前言
一些玩具爬虫想稍微写的简单点、好维护点,同时和生产环境的爬虫系统分开,用 Crawlab 来做统一管理吧。
方案概述
- 安装 Docker 环境
- 使用官方的
docker-compose.yaml单机部署 Crawlab - 将测试爬虫上传至 Crawlab
- 运行爬虫后查看状态并下载结果
操作步骤
一、安装 Docker 环境
参考:Ubuntu 20.04 从官方源安装最新的 Docker
二、使用官方的 docker-compose.yaml 单机部署 Crawlab
官方文档:单节点部署
docker-compose.yaml 文件内容中,MongoDB 由于将端口暴露给了宿主机,因此账号密码需要修改下:
version: '3.3'
services:
master:
image: crawlabteam/crawlab
container_name: crawlab_master
restart: always
environment:
CRAWLAB_NODE_MASTER: "Y" # Y: 主节点
CRAWLAB_MONGO_HOST: "mongo" # mongo host address. 在 Docker-Compose 网络中,直接引用 service 名称
CRAWLAB_MONGO_PORT: "27017" # mongo port
CRAWLAB_MONGO_DB: "crawlab" # mongo database
CRAWLAB_MONGO_USERNAME: "username" # mongo username
CRAWLAB_MONGO_PASSWORD: "password" # mongo password
CRAWLAB_MONGO_AUTHSOURCE: "admin" # mongo auth source
volumes:
- "/opt/.crawlab/master:/root/.crawlab" # 持久化 crawlab 元数据
- "/opt/crawlab/master:/data" # 持久化 crawlab 数据
- "/var/crawlab/log:/var/log/crawlab" # 持久化 crawlab 任务日志
ports:
