来源:Amazon AWS Certified Solutions Architect - Associate SAA-C03 Exam
160 题 (No.321 ~ No.480) 只记录了 13 道错误或需要注意的题目,仅供自己复习使用。
如果侵权请联系删除。
一、Amazon Cognito 身份池的自定义属性映射
某公司通过 Amazon S3 存储桶托管一个网络应用程序。该应用程序使用 Amazon Cognito 作为身份提供程序来验证用户身份,并返回一个 JSON Web 令牌 (JWT),该令牌可提供对存储在另一个 S3 存储桶中的受保护资源的访问权限。
在部署应用程序时,用户会报告错误,并且无法访问受保护的内容。解决方案架构师必须通过提供适当的权限来解决这个问题,这样用户才能访问受保护的内容。
哪种解决方案能满足这些要求?
- ✅ 更新 Amazon Cognito 身份池,以承担访问受保护内容的适当 IAM 角色。
- 更新 S3 ACL,允许应用程序访问受保护的内容。
- 将应用程序重新部署到 Amazon S3,以防止 S3 存储桶中最终一致的读取影响用户访问受保护内容的能力。
- ❌ 更新 Amazon Cognito 池,以便在身份池中使用自定义属性映射,并授予用户访问受保护内容的适当权限。
4️⃣ ❌ -> 1️⃣ ✅
💡 解析:1️⃣ 和 4️⃣ 都能完成题目需求,且 4️⃣ 对权限控制的粒度更细:将属性用于访问控制
访问控制的属性是 Amazon Cognito 身份池实现的基于属性的访问控制 ()。ABAC您可以使用IAM策略根据用户属性控制通过 Amazon Cognito 身份池访问 AWS 资源。可以从社交和企业身份提供商那里获得这些属性。您可以将提供商的访问权限和 ID 令牌或SAML断言中的属性映射到可在IAM权限策略中引用的标签。
您可以选择默认映射或在 Amazon Cognito 身份池中创建自己的自定义映射。默认映射允许您根据一组固定的用户属性编写IAM策略。自定义映射允许您选择IAM权限策略中引用的一组自定义用户属性。Amazon Cognito 控制台中的属性名称映射到主体的标签密钥,即IAM权限策略中引用的标签。
例如,假设您拥有一个具有免费和付费会员资格的媒体流式传输服务。您可以将媒体文件存储在 Amazon S3 中,并使用免费或高级标签对其贴标签。您可以将属性用于访问控制,以允许访问基于用户会员级别(这是用户配置文件的一部分)的免费和付费内容。您可以将成员资格属性映射到标签密钥,以便委托人传递给IAM权限策略。通过这种方式,您可以创建单个权限策略,并根据会员级别的值和内容文件上的标签有条件地允许对高级内容的访问。
通过不同的自定义属性来区分不同等级的会员,以使他们能够访问不同权限要求的资源。
二、Amazon Aurora Global Database headless clusters(全局数据库无头集群)
解决方案架构师必须为大容量软件即服务(SaaS)平台创建灾难恢复(DR)计划。该平台的所有数据都存储在 Amazon Aurora MySQL DB 集群中。
灾难恢复计划必须将数据复制到辅助 AWS 区域。
哪种解决方案能以最具成本效益的方式满足这些要求?
