来源:Amazon AWS Certified Solutions Architect - Associate SAA-C03 Exam
109 题 (No.481 ~ No.500, 931 ~ 1019) 只记录了 10 道错误或需要注意的题目,仅供自己复习使用。
如果侵权请联系删除。
一、Amazon S3 Glacier 快速检索的耗时
一家公司正在寻找一种能在 AWS 中存储旧新闻片段视频档案的解决方案。该公司需要最大限度地降低成本,而且很少需要恢复这些文件。当需要这些文件时,必须在最多五分钟内提供。
最具成本效益的解决方案是什么?
- ✅ 将视频存档存储在 Amazon S3 Glacier 中,并使用快速检索。
- 将视频存档存储在 Amazon S3 Glacier 中,并使用标准检索。
- ❌ 将视频存档存储在 Amazon S3 Standard-Infrequent Access (S3 Standard-IA)。
- 将视频存档存储在 Amazon S3 One Zone-Infrequent Access(S3 One Zone-IA)中。
3️⃣ ❌ -> 1️⃣ ✅
💡 解析:
Amazon S3 Glacier中各检索模式耗时不同:了解归档检索选项
- 加速 (Expedited)
S3 Glacier Flexible Retrieval或S3 Intelligent-Tiering 归档访问:1 – 5 分钟S3 Glacier Deep Archive或 S3Intelligent-Tiering 深度归档访问:不可用- 标准 (Standard)
S3 Glacier Flexible Retrieval或S3 Intelligent-Tiering 归档访问:1 分钟 – 5 小时S3 Glacier Deep Archive或 S3Intelligent-Tiering 深度归档访问:9 - 12 小时内- 批量 (Bulk)
S3 Glacier Flexible Retrieval或S3 Intelligent-Tiering 归档访问:5 – 12 小时S3 Glacier Deep Archive或 S3Intelligent-Tiering 深度归档访问:48 小时内
二、持续备份 DynamoDB 数据到 S3 存储桶
一家游戏公司使用 Amazon DynamoDB 来存储用户信息,如地理位置、玩家数据和排行榜。该公司需要用最少的编码将连续备份配置到 Amazon S3 存储桶。备份不得影响应用程序的可用性,也不得影响为表定义的读取容量单位 (RCU)。
哪种解决方案能满足这些要求?
- 使用亚马逊 EMR 集群。创建 Apache Hive 作业,将数据备份到亚马逊 S3。
- ✅ 将数据直接从 DynamoDB 导出到亚马逊 S3,并持续备份。打开表的时间点恢复。
- ❌ 配置 Amazon DynamoDB 流。创建一个 AWS Lambda 函数来消费流并将数据导出到亚马逊 S3 存储桶。
- 创建一个 AWS Lambda 函数,定期将数据从数据库表导出到亚马逊 S3。打开表的时间点恢复。
3️⃣ ❌ -> 2️⃣ ✅
💡 解析:将 DynamoDB 数据导出到 Amazon S3:工作方式
DynamoDB 导出到 S3 是一种完全托管式解决方案,用于将您的 DynamoDB 数据大规模导出到 Amazon S3 桶。使用“DynamoDB 导出到 S3”,可以在从时间点故障恢复(PITR)时段内的任何时间,将数据从 Amazon DynamoDB 表导出到 Amazon S3 桶。您需要在表上启用 PITR 才能使用导出功能。借助此功能,您可以使用其它 AWS 服务(如 Athena、AWS Glue、Amazon SageMaker、Amazon EMR 和 AWS Lake Formation)对数据执行分析和复杂的查询。
三、指定组织内可用的 EC2 实例类型
某公司有多个 AWS 账户用于开发工作。一些员工持续使用超大的 Amazon EC2 实例, 导致公司开发账户超出年度预算。公司希
望集中限制在这些账户中创建 AWS 资源。
哪种解决方案能以最少的开发工作量满足这些要求?