- "8080:8080" # 开放 api 端口
depends_on:
- mongo
mongo:
image: mongo:4.2
restart: always
environment:
MONGO_INITDB_ROOT_USERNAME: "username" # mongo username
MONGO_INITDB_ROOT_PASSWORD: "password" # mongo password
volumes:
- "/opt/crawlab/mongo/data/db:/data/db" # 持久化 mongo 数据
ports:
- "27017:27017" # 开放 mongo 端口到宿主机拉取镜像:
docker compose pull如果镜像拉取有问题,可以参考:自建 Docker Registry 镜像加速服务
启动容器:
docker compose up -d启动完成后,访问 8080 端口就能看到页面了:

用户名和密码都是 admin,登录后前往 My Settings 处修改。
三、将测试爬虫上传至 Crawlab
官方文档:创建爬虫
Scrapy 爬虫样例在:senjianlu/scrapy-example
下载后解压,得到这样的目录结构:
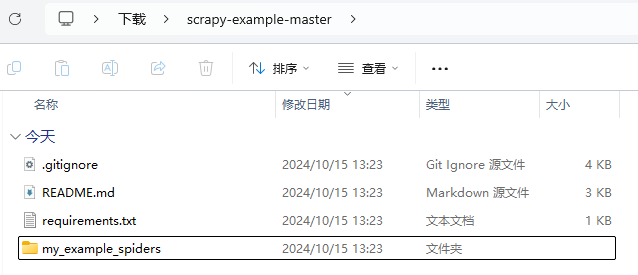
scrapy-example
├── .gitignore
├── README.md
├── requirements.txt
└── my_example_spiders
├── scrapy.cfg
└── my_example_spiders
├── __init__.py
├── items.py
├── middlewares.py
├── pipelines.py
├── settings.py
└── spiders
├── __init__.py
└── quotes.py需要上传的是 scrapy-example-master 下面的 my_example_spiders 目录(更上层一点的 my_example_spiders 目录)。
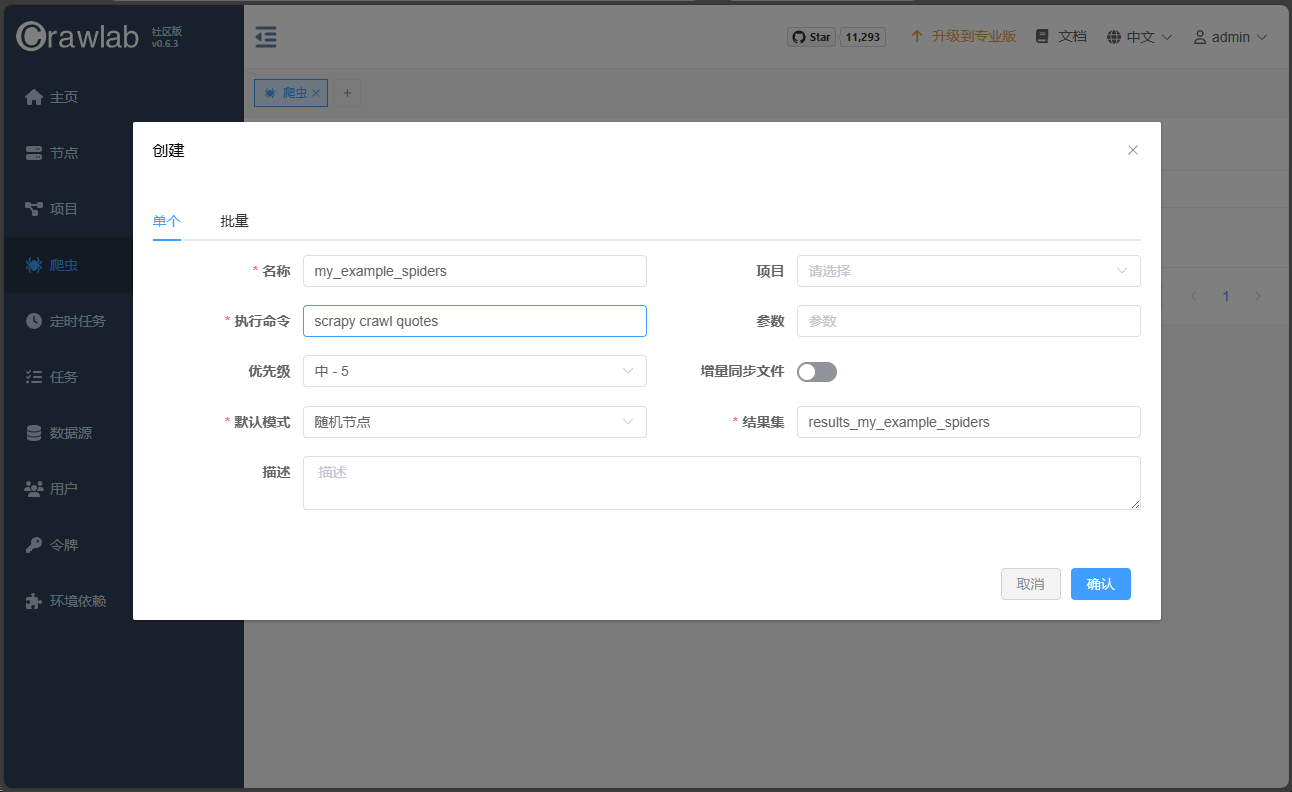
在页面上新建爬虫:
