来源:Amazon AWS Certified Solutions Architect - Associate SAA-C03 Exam
100 题 (No.701 ~ No.800) 只记录了 15 道首次碰到的、错误的或有疑问的题目,仅供自己复习使用。
其中有 65 题与正式考试题量一样,总共耗时 87/(130+30) 分钟,正确率为 57/65。
如果侵权请联系删除。
一、SnowFamily and S3
A company copies 200 TB of data from a recent ocean survey onto AWS Snowball Edge Storage Optimized devices. The company has a high performance computing (HPC) cluster that is hosted on AWS to look for oil and gas deposits. A solutions architect must provide the cluster with consistent sub-millisecond latency and high-throughput access to the data on the Snowball Edge Storage Optimized devices. The company is sending the devices back to AWS.
Which solution will meet these requirements?
- Create an Amazon S3 bucket. Import the data into the S3 bucket. Configure an AWS Storage Gateway file gateway to use the S3 bucket. Access the file gateway from the HPC cluster instances.
- ✅ Create an Amazon S3 bucket. Import the data into the S3 bucket. Configure an Amazon FSx for Lustre file system, and integrate it with the S3 bucket. Access the FSx for Lustre file system from the HPC cluster instances.
- Create an Amazon S3 bucket and an Amazon ElasticFile System (Amazon EFS) file system. Import the data into the S3 bucket. Copy the data from the S3 bucket to the EFS file system. Access the EFS file system from the HPC cluster instances.
- ❌ Create an Amazon FSx for Lustre file system. Import the data directly into the FSx for Lustre file system. Access the FSx for Lustre file system from the HPC cluster instances.
✨ 关键词:
4️⃣ ❌ -> 2️⃣ ✅
💡 解析:使用 Amazon S3 适配器传输文件,以便在 Snow Family 设备之间迁移数据
以下是 Amazon S3 适配器的概述,您可以使用该适配器通过 Amazon S3 操作以编程方式将数据传输到设备上已有的 S3 存储桶或从 AWS Snowball Edge 设备上传输数据。REST API此 Amazon S3 REST API 支持仅限于部分操作。您可以将此操作子集与其中一个操作配合使用, AWS SDKs以编程方式传输数据。您还可以对 Amazon S3 使用这一部分受支持的 AWS Command Line Interface (AWS CLI)命令来以编程方式传输数据。
社区选 2️⃣ 的原因是
SnowFamily只支持S3形式的存储,但是我并没有在官方的文档中找到完全一样的描述,只有说支持S3的:什么是 AWS Snowball Edge?在这些设备上的 Snow Family 设备上使用与 Amazon S3 兼容的存储空间时,可用存储空间会有所不同。请参阅在 Snow Family 设备上在 Snow Family 设备上使用兼容 Amazon S3 的存储,了解在 Sn ow Family 设备上使用兼容 Amazon S3 的存储容量。
姑且暂时这么认为吧:
SnowFamily设备上只能以S3形式存储文件。
👨👨👦👦 社区讨论:No direct integration between Snowball and Fsx for Lustre. It must be via S3.
Snowball Edge (Storage Optimized) —> S3 —integrate—> FSx for Lustre
https://docs.aws.amazon.com/fsx/latest/LustreGuide/create-dra-linked-data-repo.html
https://aws.amazon.com/tw/blogs/aws/enhanced-amazon-s3-integration-for-amazon-fsx-for-lustre/
二、Route 53 Resolver
A company is designing a web application on AWS. The application will use a VPN connection between the company’s existing data centers and the company’s VPCs.
The company uses Amazon Route 53 as its DNS service. The application must use private DNS records to communicate with the on-premises services from a VPC.
Which solution will meet these requirements in the MOST secure manner?
- ✅ Create a Route 53 Resolver outbound endpoint. Create a resolver rule. Associate the resolver rule with the VPC.
- Create a Route 53 Resolver inbound endpoint. Create a resolver rule. Associate the resolver rule with the VPC.
- ❌ Create a Route 53 private hosted zone. Associate the private hosted zone with the VPC.
- Create a Route 53 publichosted zone. Create a record for each service to allow service communication
✨ 关键词:
3️⃣ ❌ -> 1️⃣ ✅
💡 解析:什么是 Amazon Route 53 Resolver?
