来源:Amazon AWS Certified Solutions Architect - Professional SAP-C02 Exam
10 题 (No.18 ~ No.27),仅供自己复习使用。
如果侵权请联系删除。
一、Video categorization application
A company has a web application that allows users to upload short videos. The videos are stored on Amazon EBS volumes and analyzed by custom recognition software for categorization.
The website contains static content that has variable traffic with peaks in certain months. The architecture consists of Amazon EC2 instances running in an Auto Scaling group for the web application and EC2 instances running in an Auto Scaling group to process an Amazon SQS queue. The company wants to re-architect the application to reduce operational overhead using AWS managed services where possible and remove dependencies on third-party software.
Which solution meets these requirements?
- ❌ Use Amazon ECS containers for the web application and Spot instances for the Auto Scaling group that processes the SQS queue. Replace the custom software with Amazon Rekognition to categorize the videos.
- Store the uploaded videos in Amazon EFS and mount the file system to the EC2 instances for the web application. Process the SQS queue with an AWS Lambda function that calls the Amazon Rekognition API to categorize the videos.
- ✅ Host the web application in Amazon S3. Store the uploaded videos in Amazon S3. Use S3 event notification to publish events to the SQS queue. Process the SQS queue with an AWS Lambda function that calls the Amazon Rekognition API to categorize the videos.
- Use AWS Elastic Beanstalk to launch EC2 instances in an Auto Scaling group for the web application and launch a worker environment to process the SQS queue. Replace the custom software with Amazon Rekognition to categorize the videos.
✨ 关键词:
1️⃣ ❌ -> 3️⃣ ✅
💡 解析:这里的问题在于 Web 应用程序是否是全静态的,如果是全静态的话无疑 3️⃣ 就是最佳选择:使用的技术栈都是 AWS 托管的。
👨👨👦👦 社区讨论:This solution meets the requirements by using multiple managed services offered by AWS which can reduce the operational overhead. Hosting the web application in Amazon S3 would make it highlyavailable, scalable and can handle variable traffic.
The uploaded videos can be stored in S3 and processed using S3 event notifications that trigger a Lambda function, which calls the Amazon Rekognition API to categorize the videos.SQS can be used to process the event notificationsand also it is a managed service.
This solution eliminates the need to manage EC2 instances, EBS volumesand the custom software. Additionally, using Lambda function in this case,eliminates the need for managing additional servers to process the SQS queue which will reduce operational overhead.
By using this solution, the company can benefit from the scalability, reliability,and cost-effectiveness that these services offer, which can help to reduce operational overhead and improve the overall performance and security of the application.
二、Serverless Application Deploy
A company has a serverless application comprised of Amazon CloudFront, Amazon API Gateway, and AWS Lambda functions.
The current deployment process of the application code is to create a new version number of the Lambda function and run an AWS CLI script to update. If the new function version has errors, another CLI script reverts by deploying the previous working version of the function. The company would like to decrease the time to deploy new versions of the application logic provided by the Lambda functions, and also reduce the time to detect and revert when errors are identified.
How can this be accomplished?
- Create and deploy nested AWS CloudFormation stacks with the parent stack consisting of the AWS CloudFront distribution and API Gateway, and the child stack containing the Lambda function. For changes to Lambda, create an AWS CloudFormation change set and deploy; if errors are triggered, revert the AWS CloudFormation change set to the previous version.
- ✅ Use AWS SAM and built-in AWS CodeDeploy to deploy the new Lambda version, gradually shift traffic to the new version, and use pre-traffic and post-traffic test functions to verify code. Rollback if Amazon CloudWatch alarms are triggered.
- Refactor the AWS CLI scripts into a single script that deploys the new Lambda version. When deployment is completed, the script tests execute. If errors are detected, revert to the previous Lambda version.
- Create and deploy an AWS CloudFormation stack that consists of a new API Gateway endpoint that references the new Lambda version. Change the CloudFront origin to the new API Gateway endpoint, monitor errors and if detected, change the AWS CloudFront origin to the previous API Gateway endpoint.