- 使用 MySQL 二进制日志复制到辅助区域中的 Aurora 群集。为辅助区域中的 Aurora 群集提供一个 DB 实例。
- ✅ 为 DB 集群设置 Aurora 全局数据库。设置完成后,从二级区域中删除 DB 实例。
- 使用 AWS 数据库迁移服务 (AWS DMS) 将数据持续复制到辅助区域中的 Aurora 群集。从辅助区域删除 DB 实例。
- 为 DB 集群设置 Aurora 全局数据库。在辅助区域中至少指定一个 DB 实例。
2️⃣ ✅
尽管 Aurora Global Database 要求在与主区域之外的不同 AWS 区域 中至少有一个辅助 Aurora 数据库集群,但您可以对辅助集群使用无管控配置。无管控辅助 Aurora 数据库集群是没有数据库实例的集群。此类型的配置可以降低 Aurora 全局数据库的开支。在 Aurora 数据库集群中,计算和存储是分离的。如果没有数据库实例,您就无需为计算付费,而只需为存储付费。如果设置正确,无管控辅助存储卷将与主 Aurora 数据库集群保持同步。
在主 Aurora 数据库集群开始复制到辅助数据库集群之后,您可以从辅助 Aurora 数据库集群中删除该 Aurora 只读数据库实例。此辅助集群现在被视为“无管控”集群,因为其不再有数据库实例。即使辅助集群中没有任何数据库实例,Aurora 也会将存储卷与主 Aurora 数据库集群保持同步。
三、SNS 和 SQS 的传输中与静态加密
一家医院正在设计一个收集病人症状的新应用程序。医院决定在架构中使用亚马逊简单队列服务(Amazon SQS)和亚马逊简单通知服务(Amazon SNS)。
解决方案架构师正在审查基础设施设计。数据在静态和传输过程中都必须加密。只有医院的授权人员才能访问数据。
解决方案架构师应采取哪些步骤组合来满足这些要求?(选择两个)。
- 在 SQS 组件上开启服务器端加密。更新默认密钥策略,将密钥使用限制为一组授权委托人。
- ✅ 使用 AWS 密钥管理服务 (AWS KMS) 客户管理的密钥,开启 SNS 组件的服务器端加密。应用密钥策略,将密钥的使用限制在一组授权委托人范围内。
- 打开 SNS 组件的加密功能。更新默认密钥策略,将密钥使用限制为一组授权委托人。在主题策略中设置一个条件,只允许通过 TLS 进行加密连接。
- ✅ 使用 AWS 密钥管理服务 (AWS KMS) 客户管理的密钥,开启 SQS 组件的服务器端加密。应用密钥策略,将密钥的使用限制在一组授权委托人范围内。在队列策略中设置一个条件,只允许通过 TLS 进行加密连接。
- 使用 AWS 密钥管理服务 (AWS KMS) 客户管理的密钥,开启 SQS 组件的服务器端加密。应用 IAM 策略,将密钥的使用限制在一组授权委托人范围内。在队列策略中设置一个条件,只允许通过 TLS 进行加密连接。
2️⃣ 4️⃣ ✅
💡 解析:
SNS强制要求使用安全协议操作相关 API,这已经实现了传输中加密:Amazon 的基础设施安全 SNS使用 AWS API操作SNS通过网络访问 Amazon。客户端必须支持传输层安全 (TLS) 1.2 或更高版本。
SNS支持使用KMS中的密钥对消息进行静态加密:使用服务器端加密保护 Amazon SNS 数据服务器端加密 (SSE) 允许您使用在 AWS Key Management Service (AWS KMS) 中管理的密钥保护 Amazon 主题中的消息内容,从而将敏感数据存储在加密SNS主题中。
SSE Amazon SNS 收到消息后立即对其进行加密。消息以加密形式存储,仅在发送时才解密。
SQS也强制了需要使用安全协议:Amazon SQS 中的基础设施安全性您可以使用 AWS 已发布的 API 操作通过网络访问 Amazon SQS。客户端必须支持传输层安全性(TLS)1.2 或更高版本。
SQS当然也支持使用KMS中的密钥对消息进行静态加密:Amazon 中的静态加密 SQS服务器端加密 (SSE) 允许您在加密队列中传输敏感数据。SSE使用SQS管理的加密密钥 (SSE-SQS) 或在 (-) 中管理的密钥保护队列中的 AWS Key Management Service 邮件内容。SSE KMS有关SSE使用进行管理的信息 AWS Management Console,请参阅以下内容:
- 配置 SSE-SQS 用于队列(控制台)
- 配置 SSE-KMS 用于队列(控制台)
四、API Gateway API 的 API 鉴权
一家公司的网络应用程序由亚马逊 API Gateway API 和 AWS Lambda 函数以及亚马逊 DynamoDB 数据库。Lambda 函数处理业务逻辑,DynamoDB 表托管数据。应用程序使用 Amazon Cognito 用户池来识别应用程序的单个用户。解决方案架构师需要更新应用程序,以便只有订阅的用户才能访问高级内容。
哪种解决方案能以最少的运行开销满足这一要求?