Amazon Route 53 Resolver 会递归响应 AWS 资源对公共记录、Amazon VPC 特定 DNS 名称和 Amazon Route 53 私有托管区域的 DNS 查询,默认情况下在所有 VPC 中都可用。
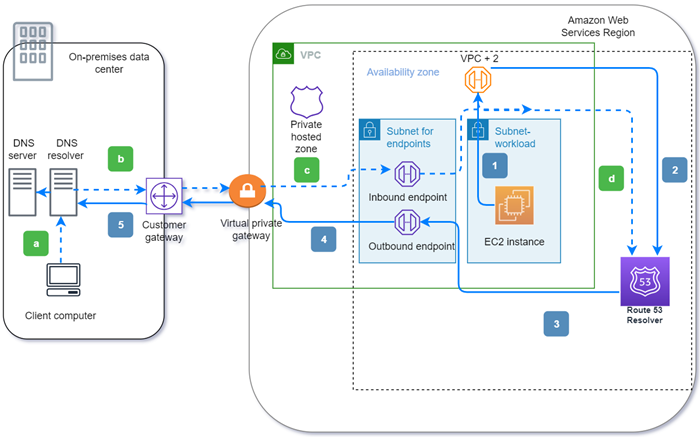
出站(实心箭头 1–5):
- 亚马逊EC2实例需要解析对域名internal.example.com的DNS查询。权威DNS服务器位于本地数据中心。此DNS查询被发送到连接VPC到 Route 53 Resolver 的 VPC +2。
- Route 53 Resolver 转发规则配置为将查询转发到本地数据中心的 internal.example.com。
- 查询将被转发到出站端点。
- 出站终端节点通过与数据中心之间的 AWS 私有连接将查询转发给本地DNS解析器。该连接可以是 AWS Direct Connect 或 AWS Site-to-Site VPN,可以描述为虚拟专用网关。
- 本地DNS解析器解析对 internal.example.com 的DNS查询,并通过相同的路径反向将答案返回给亚马逊EC2实例。
入站(虚线箭头 a–d):
- 本地数据中心的客户端需要解析对域 dev.example.com AWS 资源的DNS查询。它将查询发送到本地解DNS析器。
- 本地解DNS析器具有转发规则,可将发往 dev.example.com 的查询指向入站终端节点。
- 查询通过私有连接(例如 AWS Direct Connect 或)到达入站终端节点 AWS Site-to-Site VPN,该连接被描述为虚拟网关。
- 入站终端节点将查询发送到 Route 53 解析器,Route 53 解析器解析 dev.example.com 的DNS查询,并通过相同的路径反向将答案返回给客户端。
本题中,
VPC内的服务要访问本地托管的服务,因此属于出栈,需要使用Route 53 Resolver outbound endpoint。公有托管区域是一个容器,其中包含的信息说明您希望如何路由特定域(如 example.com)及其子域(acme.example.com 和 zenith.example.com)的 Internet 流量。
私有托管区域是一个容器,其中包含有关您希望 Amazon Route 53 如何响应您使用 Amazon VPC 服务创建的一个或多个VPCs域名及其子域名的DNS查询的信息。
公有托管区面向互联网,私有托管区面向
VPC。
👨👨👦👦 社区讨论:If you have workloads that leverage both VPCsand on-premises resources, you also need to resolve DNS records hosted on-premises.Similarly, these on-premises resources may need to resolve names hosted on AWS.Through Resolver endpoints and conditional forwarding rules, you can resolve DNS queries between your on-premises resourcesand VPCs to create a hybrid cloud setup over VPN or Direct Connect (DX).Specifically:
Inbound Resolver endpoints allow DNS queries to your VPC from your on-premises network or another VPC.
Outbound Resolver endpoints allow DNS queries from your VPC to your on-premises network or another VPC.
Reference: https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/resolver.html
三、Saving Plans coverage
A company uses Amazon EC2, AWS Fargate, and AWS Lambda to run multiple workloads in the company’s AWS account. The company wants to fully make use of its Compute Savings Plans. The company wants to receive notification when coverage of the Compute Savings Plans drops.
Which solution will meet these requirements with the MOST operational efficiency?
- ✅ Create a daily budget for the Savings Plans by using AWS Budgets. Configure the budget with a coverage threshold to send notifications to the appropriate email message recipients.
- Create a Lambda function that runs a coverage report against the Savings Plans. Use Amazon Simple Email Service (Amazon SES) to email the report to the appropriate email message recipients.
- Create an AWS Budgets report for the Savings Plans budget. Set the frequency to daily.
- ❌ Create a Savings Plans alert subscription. Enable all notification options. Enter an email address to receive notifications.