✨ 关键词:
2️⃣ ✅
💡 解析:
Lambda的多版本部署问题。
使用 AWS SAM 逐步部署无服务器应用程序AWS Serverless Application Model (AWS SAM) 内置于 CodeDeploy 中,可提供逐步 AWS Lambda 部署。只需几行配置,AWS SAM 即可为您完成以下操作:
- 部署 Lambda 函数的新版本,并自动创建指向新版本的别名。
- 逐步将客户流量转移到新版本,直到您确认它按预期方式运行。如果更新无法正常运行,则可以回滚更改。
- 定义转移流量前和转移流量后的测试函数,来验证新部署的代码是否已正确配置并且您的应用程序是否按预期方式运行。
- 如果触发了 CloudWatch 警报,则会自动回滚部署。
这里需要注意的是,
SAM内置了CodeDeploy,并且它的架构是这样的:
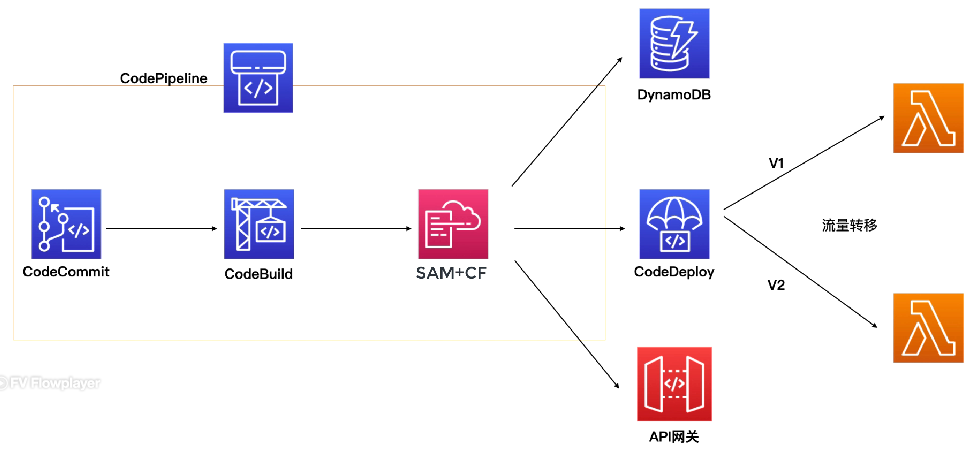
👨👨👦👦 社区讨论:AWS Serverless Application Model (SAM) is a frameworkthat helps you build, test and deploy your serverlessapplications. It uses CloudFormation under the hood, so it isa way to simplify the process of creating, updating,and deploying CloudFormation templates. CodeDeploy isa service that automates code deployments to any instance, including on-premises instancesand Lambda functions.
With AWS SAM you can use the built-in CodeDeploy to deploy new versions of the Lambda function, gradually shift traffic to the new version,and use pre-traffic and post-traffic test functions to verify code.
You can also define CloudWatch Alarms to trigger a rollbackin case of any issues.
Thisallows for a faster and more efficient deployment process,as well asa more reliable rollback process when errorsare identified.This way you can increase the speed of deployment and reduce the time to detect and revert when errorsare identified.
三、Glacier Deep Archive
A company is planning to store a large number of archived documents and make the documents available to employees through the corporate intranet. Employees will access the system by connecting through a client VPN service that is attached to a VPC. The data must not be accessible to the public.
The documents that the company is storing are copies of data that is held on physical media elsewhere. The number of requests will be low. Availability and speed of retrieval are not concerns of the company.
Which solution will meet these requirements at the LOWEST cost?
- ✅ Create an Amazon S3 bucket. Configure the S3 bucket to use the S3 One Zone-Infrequent Access (S3 One Zone-IA) storage class as default. Configure the S3 bucket for website hosting. Create an S3 interface endpoint. Configure the S3 bucket to allow access only through that endpoint.
- Launch an Amazon EC2 instance that runs a web server. Attach an Amazon ElasticFile System (Amazon EFS) file system to store the archived data in the EFS One Zone-Infrequent Access (EFS One Zone-IA) storage class Configure the instance security groups to allow access only from private networks.
- Launch an Amazon EC2 instance that runs a web server Attach an Amazon Elastic Block Store (Amazon EBS) volume to store the archived data. Use the Cold HDD (sc1) volume type. Configure the instance security groups to allow access only from private networks.
