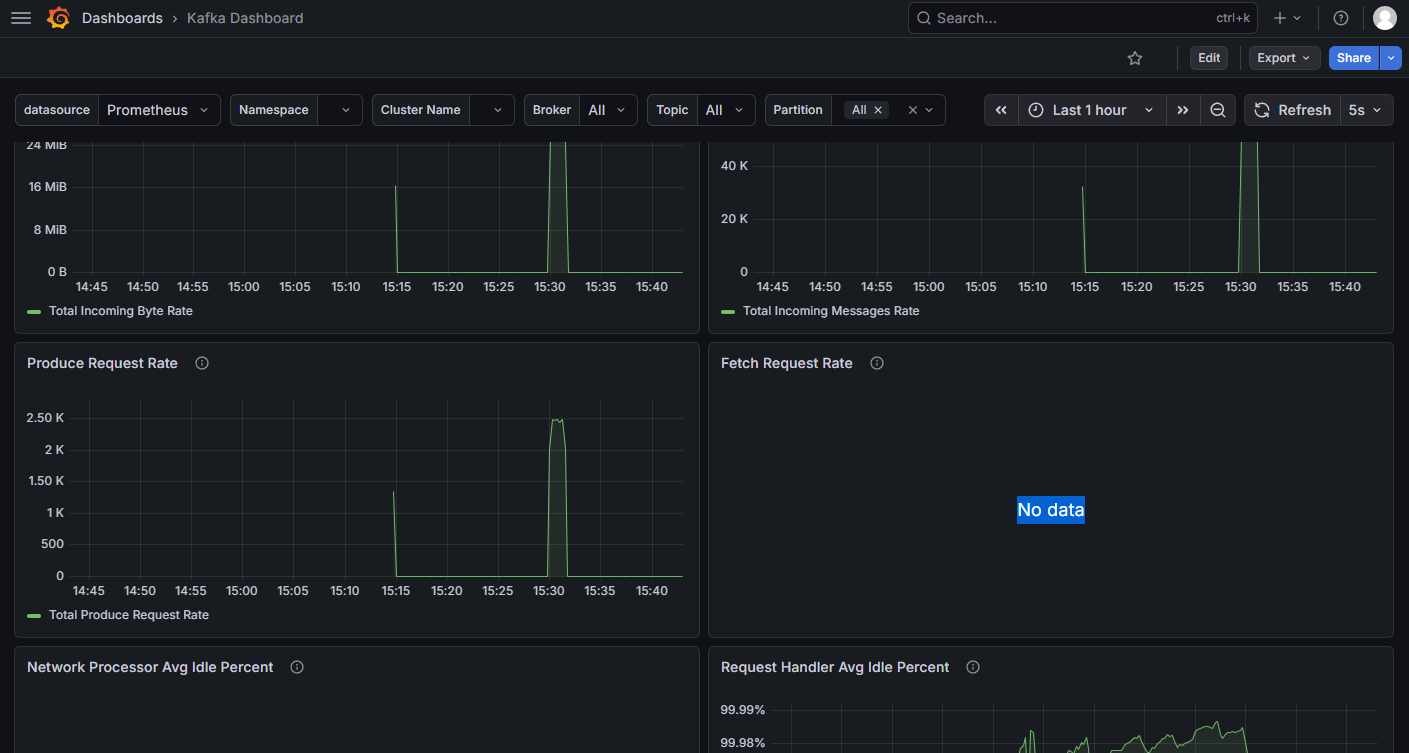
社区常用的下面 2 个 Dashboard 已经不兼容新版本的查询语句了:
- Kafka Exporter Overview (ID: 7589):展示 Topic、分区、Consumer Lag(搭配
kafka-exporter数据源)- Kafka Metrics (ID: 11962):展示 broker 层面的 JVM、吞吐、副本等底层指标(搭配
kafka-jmx数据源)打开会显示无数据,所以不选用。
六、在公网服务器上部署 Kafka UI 并通过 Tailscale 反向连接
UI 我选了社区使用人数最多的 provectus/kafka-ui,部署在另一台已经加入 Tailscale 网络的公网服务器 tencent-gz-master 上。
1、编写 Kafka UI 的 docker-compose.yml
mkdir -vp /opt/kafka-ui
cd /opt/kafka-ui
nano docker-compose.ymlversion: "3.8"
services:
kafka-ui:
image: provectuslabs/kafka-ui:latest
container_name: kafka-ui
restart: always
ports:
# 只绑到本地环回,完全由 Caddy 反代出去,不直接暴露到公网
- "127.0.0.1:8080:8080"
environment:
KAFKA_CLUSTERS_0_NAME: pve-cz-kafka
# ===== 关键:走 Tailscale 域名反向连接内网 Kafka 的 EXTERNAL listener =====
# 和生产者 / 消费者 / Prometheus 用的是完全同一个接入点
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka.ts.net:9092
# 顺带把 JMX 指标也接入 UI,在 UI 上直接看到 broker 性能图表
KAFKA_CLUSTERS_0_METRICS_PORT: 9101
KAFKA_CLUSTERS_0_METRICS_TYPE: PROMETHEUS
# 如果担心 UI 被误操作删 Topic,可以打开只读模式
# KAFKA_CLUSTERS_0_READONLY: "true"
# ===== 启用简单的登录认证,避免公网被扫到后直接裸奔 =====
AUTH_TYPE: LOGIN_FORM
SPRING_SECURITY_USER_NAME: admin
SPRING_SECURITY_USER_PASSWORD: <your_strong_password>启动:
docker compose up -d2、验证能通过 Tailscale 连接到内网 Kafka
没有持续报 Connection to node -1 could not be established 之类的错误,就说明 UI 已经连上后端 Kafka:
docker logs -f kafka-ui3、配置 Caddy 反向代理以公网访问
在 /etc/caddy/Caddyfile 中新增:
sudo nano /etc/caddy/Caddyfilekafka.example.com {
reverse_proxy 127.0.0.1:8080 {
header_up X-Real-IP {remote_host}
header_up X-Forwarded-For {remote_host}
header_up X-Forwarded-Proto {scheme}
}
}重载:
sudo systemctl reload caddy现在访问 https://kafka.example.com,就会看到 Kafka UI 的登录页,用刚才设置的用户名和密码登录:
结束。