✨ 关键词:
4️⃣ ❌ -> 1️⃣ ✅
💡 解析:使用 AWS Budgets 管理成本
您可以使用 AWS Budgets 来跟踪 AWS 成本和使用情况并执行操作。您可以使用 AWS Budgets 监控预留实例 (RI) 或 Savings Plans 的聚合利用率和覆盖率指标。
您可以使用 AWS Budgets 启用简单到复杂成本和使用情况跟踪。一些示例包括:
- 设置每日利用率或覆盖率预算,以跟踪您的 RI 或 Savings Plans。您可以选择在指定日期的利用率降至 80% 以下时通过电子邮件和 Amazon SNS 主题接收通知。
您可创建下列类型的预算:
- Savings Plans 使用率预算 - 定义使用率阈值,并在 Savings Plans 的使用率低于该阈值时接收提醒。这使您可以查看 Savings Plans 是否未使用或未充分利用。
- Savings Plans 覆盖率预算 - 定义覆盖率阈值,并在 Savings Plans 覆盖的 Savings Plans 合格使用量低于该阈值时接收提醒。这使您可以查看 Savings Plans 所覆盖的实例使用量的多少。
这和题目中描述的 Saving Plans 覆盖率下降相符。
👨👨👦👦 社区讨论:My vote is for A : https://docs.aws.amazon.com/savingsplans/latest/userguide/sp-usingBudgets.html
四、Default Host Configuration Management
A company has applications that run on Amazon EC2 instances. The EC2 instances connect to Amazon RDS databases by using an IAM role that has associated policies. The company wants to use AWS Systems Manager to patch the EC2 instances without disrupting the running applications.
Which solution will meet these requirements?
- ❌ Create a new IAM role. Attach the AmazonSSMManagedInstanceCore policy to the new IAM role. Attach the new IAM role to the EC2 instances and the existing IAM role.
- Create an IAM user. Attach the AmazonSSMManagedInstanceCore policy to the IAM user. Configure Systems Manager to use the IAM user to manage the EC2 instances.
- ✅ Enable Default Host Configuration Management in Systems Manager to manage the EC2 instances.
- Remove the existing policies from the existing IAM role. Add the AmazonSSMManagedInstanceCore policy to the existing IAM role.
✨ 关键词:
1️⃣ ❌ -> 3️⃣ ✅
通过“默认主机管理配置”设置,AWS Systems Manager 可以将 Amazon EC2 实例作为托管式实例自动管理。托管实例是一个配置为与 Systems Manager 一起使用的 EC2 实例。
使用 Systems Manager 管理实例的好处包括以下几点:
- 可以使用 Session Manager 安全地连接到您的 EC2 实例。
- 可以使用 Patch Manager 执行自动补丁扫描。
- 可以使用 Systems Manager 清单查看有关您的实例的详细信息。
- 可以使用 Fleet Manager 追踪和管理实例。
- 可以自动保持 SSM Agent 处于最新状态。
“默认主机管理配置”使您无需手动创建 AWS Identity and Access Management(IAM)实例配置文件即可管理 EC2 实例。“默认主机管理配置”会创建并应用默认 IAM 角色,确保 Systems Manager 有权管理已激活该设置的 AWS 账户 和 AWS 区域 中的所有实例。
如果提供的权限不足以满足您的应用场景要求,您还可以向“默认主机管理配置”创建的默认 IAM 角色添加策略。或者,如果您不需要默认 IAM 角色提供的所有功能的权限,可以创建自己的自定义角色和策略。对您为“默认主机管理配置”选择的 IAM 角色所做的任何更改,都适用于相应区域和账户中的所有托管 Amazon EC2 实例。
👨👨👦👦 社区讨论:option C…Default Host Management Configuration createsand appliesa default IAM role to ensure thatSystems Manager has permissions to manage all instances in the Region and perform automated patch scans using Patch Manager.
五、AWS Direct Connect Gateway
A company has an AWS Direct Connect connection from its corporate data center to its VPC in the us-east-1 Region. The company recently acquired a corporation that has several VPCs and a Direct Connect connection between its on-premises data center and the eu-west-2 Region. The CIDR blocks for the VPCs of the company and the corporation do not overlap. The company requires connectivity between two Regions and the data centers. The company needs a solution that is scalable while reducing operational overhead.
What should a solutions architect do to meet these requirements?
- Set up inter-Region VPC peering between the VPC in us-east-1 and the VPCs in eu-west-2.
- Create private virtual interfaces from the Direct Connect connection in us-east-1 to the VPCs in eu-west-2.