- ❌ Create an Amazon S3 bucket. Configure the S3 bucket to use the S3 Glacier Deep Archive storage class as default. Configure the S3 bucket for website hosting. Create an S3 interface endpoint. Configure the S3 bucket to allow access only through that endpoint.
✨ 关键词:
4️⃣ ❌ -> 1️⃣ ✅
💡 解析:这里社区存在整体,4️⃣ 的深度归档显然更便宜,但是它存在检索时间超过 12 的问题,如果使用它托管网页并请求下载的话,一定会出现超时问题,因此 4️⃣ 并不是很好。
而题目中强调了这些数据只是备份,因此可以使用单区存储,显然 1️⃣ 贴合了考点。
👨👨👦👦 社区讨论:A - Glacier Deep Archive can’t be used for web hosting, regardless if the company says retrieval time is no concern.
四、AWS AD
A company is using an on-premises Active Directory service for user authentication. The company wants to use the same authentication service to sign in to the company’s AWS accounts, which are using AWS Organizations. AWS Site-to-Site VPN connectivity already exists between the on-premises environment and all the company’s AWS accounts.
The company’s security policy requires conditional access to the accounts based on user groups and roles. User identities must be managed in a single location.
Which solution will meet these requirements?
- ✅ Configure AWS IAM Identity Center (AWS Single Sign-On) to connect to Active Directory by using SAML 2.0. Enable automatic provisioning by using the System for Cross-domain Identity Management (SCIM) v2.0 protocol. Grant access to the AWS accounts by using attribute-based access controls (ABACs).
- Configure AWS IAM Identity Center (AWS Single Sign-On) by using IAM Identity Center as an identity source. Enable automatic provisioning by using the System for Cross-domain Identity Management (SCIM) v2.0 protocol. Grant access to the AWS accounts by using IAM Identity Center permission sets.
- In one of the company’s AWS accounts, configure AWS Identity and Access Management (IAM) to use a SAML 2.0 identity provider. Provision IAM users that are mapped to the federated users. Grant access that corresponds to appropriate groups in Active Directory. Grant access to the required AWS accounts by using cross-account IAM users.
- In one of the company’s AWS accounts, configure AWS Identity and Access Management (IAM) to use an OpenID Connect (OIDC) identity provider. Provision IAM roles that grant access to the AWS account for the federated users that correspond to appropriate groups in Active Directory. Grant access to the required AWS accounts by using cross-account IAM roles.
✨ 关键词:
1️⃣ ✅
💡 解析:本地有
AD,已经架设了Site-to-Site VPN,希望用户凭证在单区进行管理。
👨👨👦👦 社区讨论:Both option C and option A are valid solutions that meet the requirements for the scenario.
ABAC, or attribute-based access control, isa method of granting access to resources based on the attributes of the user, the resource,and the action.Thisallows for fine-grained access control, which can be useful for implementing a security policy that requires conditional access to the accounts based on user groupsand roles.
AWS IAM Identity Center (AWS SSO) allows you to connect to your on-premises Active Directory service using SAML 2.0. With this, you can enable automatic provisioning by using the System for Cross-domain Identity Management (SCIM) v2.0 protocol, which allows for the management of user identities in a single location.
五、API throttling
A software company has deployed an application that consumes a REST API by using Amazon API Gateway, AWS Lambda functions, and an Amazon DynamoDB table. The application is showing an increase in the number of errors during PUT requests. Most of the PUT calls come from a small number of clients that are authenticated with specific API keys.
A solutions architect has identified that a large number of the PUT requests originate from one client. The API is noncritical, and clients can tolerate retries of unsuccessful calls. However, the errors are displayed to customers and are causing damage to the API’s reputation.
What should the solutions architect recommend to improve the customer experience?
- Implement retry logic with exponential backoff and irregular variation in the client application. Ensure that the errors are caught and handled with descriptive error messages.
- ✅ Implement API throttling through a usage plan at the API Gateway level. Ensure that the client application handles code 429 replies without error.
- Turn on API caching to enhance responsiveness for the production stage. Run 10-minute load tests. Verify that the cache capacity is appropriate for the workload.