- 开发使用经批准的 EC2 创建流程的 AWS 系统管理器模板。使用经批准的系统管理器模板配置 EC2 实例。
- ✅ 使用 AWS 组织将账户组织到组织单位(OU)中。定义并附加服务控制策略(SCP),以控制 EC2 实例类型的使用。
- 配置 Amazon EventBridge 规则,在创建 EC2 实例时调用 AWS Lambda 函数。停止不允许的 EC2 实例类型。
- ❌ 为员工设置 AWS 服务目录产品,以创建允许的 EC2 实例类型。确保员工只能使用服务目录产品部署 EC2 实例。
4️⃣ ❌ -> 2️⃣ ✅
💡 解析:来看下什么是 Service Catalog?
借助 Service Catalog,组织可以创建和管理获准在 AWS 上使用的 IT 服务的目录。这些 IT 服务可谓包罗万象,从虚拟机映像、服务器、软件和数据库,再到完整的多层应用程序架构等。
Service Catalog 允许组织集中管理通常部署的 IT 服务,并帮助组织实现一致的监管和满足合规性要求。最终用户可在遵循组织设定约束的情况下快速部署他们所需的已获得批准的 IT 服务。
看起来似乎可以实现。
再来看下SCP:Amazon Elastic Compute Cloud(Amazon EC2)的示例 SCP需要 Amazon EC2 实例以使用特定类型
借助此 SCP,任何不使用t2.micro实例类型启动的实例都将被拒绝。{ "Version": "2012-10-17", "Statement": [ { "Sid": "RequireMicroInstanceType", "Effect": "Deny", "Action": "ec2:RunInstances", "Resource": [ "arn:aws:ec2:*:*:instance/*" ], "Condition": { "StringNotEquals": { "ec2:InstanceType": "t2.micro" } } } ] }有典型案例,因此选 2️⃣ 肯定没错。
四、允许特定 IP 访问 API Gateway
某公司正在 AWS 云中开发一个应用程序。该应用程序的 HTTP API 包含以下关键信息在亚马逊 API 网关中发布。关键信息必须只能从属于公司内部网络的有限一组受信任 IP 地址访问。
哪种解决方案能满足这些要求?
- 设置 API Gateway 私有集成,以限制对一组预定义 IP 地址的访问。
- ✅ 为应用程序接口创建资源策略,拒绝访问任何未明确允许的 IP 地址。
- 在专用子网中直接部署 API。创建网络 ACL。设置规则,允许来自特定 IP 地址的流量。
- ❌ 修改附加到 API Gateway 的安全组,只允许来自受信任 IP 地址的入站流量。
4️⃣ ❌ -> 2️⃣ ✅
💡 解析:如何只允许特定的 IP 地址访问我的 API Gateway REST API?