- ❌ Establish VPN appliances in a fully meshed VPN network hosted by Amazon EC2. Use AWS VPN CloudHub to send and receive data between the data centers and each VPC.
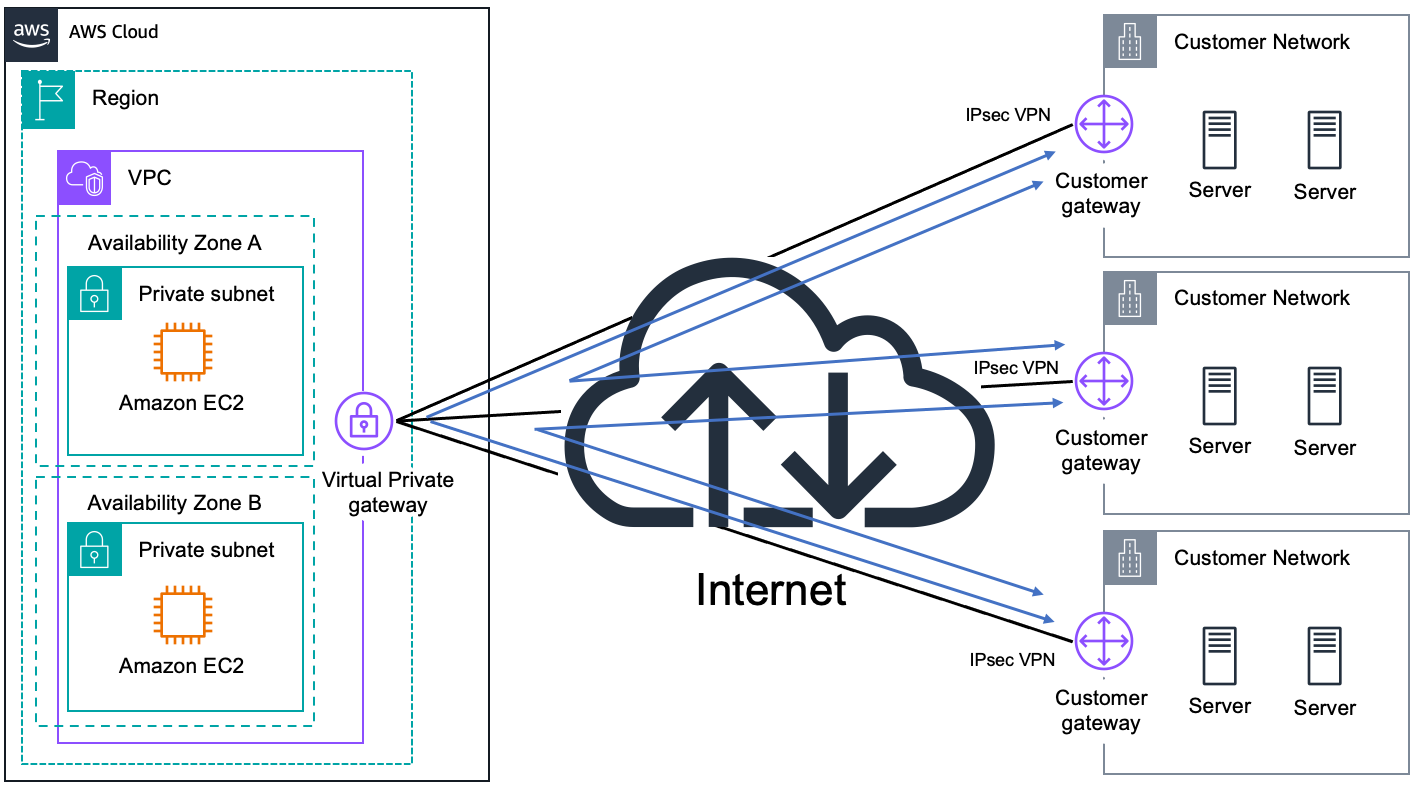
- ✅ Connect the existing Direct Connect connection to a Direct Connect gateway. Route traffic from the virtual private gateways of the VPCs in each Region to the Direct Connect gateway.