- 在 API Gateway API 上启用 API 缓存和节流。
- ❌ 在 API Gateway API 上设置 AWS WAF。创建一条规则,过滤已订阅的用户。
- 对 DynamoDB 表中的高级内容应用细粒度 IAM 权限。
- ✅ 实施 API 使用计划和 API 密钥,限制未订阅用户的访问权限。
2️⃣ ❌ -> 4️⃣ ✅
💡 解析:API 密钥和使用计划的最佳实践
以下是使用 API 密钥和使用计划时要遵循的建议的最佳实践。
- 请勿使用 API 密钥进行身份验证或授权以控制对 API 的访问权限。如果您在一个使用计划中有多个 API,则具有该使用计划中的一个 API 的有效 API 密钥的用户可以访问该使用计划中的所有 API。相反,要控制对 API 的访问权限,请使用 IAM 角色、Lambda 授权方或 Amazon Cognito 用户群体。
- 使用 API Gateway 生成的 API 密钥。API 密钥不应包含机密信息;客户端通常使用可记录的标头传输这些信息。
- 如果您使用开发人员门户发布 API,请注意,给定使用计划中的所有 API 均可由客户订阅,即使您尚未向您的客户显示它们。
- 在某些情况下,客户端可能会超过您设置的配额。不要依靠使用计划来控制成本。考虑使用 AWS Budgets 监控成本和 AWS WAF 来管理 API 请求。
- 将 API 密钥添加到使用计划后,更新操作可能需要几分钟才能完成。
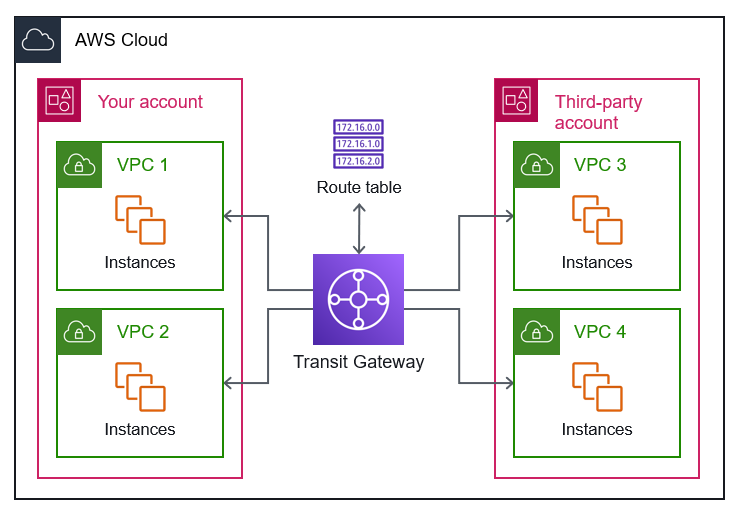
五、跨 VPC 组网并连接到本地数据中心
某公司在 us-east-1 区域内的三个独立 VPC 中运行多个业务应用程序。这些应用程序必须能够在 VPC 之间进行通信。这些应用程序还必须能够每天持续向在单个内部数据中心运行的延迟敏感型应用程序发送数百千兆字节的数据。
解决方案架构师需要设计一个网络连接解决方案,最大限度地提高成本效益。哪种解决方案能满足这些要求?
- 配置三个从数据中心到 AWS 的 AWS 站点到站点 VPN 连接。通过为每个 VPC 配置一个 VPN 连接来建立连接。
- 在每个 VPC 中启动第三方虚拟网络设备。在数据中心和每个虚拟设备之间建立 IPsec VPN 通道。
- ❌ 从数据中心到 us-east-1 中的 Direct Connect 网关设置三个 AWS Direct Connect 连接。通过配置每个 VPC 以使用其中一个 Direct Connect 连接来建立连接。
- ✅ 建立一个从数据中心到 AWS 的 AWS Direct Connect 连接。创建一个中转网关,并将每个 VPC 附加到中转网关。在 Direct Connect 连接和中转网关之间建立连接。
3️⃣ ❌ -> 4️⃣ ✅
需要注意的是
Transit Gateway并不是包含在任意VPC内部的。
六、弹性扩展 RDS DB 实例
一家公司正在将其内部工作负载迁移到 AWS 云。该公司已经使用了几个 Amazon EC2 实例和 Amazon RDS DB 实例。该公司需要一个能在工作时间外自动启动和停止 EC2 实例和 DB 实例的解决方案。该解决方案必须最大限度地降低成本和基础设施维护成本。
哪种解决方案能满足这些要求?