- Implement reserved concurrency at the Lambda function level to provide the resources that are needed during sudden increases in traffic.
✨ 关键词:
2️⃣ ✅
💡 解析:问题的本质是来自单一客户端的大量请求导致出现大量错误,节流进行控制非常合理。
👨👨👦👦 社区讨论:API throttling isa technique that can be used to control the rate of requests to an API.This can be useful in situations where a small number of clientsare making a large number of requests, which is causing errors. By implementing API throttling through a usage plan at the API Gateway level, the solutionsarchitect can limit the number of requests that a client can make, which will help to reduce the number of errors.
It’s important that the client application handles the code 429 replies without error, this will help to improve the customer experience by reducing the number of errors that are displayed to customers. Additionally, it will prevent the API’s reputation from being damaged by the errors.
六、S3 lazy loading
A company is running a data-intensive application on AWS. The application runs on a cluster of hundreds of Amazon EC2 instances. A shared file system also runs on several EC2 instances that store 200 TB of data. The application reads and modifies the data on the shared file system and generates a report. The job runs once monthly, reads a subset of the files from the shared file system, and takes about 72 hours to complete. The compute instances scale in an Auto Scaling group, but the instances that host the shared file system run continuously. The compute and storage instances are all in the same AWS Region.
A solutions architect needs to reduce costs by replacing the shared file system instances. The file system must provide high performance access to the needed data for the duration of the 72-hour run.
Which solution will provide the LARGEST overall cost reduction while meeting these requirements?
- ✅ Migrate the data from the existing shared file system to an Amazon S3 bucket that uses the S3 Intelligent-Tiering storage class. Before the job runs each month, use Amazon FSx for Lustre to create a new file system with the data from Amazon S3 by using lazy loading. Use the new file system as the shared storage for the duration of the job. Delete the file system when the job is complete.
- Migrate the data from the existing shared file system to a large Amazon Elastic Block Store (Amazon EBS) volume with Multi-Attach enabled. Attach the EBS volume to each of the instances by using a user data script in the Auto Scaling group launch template. Use the EBS volume as the shared storage for the duration of the job. Detach the EBS volume when the job is complete
- ❌ Migrate the data from the existing shared file system to an Amazon S3 bucket that uses the S3 Standard storage class. Before the job runs each month, use Amazon FSx for Lustre to create a new file system with the data from Amazon S3 by using batch loading. Use the new file system as the shared storage for the duration of the job. Delete the file system when the job is complete.
- Migrate the data from the existing shared file system to an Amazon S3 bucket. Before the job runs each month, use AWS Storage Gateway to create a file gateway with the data from Amazon S3. Use the file gateway as the shared storage for the job. Delete the file gateway when the job is complete.
✨ 关键词:
3️⃣ ❌ -> 1️⃣ ✅
💡 解析:Lazy load
当您使用缓存访问链接的 Amazon S3 或 NFS 数据存储库中的数据时,Amazon File Cache 会自动加载元数据(名称、所有权、时间戳和权限)和文件内容(如果缓存中还没有这些内容)。数据存储库中的数据会以文件和目录的形式出现在缓存中。
当您在 DRA 目录中读取或写入文件数据或元数据时,会触发懒加载。如果数据尚未可用,Amazon File Cache 会将数据从链接的数据存储库加载到缓存中。例如,当您打开文件、统计文件或对文件进行元数据更新时,就会触发懒加载。
👨👨👦👦 社区讨论:A: Lazy loading is cost-effective because onlya subset of data is used at every job
B:There are hundreds of EC2 instances using the volume which is not possible (one EBS volume is limited to 16 nitro instances attached)
C: Batching would load too much data
D: storage gateway is used for on premises data access, I don’t know is you can install a gateway in AWS, but Amazon would never advise this
七、Assign Elastic IP addresses to the NLB
A company is developing a new service that will be accessed using TCP on a static port. A solutions architect must ensure that the service is highly available, has redundancy across Availability Zones, and is accessible using the DNS name my.service.com, which is publicly accessible. The service must use fixed address assignments so other companies can add the addresses to their allow lists.
Assuming that resources are deployed in multiple Availability Zones in a single Region, which solution will meet these requirements?