✨ 关键词:
3️⃣ ❌ -> 4️⃣ ✅
使用 AWS Direct Connect 网关连接您的 VPC。将 AWS Direct Connect 网关与以下任一网关关联:
- 当您在同一区域有多个 VPC 时的中转网关
- 虚拟私有网关
您也可以使用虚拟私有网关来扩展本地区域。
Direct Connect 网关是全球可用资源。您可以使用 Direct Connect 网关连接到全球任何区域。你可以通过使用
AWS Direct Connect连接到AWS Direct Connect Gateway,之后再连接到其他区域,因此 4️⃣ 正确。
需要注意的是,AWS VPN CloudHub是使用建立在公网上的 VPN 隧道,并连接Amazon VPC 虚拟私有网关和客户网关实现的:AWS VPN CloudHub
👨👨👦👦 社区讨论:“If you want to set up a Direct Connect to one or more VPC in many different regions (same account), you must use a Direct Connect Gateway.”
六、S3 Transfer Acceleration
A company has a new mobile app. Anywhere in the world, users can see local news on topics they choose. Users also can post photos and videos from inside the app.
Users access content often in the first minutes after the content is posted. New content quickly replaces older content, and then the older content disappears. The local nature of the news means that users consume 90% of the content within the AWS Region where it is uploaded.
Which solution will optimize the user experience by providing the LOWEST latency for content uploads?
- Upload and store content in Amazon S3. Use Amazon CloudFront for the uploads.
- ✅ Upload and store content in Amazon S3. Use S3 Transfer Acceleration for the uploads.
- Upload content to Amazon EC2 instances in the Region that is closest to the user. Copy the data to Amazon S3.
- ❌ Upload and store content in Amazon S3 in the Region that is closest to the user. Use multiple distributions of Amazon CloudFront.
✨ 关键词:
4️⃣ ❌ -> 2️⃣ ✅
💡 解析:使用 Amazon S3 Transfer Acceleration 配置快速、安全的文件传输
mazon S3 Transfer Acceleration 是一项存储桶级别功能,可在您的客户端和 S3 存储桶之间实现快速、轻松、安全的远距离文件传输。Transfer Acceleration 旨在优化从世界各地传入 S3 存储桶的传输速度。Transfer Acceleration 利用 Amazon CloudFront 中的全球分布式边缘站点。当数据到达某个边缘站点时,数据会被经过优化的网络路径路由至 Amazon S3。
Amazon S3 Transfer Acceleration也使用到了CloudFront的边缘节点,因此和 4️⃣ 的效果差不多。
我依然觉得 4️⃣ 的延迟会更低,毕竟将文件上传到就近的S3存储桶了,但是操作会更复杂,实际场景下我也会改用 2️⃣。
👨👨👦👦 社区讨论:Question says - ” LOWEST latency for content uploads”
Hence Use S3 Transfer Acceleration for the uploads.
七、S3 Glacier Flexible Retrieval
A media company stores movies in Amazon S3. Each movie is stored in a single video file that ranges from 1 GB to 10 GB in size.
The company must be able to provide the streaming content of a movie within 5 minutes of a user purchase. There is higher demand for movies that are less than 20 years old than for movies that are more than 20 years old. The company wants to minimize hosting service costs based on demand.
Which solution will meet these requirements?
- Store all media content in Amazon S3. Use S3 Lifecycle policies to move media data into the Infrequent Access tier when the demand for a movie decreases.
- ✅ Store newer movie video files in S3 Standard. Store older movie video files in S3 Standard-infrequent Access (S3 Standard-IA). When a user orders an older movie, retrieve the video file by using standard retrieval.
- ❌ Store newer movie video files in S3 Intelligent-Tiering. Store older movie video files in S3 Glacier Flexible Retrieval. When a user orders an older movie, retrieve the video file by using expedited retrieval.
- Store newer movie video files in S3 Standard. Store older movie video files in S3 Glacier Flexible Retrieval. When a user orders an older movie, retrieve the video file by using bulk retrieval.