在 Resource Policy (资源策略) 文本框中,粘贴以下示例资源策略:
{ "Version": "2012-10-17", "Statement": [{ "Effect": "Allow", "Principal": "*", "Action": "execute-api:Invoke", "Resource": "execute-api:/*/*/*" }, { "Effect": "Deny", "Principal": "*", "Action": "execute-api:Invoke", "Resource": "execute-api:/*/*/*", "Condition": { "NotIpAddress": { "aws:SourceIp": ["sourceIpOrCIDRBlock", "sourceIpOrCIDRBlock"] } } } ] }使用资源策略来控制可以访问
API Gateway的 IP 是 AWS 推荐的做法。
五、对 EC2 进行日常修补并需要暂时从 ALB 中移除
某公司使用 AWS 系统管理器对亚马逊 EC2 实例进行日常管理和修补。EC2 实例位于应用程序负载平衡器 (ALB) 后面的 IP 地址类型目标组中。
新的安全协议要求公司在打补丁期间从服务中移除 EC2 实例。当公司尝试在下一个补丁期间遵循安全协议时,公司会在补丁窗口期间收到错误。
哪种解决方案组合可以解决这些错误?(选择两个)。
- ❌ 将目标组的目标类型从 IP 地址类型改为实例类型。
- 继续使用现有的系统管理器文档,无需更改,因为该文档已经过优化,可以处理 ALB 后面 IP 地址类型目标组中的 实例。
- ✅ 实施 AWSEC2-PatchLoadBalanacerInstance 系统管理器自动化文件来管理修补程序。
- ✅ 使用 “系统管理器维护窗口 “自动将实例从服务中移除,以修补实例。
- ❌ 配置系统管理器状态管理器,将实例从服务中移除并管理修补计划。使用 ALB 健康检查重新路由流量。
1️⃣ 5️⃣ ❌ -> 3️⃣ 4️⃣ ✅
💡 解析:AWSEC2-PatchLoadBalancerInstance
升级并修补附加到任何负载均衡器(经典、ALB 或 NLB)的 Amazon EC2 实例(Windows 或 Linux)的次要版本。在修补该实例之前,会应用默认的连接耗尽时间。您可以为 ConnectionDrainTime 参数输入以分钟 (1-59) 为单位的自定义耗尽时间,从而覆盖等待时间。
自动化工作流程如下所示:
- 确定实例所附加的负载均衡器或目标组,并验证该实例是否运行正常。
- 该实例已从负载均衡器或目标组移除。
- 此自动化将等待为连接耗尽时间指定的时间段。
- 调用 AWS-RunPatchBaseline 自动化以修补该实例。
- 该实例已从负载均衡器或目标组重新附加。
先决条件
- 验证实例上是否安装了 SSM Agent。
因此通过
AWSEC2-PatchLoadBalanacerInstance操作对EC2进行操作的话,会自动将其移出ALB。
六、组织的标签策略
某公司正在为一个使用 AWS 云的新移动应用程序设计架构。该公司使用 AWS 组织中的组织单位 (OU) 管理其账户。该公司希望通过使用敏感和不敏感值来标记亚马逊 EC2 实例的数据敏感性。IAM 身份不得删除标签或创建无标签的实例。
哪种步骤组合能满足这些要求?(选择两个)。
- ✅ 在 “组织 “中,创建一个新标签策略,指定数据敏感性标签密钥和所需值。为 EC2 实例强制执行标签值。将标签策略附加到相应的 OU。
- ❌ 在 “组织 “中,创建一个新的服务控制策略 (SCP),指定数据敏感性标记密钥和所需的标记值。为 EC2 实例强制执行标签值。将 SCP 附加到相应的 OU。
- 创建一个标签策略,在未指定标签密钥时拒绝运行实例。创建另一个标签策略,防止身份删除标签。将标签策略附加到相应的 OU。
- ✅ 创建服务控制策略 (SCP),在未指定标签密钥时拒绝创建实例。创建另一个 SCP,防止身份删除标记。将 SCP 附加到相应的 OU。
- 创建一个 AWS 配置规则,检查 EC2 实例是否使用了数据敏感性标记和指定值。配置 AWS Lambda 函数,以便在发现不合规资源时删除资源。
2️⃣ 4️⃣ ❌ -> 1️⃣ 4️⃣ ✅
💡 解析:4️⃣ 使用 SCP 对 EC2 实例的创建进行限制没有问题。
而 AWS Organizations 其实还有标签策略:标签策略标签策略 是策略的一种类型,可帮助您在组织账户中跨资源标准化标签。在标签策略中,您可以指定在标记资源时适用于资源的标记规则。
例如,标签策略可以指定当 CostCenter 标签附加到资源时,它必须使用标签策略定义的大小写处理和标签值。标签策略还可以指定在指定资源类型上强制执行 不合规的标记操作。换句话说,阻止在指定的资源类型上完成不合规的标记操作。不会评估未标记的资源或未在标签策略中定义的标签是否符合标签策略。
使用标签策略来定义标签和将其使用到 EC2 上,之后使用 SCP 来拒绝创建不带标签的 EC2 实例并防止删除标签。
七、Amazon Athena SQL 支持的数据格式
一家天气预报公司持续从各种传感器收集温度读数。现有的数据摄取流程会收集读数,并将读数汇总到较大的 Apache Parquet 文件中。然后,该流程通过使用 KMS 管理密钥(CSE-KMS)的客户端加密对文件进行加密。最后,该流程将文件写入亚马逊 S3 存储桶,并为每个日历日设置单独的前缀。
公司希望偶尔对数据运行 SQL 查询,以获取特定日历日的移动平均值样本。哪种解决方案能最经济高效地满足这些要求?