- 名称:
my_example_spiders - 执行命令:
scrapy crawl quotes
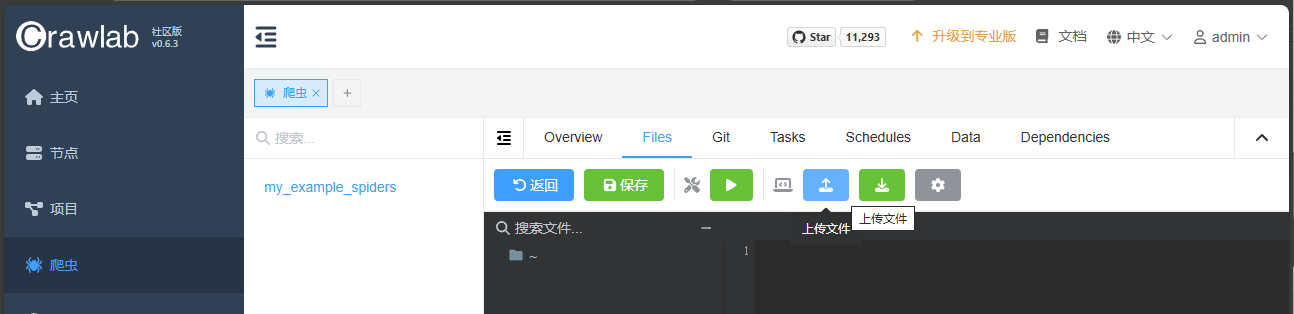
之后进入爬虫,点击上传:
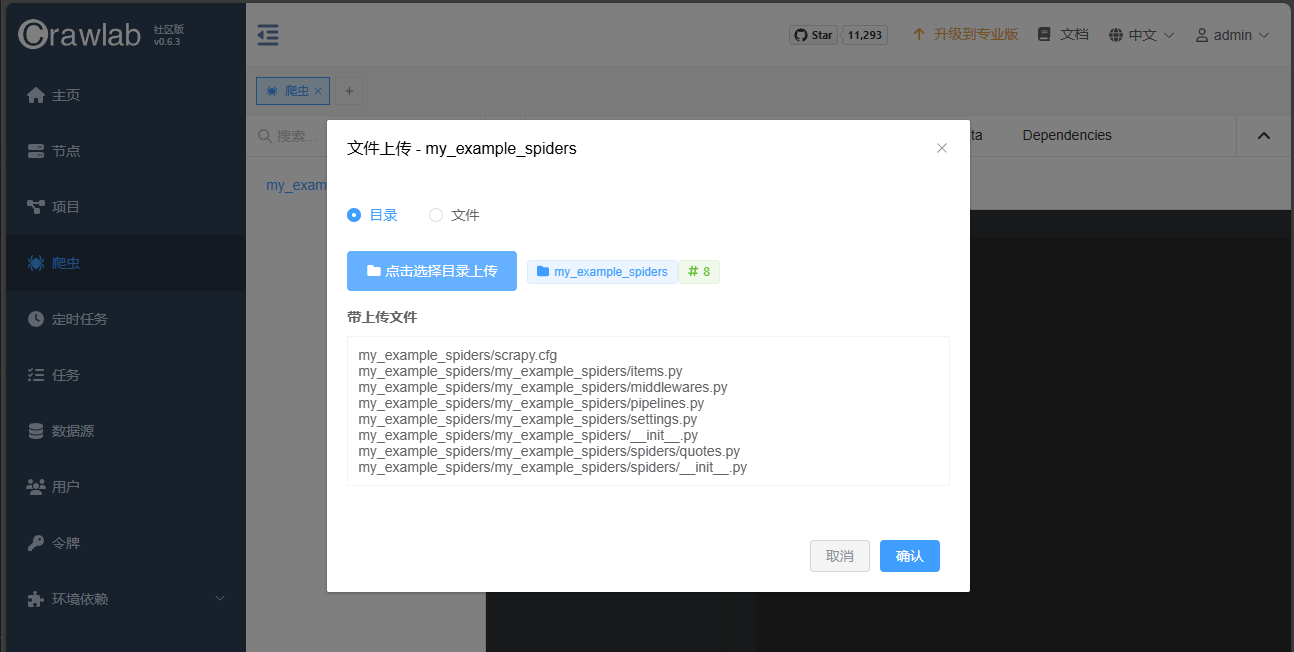
上传成功后,在左侧文件列表中可以双击打开文件:
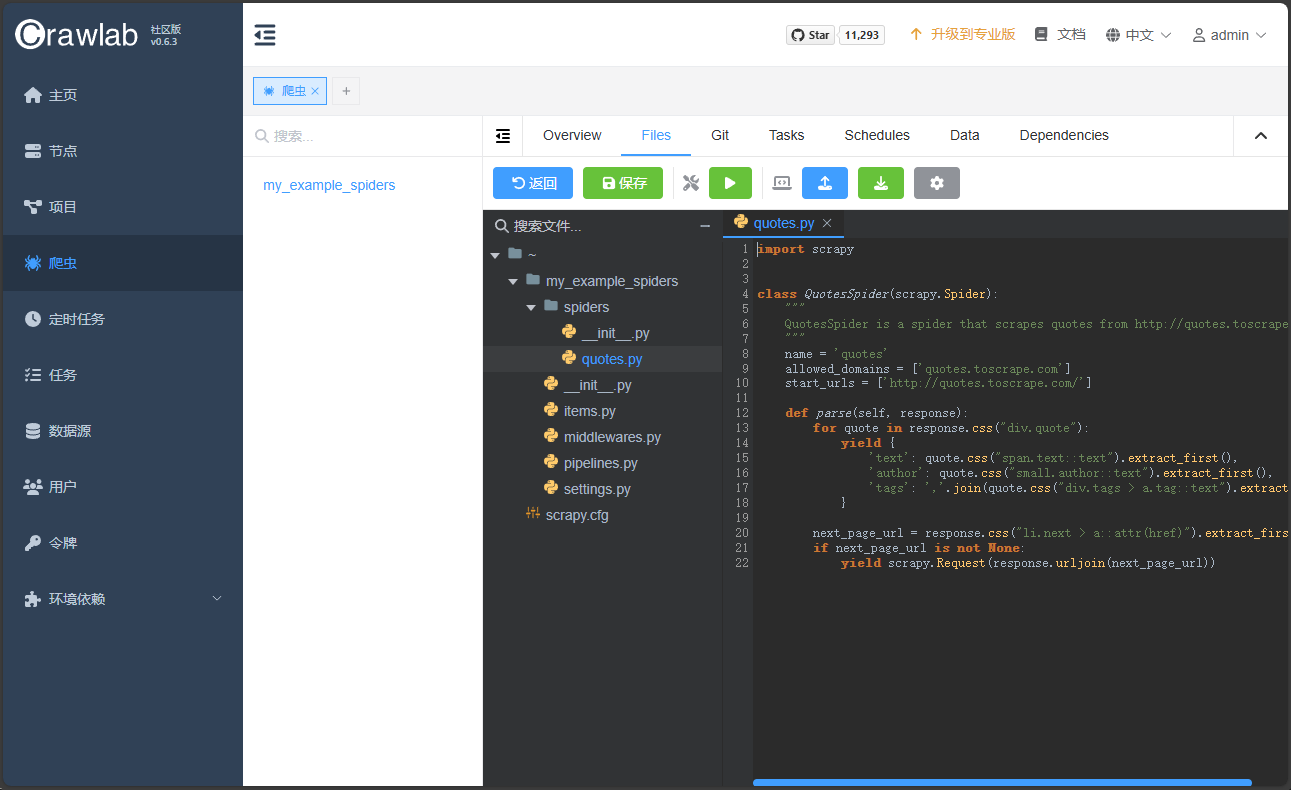
四、运行爬虫后查看状态并下载结果
官方文档:运行爬虫
点击爬虫的运行按钮:

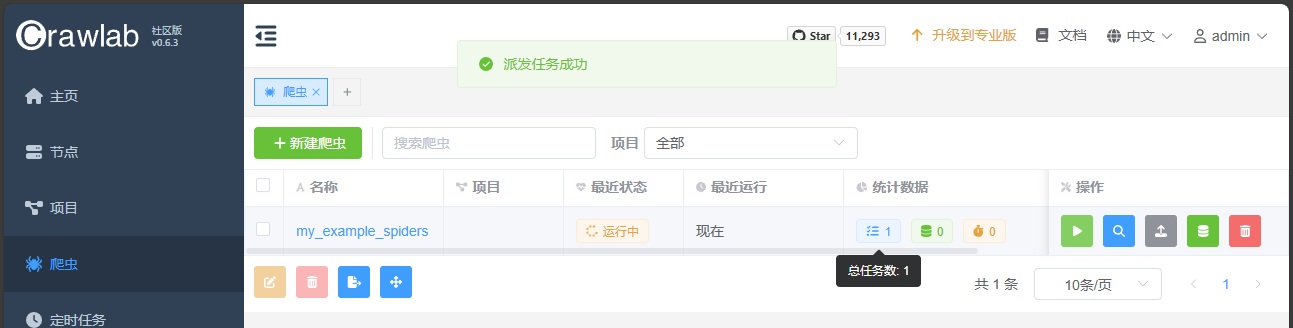
稍等片刻不出以外会成功:

如果出现
File not found或是undefined之类的错误,大概率是你的爬虫目录上传错了。
前往任务菜单,可以找到对应执行的日志:

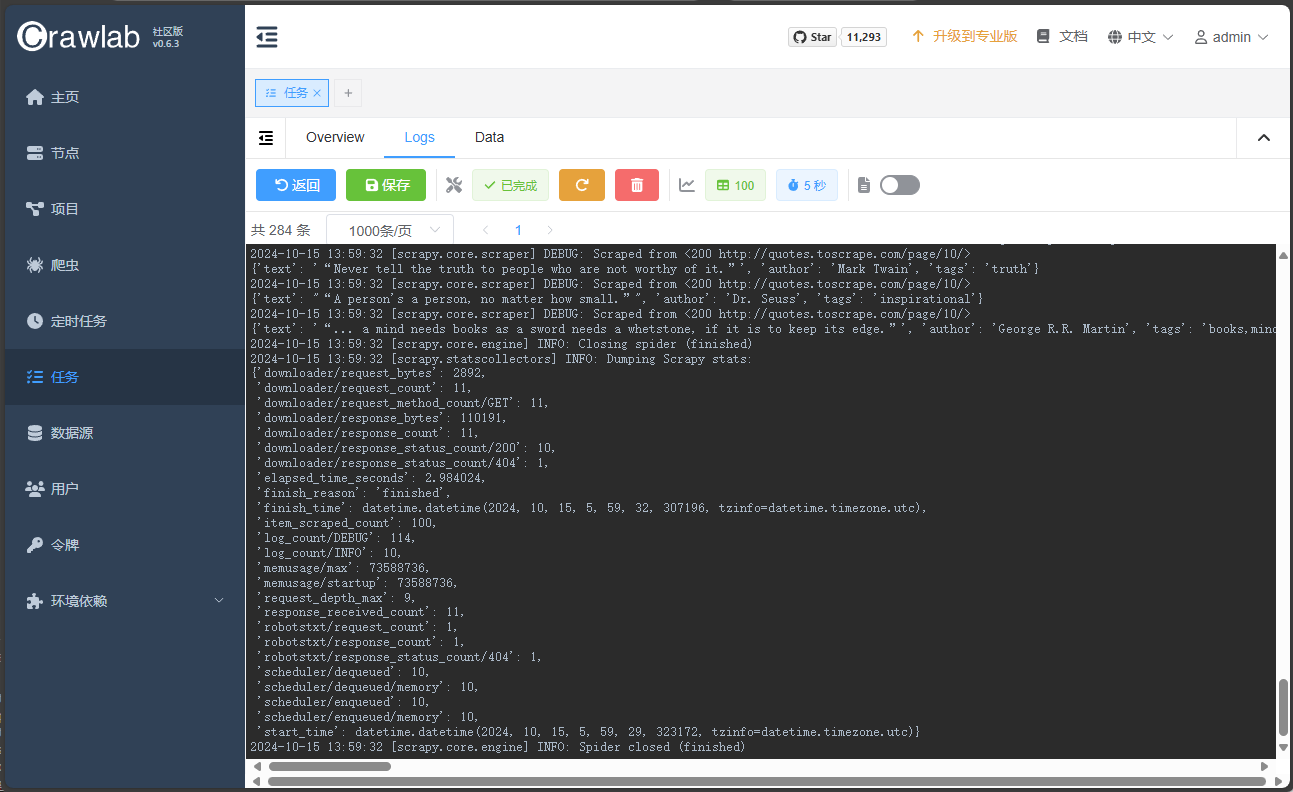
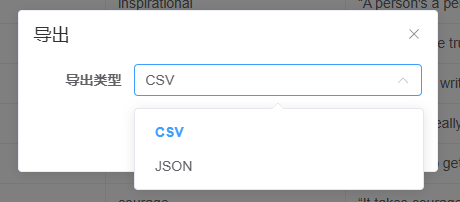
点击数据可以看到相关的爬取结果:

视情况导出:
结束。