- ❌ 使用弹性调整 EC2 实例的大小。在工作时间外将 DB 实例扩展为零。
- 在 AWS Marketplace 探索合作伙伴解决方案,这些解决方案将按计划自动启动和停止 EC2 实例和 DB 实例。
- 启动另一个 EC2 实例。配置 crontab 计划,运行 shell 脚本,按计划启动和停止现有 EC2 实例和 DB 实例。
- ✅ 创建一个 AWS Lambda 函数,用于启动和停止 EC2 实例和 DB 实例。配置 Amazon EventBridge 以按计划调用 Lambda 函数。
1️⃣ ❌ -> 4️⃣ ✅
💡 解析:弹性扩展无法将 DB 实例的个数缩小为 0。
虽然我没有找到实际的文档,但是可以理解吧,毕竟停止后如何建立新的数据库连接呢。
七、对不需要本地存储的 EC2 实例进行备份
某公司需要为其三层无状态网络应用程序制定备份策略。网络应用程序在自动扩展组中的 Amazon EC2 实例上运行,该组具有动态扩展策略,可对扩展事件做出响应。数据库层在 PostgreSQL 的 Amazon RDS 上运行。网络应用程序不需要 EC2 实例上的临时本地存储。公司的恢复点目标 (RPO) 为 2 小时。
备份策略必须最大限度地提高该环境的可扩展性并优化资源利用率。哪种解决方案能满足这些要求?
- 每 2 小时对 EC2 实例和数据库的 Amazon Elastic Block Store (Amazon EBS) 卷进行快照,以满足 RPO 要求。
- 配置快照生命周期策略,以获取 Amazon Elastic Block Store (Amazon EBS) 快照。在 Amazon RDS 中启用自动备份,以满足 RPO。
- ✅ 保留 Web 层和应用层的最新 Amazon Machine Images (AMI)。在 Amazon RDS 中启用自动备份,并使用时间点恢复来满足 RPO。
- ❌ 每 2 小时对 EC2 实例的 Amazon Elastic Block Store (Amazon EBS) 卷进行快照。在 Amazon RDS 中启用自动备份,并使用时间点恢复来满足 RPO。
4️⃣ ❌ -> 3️⃣ ✅
数据块存储
- Amazon EBS – Amazon EBS 提供持久的块级存储卷,您可以将其附加到实例或从实例中分离。您可以将多个 EBS 卷附加到一个实例。EBS 卷始终不受其关联实例的生命周期影响。您可以对 EBS 卷进行加密。要保留您数据的备份副本,您可以从 EBS 卷创建快照。快照会存储在 Amazon S3 中。您可以从快照创建 EBS 卷。
- 适用于 EC2 实例的实例存储临时块存储 – 实例存储可以为实例提供临时性块级存储。实例存储卷的数量、大小和类型由实例类型和实例大小决定。实例存储卷上的数据仅在关联实例的生命周期内保留;如果您停止、休眠或终止实例,则实例存储卷上的所有数据都会丢失。
在题目描述的情况下,就只是对临时块存储进行备份(通过 AMI 的制作)。
八、Amazon Kinesis Data Streams 默认的消息保留期限和管道大小
一家公司需要采集和处理其应用程序生成的大量流式数据。该应用程序在 Amazon EC2 实例,并将数据发送到 Amazon Kinesis Data Streams,该数据流采用默认设置配置。每隔一天,应用程序消耗数 据并将数据写入 Amazon S3 存储桶,以便进行商业智能 (BI) 处理。该公司发现,Amazon S3 并未接收到应用程序发送到 Kinesis Data Streams 的所有数据。
解决方案架构师应该如何解决这个问题?
- ✅ 通过修改数据保留期更新 Kinesis 数据流默认设置。
- 更新应用程序,使用 Kinesis 生产者库 (KPL) 将数据发送到 Kinesis 数据流。
- ❌ 更新 Kinesis 碎片的数量,以处理发送到 Kinesis 数据流的数据吞吐量。
- 在 S3 存储桶内打开 S3 版本控制,以保存 S3 存储桶中摄取的每个对象的每个版本。
3️⃣ ❌ -> 1️⃣ ✅
💡 解析:
Amazon Kinesis Data Streams的分片随模式不同而不同:限额和限制
- 按需模式 - 并无上限。分片数量取决于摄取的数据量和所需的吞吐量级别。Kinesis Data Streams 会根据数据量和流量的变化自动扩展分片数量。
- 预置模式 - 并无上限。以下 AWS 区域每个 AWS 账户的默认分片限额为 500 个分片:美国东部(弗吉尼亚州北部)、美国西部(俄勒冈州)和欧洲地区(爱尔兰)。其余区域每个 AWS 账户的默认分片限额为 200 个分片。
而保留期则同一默认为 24 小时:更改数据留存期
从添加记录到记录不再可访问的时间段称为保留期。Kinesis 数据流存储记录的时间默认为 24 小时,最长可达 8760 小时(365 天)。
九、RDS Multi-AZ 实例和集群部署的 RTO
某公司希望使用 Amazon RDS for PostgreSQL DB 集群来简化生产数据库工作负载耗时的数据库管理任务。该公司希望确保其数据库的高可用性,并在大多数情况下在 40 秒内提供自动故障切换支持。该公司希望卸载主实例的读取,并尽可能降低成本。
哪种解决方案能满足这些要求?