- Create Amazon EC2 instances with an Elastic IP address for each instance. Create a Network Load Balancer (NLB) and expose the static TCP port. Register EC2 instances with the NLB. Create a new name server record set named my.service.com, and assign the Elastic IP addresses of the EC2 instances to the record set. Provide the Elastic IP addresses of the EC2 instances to the other companies to add to their allow lists.
- Create an Amazon ECS cluster and a service definition for the application. Create and assign public IP addresses for the ECS cluster. Create a Network Load Balancer (NLB) and expose the TCP port. Create a target group and assign the ECS cluster name to the NLCreate a new A record set named my.service.com, and assign the public IP addresses of the ECS cluster to the record set. Provide the public IP addresses of the ECS cluster to the other companies to add to their allow lists.
- ✅ Create Amazon EC2 instances for the service. Create one Elastic IP address for each Availability Zone. Create a Network Load Balancer (NLB) and expose the assigned TCP port. Assign the Elastic IP addresses to the NLB for each Availability Zone. Create a target group and register the EC2 instances with the NLB. Create a new A (alias) record set named my.service.com, and assign the NLB DNS name to the record set.
- Create an Amazon ECS cluster and a service definition for the application. Create and assign public IP address for each host in the cluster. Create an Application Load Balancer (ALB) and expose the static TCP port. Create a target group and assign the ECS service definition name to the ALB. Create a new CNAME record set and associate the public IP addresses to the record set. Provide the Elastic IP addresses of the Amazon EC2 instances to the other companies to add to their allow lists.
✨ 关键词:
3️⃣ ✅
💡 解析:ALB 与 NLB 能否绑定弹性 IP
ALB不支持绑定EIP,ALB是会根据业务负载进行扩展的, NLB可以绑定EIP。 解决方式是:
- 将解析托管到 R53,R53 可以将顶级域名解析到 ALB(
ALIAS记录)- 在 Network Load Balancer (NLB) 的目标组中配置 ALB 作为其目标,然后将 EIP 分配给 NLB。
- 使用 NLB, 替换 ALB。
需要注意的是
ALB不支持绑定弹性 IP。
👨👨👦👦 社区讨论:Logical answer : Non http port like TCP should hint to NLB immediately.(ALB does not fit here) Sharing IP address of EC2 is not apt
whether it is from individual EC2 instances or those from ECS cluster.thiseliminates A,B.D, infact the NLB’saddress which stays in front of / associates to ec2 instances need to be shared.So, only solution is C
八、SLA
A company uses an on-premises data analytics platform. The system is highly available in a fully redundant configuration across 12 servers in the company’s data center.
The system runs scheduled jobs, both hourly and daily, in addition to one-time requests from users. Scheduled jobs can take between 20 minutes and 2 hours to finish running and have tight SLAs. The scheduled jobs account for 65% of the system usage. User jobs typically finish running in less than 5 minutes and have no SLA. The user jobs account for 35% of system usage. During system failures, scheduled jobs must continue to meet SLAs. However, user jobs can be delayed.
A solutions architect needs to move the system to Amazon EC2 instances and adopt a consumption-based model to reduce costs with no long-term commitments. The solution must maintain high availability and must not affect the SLAs.
Which solution will meet these requirements MOST cost-effectively?
- Split the 12 instances across two Availability Zones in the chosen AWS Region. Run two instances in each Availability Zone as On-Demand Instances with Capacity Reservations. Run four instances in each Availability Zone as Spot Instances.
- Split the 12 instances across three Availability Zones in the chosen AWS Region. In one of the Availability Zones, run all four instances as On-Demand Instances with Capacity Reservations. Run the remaining instances as Spot Instances.
- Split the 12 instances across three Availability Zones in the chosen AWS Region. Run two instances in each Availability Zone as On-Demand Instances with a Savings Plan. Run two instances in each Availability Zone as Spot Instances.
- ✅ Split the 12 instances across three Availability Zones in the chosen AWS Region. Run three instances in each Availability Zone as On-Demand Instances with Capacity Reservations. Run one instance in each Availability Zone as a Spot Instance.