- ✅ 配置 Amazon Athena 以读取加密文件。直接在 Amazon S3 中的数据上运行 SQL 查询。
- 使用 Amazon S3 Select 直接对 Amazon S3 中的数据运行 SQL 查询。
- ❌ 配置 Amazon Redshift 以读取加密文件。使用 Redshift Spectrum 和 Redshift query Editor v2 直接对 Amazon S3 中的数据运行 SQL 查询 。
- 配置 Amazon EMR Serverless 以读取加密文件。使用 Apache SparkSQL 直接对亚马逊 S3 中的数据运行 SQL 查询。
3️⃣ ❌ -> 1️⃣ ✅
💡 解析:应在何时使用 Athena?
Athena 可帮助您分析在 Amazon S3 中存储的非结构化、半结构化和结构化数据。示例包括 CSV、JSON 或列式数据格式,如 Apache Parquet 和 Apache ORC。您可以使用 ANSI SQL 通过 Athena 运行临时查询,而无需将数据聚合或加载到 Athena 中。
八、 AWS Glue DynamoDB Export connector
某公司使用 Amazon DynamoDB 表来存储公司从设备接收到的数据。DynamoDB 表支持面向客户的网站,以显示客户设备上的最近活动。该公司为该表配置了写入和读取的预配置吞吐量。
公司希望每天计算客户设备数据的性能指标。解决方案必须对表的预设读写能力影响最小。
哪种解决方案能满足这些要求?
- ❌ 将 Amazon Athena SQL 查询与 Amazon Athena DynamoDB 连接器配合使用,按周期计算性能指标。
- ✅ 使用 AWS Glue 作业和 AWS Glue DynamoDB 导出连接器,按周期计算性能指标。
- 使用 Amazon Redshift COPY 命令按周期计算性能指标。
- 使用带有 Apache Hive 外部表的 Amazon EMR 作业,按周期计算性能指标。
1️⃣ ❌ -> 2️⃣ ✅
以下是使用 AWS Glue ETL 作业从 DynamoDB 表中读取的典型使用案例:
- 将数据从 DynamoDB 表移到其他数据存储
- 将数据与其他服务和应用程序集成
- 保留历史快照以供审计
- 根据 DynamoDB 数据构建 S3 数据湖并分析来自各种服务的数据,例如 Amazon Athena、Amazon Redshift 和 Amazon SageMaker
这种方法具有以下好处:
- 不会占用源 DynamoDB 表的读取容量单位
- 大型 DynamoDB 表的读取性能一致
九、AWS Backup 的 RTO
某公司在应用程序负载平衡器 (ALB) 后面的自动扩展组中的 Amazon EC2 实例上运行一个网络应用程序。该应用程序在 Amazon Aurora MySQL DB 集群中存储数据。
公司需要创建灾难恢复(DR)解决方案。灾难恢复解决方案可接受的恢复时间最长为 30 分钟。灾难恢复解决方案不需要在主基础设施健康时支持客户使用。
哪种解决方案能满足这些要求?