- ❌ 使用 Amazon RDS Multi-AZ DB 实例部署。创建一个读取副本,并将读取工作负载指向读取副本。
- 使用 Amazon RDS Multi-AZ DB duster 部署 创建两个读副本,并将读工作负载指向读副本。
- 使用 Amazon RDS Multi-AZ DB 实例部署。将读取工作负载指向多 AZ 对中的辅助实例。
- ✅ 使用 Amazon RDS Multi-AZ DB 集群部署 将读取工作负载指向阅读器端点。
1️⃣ ❌ -> 4️⃣ ✅
💡 解析:RDS Multi-AZ 实例的恢复时间在 60 ~ 120 秒:Failing over a Multi-AZ DB instance for Amazon RDS
The time that it takes for the failover to complete depends on the database activity and other conditions at the time the primary DB instance became unavailable. Failover times are typically 60–120 seconds. However, large transactions or a lengthy recovery process can increase failover time. When the failover is complete, it can take additional time for the RDS console to reflect the new Availability Zone.
而 RDS Multi-AZ 集群的恢复时间在 35 秒左右:Multi-AZ DB cluster
The Multi-AZ DB cluster combines automatic failover with two readable standby instances and provides up to 2x faster commit latencies and automated failovers, typically under 35 seconds.
如果要达到题目要求的 40 秒以内的话,只能选集群。
同时集群启动的时候会自带只读副本,因此选 4️⃣。
十、RDS for MySQL 使用快照和 mysqldump 还原
一家公司在应用测试期间使用了亚马逊 RDS for MySQL DB 实例。在测试周期结束时终止数据库实例之前,解决方案架构师创建了两个备份。解决方案架构师使用 mysqldump 实用程序创建数据库转储,从而创建了第一个备份。解决方案架构师通过启用 RDS 终止时的最终数据库快照选项创建了第二个备份。
该公司目前正在计划一个新的测试周期,并希望从最近的备份中创建一个新的数据库实例。公司选择了与 MySQL 兼容的 Aurora 版本来托管数据库实例。
哪些解决方案将创建新 DB 实例?(选择两个)。
- ✅ 将 RDS 快照直接导入 Aurora。
- ❌ 将 RDS 快照上传到 Amazon S3。然后将 RDS 快照导入 Aurora。
- ✅ 将数据库转储上传到 Amazon S3。然后将数据库转储导入 Aurora。
- 使用 AWS 数据库迁移服务(AWS DMS)将 RDS 快照导入 Aurora。
- ❌ 将数据库转储上传到 Amazon S3。然后使用 AWS 数据库迁移服务(AWS DMS)将数据库转储导入 Aurora。
2️⃣ 5️⃣ ❌ -> 1️⃣ 3️⃣ ✅
💡 解析:快照一直保留在 AWS 中因此不需要再次上传。
而使用 mysqldump 还原到 Aurora MySQL 引擎,直接导入即可:使用 mysqldump 从 MySQL 逻辑迁移到 Amazon Aurora MySQL因为 Amazon Aurora MySQL 是与 MySQL 兼容的数据库,所以您可以使用
mysqldump实用程序从 MySQL 或 MariaDB 数据库中将数据复制到现有 Aurora MySQL 数据库集群。
十一、Amazon Route 53 与 Amazon CloudFront 的容灾选择
某公司有一个无状态 Web 应用程序,该程序运行在亚马逊 API Gateway 调用的 AWS Lambda 函数上。该公司希望在多个 AWS 区域部署应用程序,以提供区域故障转移功能。
解决方案架构师应如何将流量路由到多个区域?