✨ 关键词:
4️⃣ ✅
💡 解析:公司不想做长期保证因此不选 3️⃣。
👨👨👦👦 社区讨论:Voted D because of the 65% / 35% proportion. C seems to be good but with only 50% instancesavailable we breakthe SLA
九、AWS Secrets Manager RotationSchedule
A security engineer determined that an existing application retrieves credentials to an Amazon RDS for MySQL database from an encrypted file in Amazon S3. For the next version of the application, the security engineer wants to implement the following application design changes to improve security:
The database must use strong, randomly generated passwords stored in a secure AWS managed service.
The application resources must be deployed through AWS CloudFormation.
The application must rotate credentials for the database every 90 days.
A solutions architect will generate a CloudFormation template to deploy the application.
Which resources specified in the CloudFormation template will meet the security engineer’s requirements with the LEAST amount of operational overhead?
- ✅ Generate the database password as a secret resource using AWS Secrets Manager. Create an AWS Lambda function resource to rotate the database password. Specify a Secrets Manager RotationSchedule resource to rotate the database password every 90 days.
- Generate the database password as a SecureString parameter type using AWS Systems Manager Parameter Store. Create an AWS Lambda function resource to rotate the database password. Specify a Parameter Store RotationSchedule resource to rotate the database password every 90 days.
- Generate the database password as a secret resource using AWS Secrets Manager. Create an AWS Lambda function resource to rotate the database password. Create an Amazon EventBridge scheduled rule resource to trigger the Lambda function password rotation every 90 days.
- Generate the database password as a SecureString parameter type using AWS Systems Manager Parameter Store. Specify an AWS AppSync DataSource resource to automatically rotate the database password every 90 days.
✨ 关键词:
1️⃣ ✅
💡 解析:AWS::SecretsManager::RotationSchedule
设置密文的旋转时间表和 Lambda 轮转函数。
{ "Type" : "AWS::SecretsManager::RotationSchedule", "Properties" : { "HostedRotationLambda" : HostedRotationLambda, "RotateImmediatelyOnUpdate" : Boolean, "RotationLambdaARN" : String, "RotationRules" : RotationRules, "SecretId" : String } }
👨👨👦👦 社区讨论:A
https://docs.aws.amazon.com/secretsmanager/latest/userguide/cloudformation.html
Option B is wrong.The ParameterStore::RotationSchedule resource does not exist in CloudFormation.
Option C is wrong. It does not meet the requirement because it does not use CloudFormation.
Option D is wrong.The AWS::AppSync::DataSource resource is what to create data sources for resolvers in AWS AppSync to connect to.
十、API Gateway REST API direct integrations
A company is storing data in several Amazon DynamoDB tables. A solutions architect must use a serverless architecture to make the data accessible publicly through a simple API over HTTPS. The solution must scale automatically in response to demand.
Which solutions meet these requirements? (Choose two.)
- ✅ Create an Amazon API Gateway REST API. Configure this API with direct integrations to DynamoDB by using API Gateway’s AWS integration type.
- Create an Amazon API Gateway HTTP API. Configure this API with direct integrations to Dynamo DB by using API Gateway’s AWS integration type.
- ✅ Create an Amazon API Gateway HTTP API. Configure this API with integrations to AWS Lambda functions that return data from the DynamoDB tables.
- Create an accelerator in AWS Global Accelerator. Configure this accelerator with AWS Lambda@Edge function integrations that return data from the DynamoDB tables.
- Create a Network Load Balancer. Configure listener rules to forward requests to the appropriate AWS Lambda functions.
✨ 关键词:
1️⃣ 3️⃣ ✅
💡 解析:AWS 介绍了使用 REST API 操作
DynamoDB的案例:API Gateway 使用案例使用 API Gateway 创建 REST API
例如,使用 DynamoDB 作为后端,API 开发人员会设置集成请求以便将传入方法请求转发到所选的后端。该设置包括适当 DynamoDB 操作的规范、所需的 IAM 角色和策略以及所需的输入数据转换。后端将结果作为集成响应返回到 API Gateway。
👨👨👦👦 社区讨论:A and C.
API Gateway REST API can invoke DynamoDB directly.
https://docs.aws.amazon.com/apigateway/latest/developerguide/api-gateway-overview-developer-experience.html