- ✅ 在带有 ALB 和自动扩展组的第二个 AWS 区域中部署灾难恢复基础架构。将自动扩展组的所需容量和最大容量设置为最小值。将 Aurora MySQL DB 集群转换为 Aurora 全局数据库。使用 ALB 端点配置 Amazon Route 53 以实现主动-被动故障切换。
- 在具有 AL 的第二个 AWS 区域中部署灾难恢复基础架构更新自动扩展组,以包括来自第二个区域的 EC2 实例。使用 Amazon Route 53 配置主动-主动故障切换。将 Aurora MySQL DB 集群转换为 Aurora 全局数据库。
- 使用 AWS 备份备份 Aurora MySQL DB 集群数据。在带有 ALB 的第二个 AWS 区域中部署灾难恢复基础设施。更新自动扩展组,将第二个区域的 EC2 实例包括在内。使用 Amazon Route 53 配置主动-主动故障切换。在第二个区域中创建 Aurora MySQL DB 群集 从备份中恢复数据。
- ❌ 使用 AWS 备份备份基础设施配置。使用备份在第二个 AWS 区域创建所需的基础架构。将自动扩展组所需容量设为零。使用 Amazon Route 53 配置主动-被动故障转移。将极光 MySQL DB 集群转换为极光全局数据库。
4️⃣ ❌ -> 2️⃣ ✅
💡 解析:使用 AWS Backup 和重建的耗时是小时级别:云中的灾难恢复选项
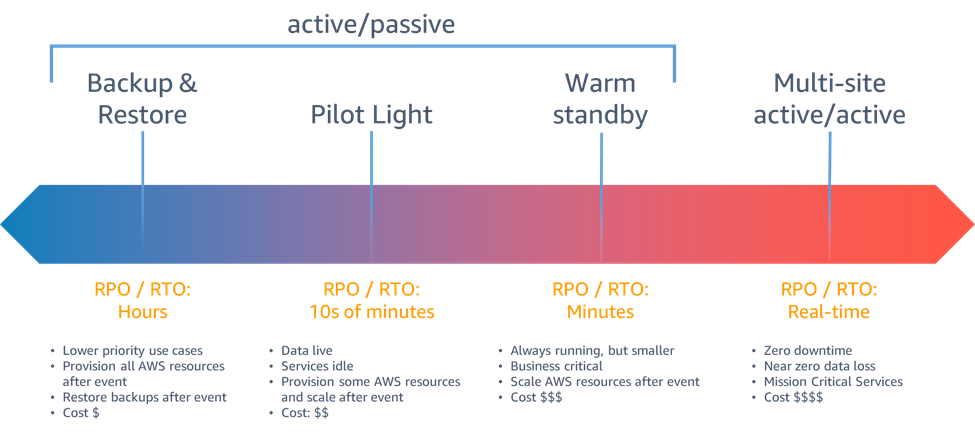
十、Amazon Aurora 的自定义端点
某公司在 Amazon Aurora MySQL DB 集群上运行其生产工作负载,该集群包括六个 Aurora Replicas。该公司希望将其一个部门的近实时报告查询自动分布到三个 Aurora 副本中。这三个副本的计算和内存规格与数据库集群的其他部分不同。
- ✅ 为工作负载创建并使用自定义端点
- 创建三节点集群克隆并使用阅读器端点
- ❌ 为选定的三个节点使用任意一个实例端点
- 使用阅读器端点自动分配只读工作量
3️⃣ ❌ -> 1️⃣ ✅
💡 解析:Amazon Aurora 的自定义端点
Aurora 集群的自定义终端节点 表示一组选定数据库实例。在连接到端点时,Aurora 会执行连接平衡并选择组中的某个实例来处理连接。您可以定义此终端节点引用的实例,并确定此终端节点的用途。
在您创建自定义终端节点之前,Aurora 数据库集群没有自定义终端节点。您可以为每个预调配的 Aurora 集群或 Aurora Serverless v2 集群创建最多 5 个自定义端点。您无法对 Aurora Serverless v1 集群使用自定义终端节点。