- ✅ 为每个区域创建 Amazon Route 53 健康检查。使用主动-主动故障切换配置。
- ❌ 创建一个 Amazon CloudFront 分发,并为每个区域设置一个起源。使用 CloudFront 健康检查来路由流量。
- 创建中转网关。将中转网关附加到每个区域的 API 网关端点。配置中转网关以路由请求。
- 在主区域创建应用程序负载平衡器。将目标组设置为指向每个区域的 API Gateway 端点主机名。
2️⃣ ❌ -> 1️⃣ ✅
💡 解析:
CloudFront提供一定程度的容灾:通过 CloudFront 源失效转移来优化高可用性在为缓存行为配置源故障转移后,CloudFront 将针对查看器请求执行以下操作:
- 当主源返回不是为故障转移配置的状态代码(如 HTTP 2xx 或 3xx 状态代码)时,CloudFront 将向查看器提供请求的对象。
- 发生以下任何情况时:
- 主源返回您为故障转移配置的 HTTP 状态代码
- CloudFront 无法连接到主源
- 来自主源的响应需要太长时间(超时)
然而它并不具备选项中描述的健康检查功能:在CloudFront分配前使用Route53健康检查和故障转移
“评估目标状态”与支持健康检查的别名记录一起使用,但CloudFront不支持此服务,因为它不返回健康检查。
我认为你可以使用CloudFront的自定义错误响应,这样,如果ALB出现错误,它可以将流量重定向到托管在S3桶中的自定义静态页面。
十二、EBS 卷的多重挂载
某公司正在开发一个应用程序,以支持客户需求。该公司希望在在同一可用区内有多个基于亚马逊 EC2 Nitro 的实例。该公司还希望让应用程序能够同时写入多个基于 EC2 Nitro 的实例中的多个块存储卷,以实现更高的应用程序可用性。
哪种解决方案能满足这些要求?
- 使用通用 SSD (gp3) EBS 卷与 Amazon Elastic Block Store (Amazon EBS) 多重连接
- 将吞吐量优化的硬盘 (st1) EBS 卷与 Amazon Elastic Block Store (Amazon EBS) 多连接一起使用
- ✅ 使用 Amazon Elastic Block Store (Amazon EBS) Multi-Attach 配置 IOPS SSD (io2) EBS 卷
- 使用通用 SSD (gp2) EBS 卷与 Amazon Elastic Block Store (Amazon EBS) 多重连接
3️⃣ ✅
💡 解析:只有 io1 或 io2 卷支持多重挂载:使用多重挂载将 EBS 卷挂载到多个 EC2 实例
通过 Amazon EBS 多重挂载,您可以将单个预置 IOPS SSD(io1 或 io2)卷挂载到位于同一可用区中的多个实例。您可以将多个启用多重挂载的卷附加到一个实例或一组实例。卷附加到的每个实例都对共享卷拥有完全读取和写入权限。通过多重挂载,您可以更轻松地在管理并发写入操作的应用程序中实现更高的应用程序可用性。
十三、将最小权限授予给 IAM 组
某公司预计在不久的将来会迅速发展。解决方案架构师需要配置现有用户并授予新用户在 AWS 上的权限。解决方案架构师决定创建 IAM 组。解决方案架构师将根据部门把新用户添加到 IAM 组。
向新用户授予权限的最安全方法是哪种附加操作?
- 应用服务控制策略 (SCP) 管理访问权限
- ❌ 创建权限最小的 IAM 角色。将角色附加到 IAM 组
- ✅ 创建一个授予最少权限的 IAM 策略。将策略附加到 IAM 组
- 创建 IAM 角色。将角色与定义最大权限的权限边界关联起来
2️⃣ ❌ -> 3️⃣ ✅
💡 解析:
IAM 组不能对IAM 角色进行扮演:角色术语和概念角色可由以下用户代入:
- 相同 AWS 账户 或另一个 AWS 账户 中的 IAM 用户
- 同一账户中的 IAM 角色
- 服务主体,用于 AWS 服务和功能,例如:
- 允许您在计算服务上运行代码的服务,如 Amazon EC2 或 AWS Lambda
- 代表您对资源执行操作的功能,如 Amazon S3 对象复制
- 为在 AWS 外部运行的应用程序提供临时安全凭证的服务,如 IAM Roles Anywhere 或 Amazon ECS Anywhere
- 由与 SAML 2.0 或 OpenID Connect 兼容的外部身份提供者(IdP)服务进行身份验证的外部用户
这里需要注意允许角色链的概念。