✨ 关键词:
3️⃣ ❌ -> 2️⃣ ✅
💡 解析:了解归档检索选项
- 加速 (Expedited) - 对于除最大归档对象(250MB+)之外的所有其他归档对象,使用加速检索访问的数据通常在 1 到 5 分钟内可用。
加速检索是一项高级特征,按加急请求和检索费率收费。
- 标准 (Standard) - 对于存储在 S3 Glacier Flexible Retrieval 存储类或 S3 Intelligent-Tiering 归档访问层中的对象,标准检索通常在 3-5 小时内完成。
对于存储在 S3 Glacier Deep Archive 存储类或 S3 Intelligent-Tiering 深度归档访问层中的对象,这些检索通常会在 12 小时内完成。- 批量 (Bulk) - 使用 Amazon S3 Glacier 中成本最低的检索选项访问您的数据。通过批量检索,您能够以低廉的成本检索大量数据,甚至达到 PB 级。
对于存储在 S3 Glacier Flexible Retrieval 存储类或 S3 Intelligent-Tiering 存档访问层中的对象,批量检索通常在 5-12 小时内完成。
对于存储在 S3 Glacier Deep Archive 存储类或 S3 Intelligent-Tiering 深度存档访问层中的对象,这些检索通常会在 48 小时内完成。
存储类或层 加速 标准(带批量 Batch 操作) 标准(不带批量 Batch 操作) 批量 S3 Glacier Flexible Retrieval 或 S3 Intelligent-Tiering 归档访问 1 – 5 分钟 数分钟 – 5 小时 3 – 5 小时 5 – 12 小时 S3 Glacier Deep Archive 或 S3 Intelligent-Tiering 深度归档访问 不可用 9 - 12 小时 12 小时内 48 小时内 本题中的文件大小超过 1 GB,因此 3️⃣ 中即使使用加速检索,也无法确保能在 5 分钟内完成。
4️⃣ 的批量检索耗时更长,肯定也不对。
而IA和标准都支持毫秒级访问,因此 2️⃣ 是绝对正确且比 1️⃣ 更便宜的。
👨👨👦👦 社区讨论:Technically,expedited retrieval for files is not guaranteed within 1-5 minutes for files larger than 250 MB+. See:
https://docs.aws.amazon.com/AmazonS3/latest/userguide/restoring-objects-retrieval-options.html
八、LDAP
A company needs to use its on-premises LDAP directory service to authenticate its users to the AWS Management Console. The directory service is not compatible with Security Assertion Markup Language (SAML).
Which solution meets these requirements?
- ❌ Enable AWS IAM Identity Center (AWS Single Sign-On) between AWS and the on-premises LDAP.
- Create an IAM policy that uses AWS credentials, and integrate the policy into LDAP.
- Set up a process that rotates the IAM credentials whenever LDAP credentials are updated.
- ✅ Develop an on-premises custom identity broker application or process that uses AWS Security Token Service (AWS STS) to get short-lived credentials.
✨ 关键词:
1️⃣ ❌ -> 4️⃣ ✅
LDAP 是微软的 Active Directory(AD)目录服务中使用的核心协议(但并非是其专用);而 Active Directory 是一个大型目录服务数据库,包含网络中每一用户帐户的信息。更具体地说,LDAP 是目录访问协议(DAP)的轻量级版本,提供一个中央位置来访问和管理在传输控制协议/互联网协议(TCP/IP)上运行的目录服务,其最新版本是 LDAPv3。
题目中提到它于 SAML 并不兼容:为您的 AWS 资源启用 SAML
安全断言标记语言 2.0 (SAML) 是一种开放联合标准,允许身份提供商 (IdP) 对用户进行身份验证,并将有关用户的身份和安全信息传递给服务提供商 (SP),通常是应用程序或服务。使用 SAML,您可以跨很多启用了 SAML 的应用程序和服务为您的用户启用单点登录体验。用户使用一组凭证通过 IdP 进行一次身份验证,然后无需额外登录即可访问多个应用程序和服务。 由于启用了 SAML 的应用程序将身份验证委托给 IdP,所以当管理员在 IdP 中添加、删除或修改用户信息时,SP 可以自动授予、撤销或更改用户对应用程序和服务的访问范围。
AWS 提供不同的 SAML 解决方案来验证员工、承包商和合作伙伴(劳动力)的 AWS 账户和业务应用程序身份,并增加对面向客户的 Web 和移动应用程序的 SAML 支持。因此这里不能选 1️⃣。
👨👨👦👦 社区讨论:The solution that best meets the requirements.Thisapproach providesa pathway for authenticating LDAP users to AWS without requiring direct LDAP to AWS IAM Identity Center integration orSAML compatibility, offering a flexible and secure method to extend on-premisesauthentication mechanisms to AWS services.
九、AWS Storage Gateway
A pharmaceutical company is developing a new drug. The volume of data that the company generates has grown exponentially over the past few months. The company’s researchers regularly require a subset of the entire dataset to be immediately available with minimal lag. However, the entire dataset does not need to be accessed on a daily basis. All the data currently resides in on-premises storage arrays, and the company wants to reduce ongoing capital expenses.
Which storage solution should a solutions architect recommend to meet these requirements?
- Run AWS DataSyncas a scheduled cron job to migrate the data to an Amazon S3 bucket on an ongoing basis.
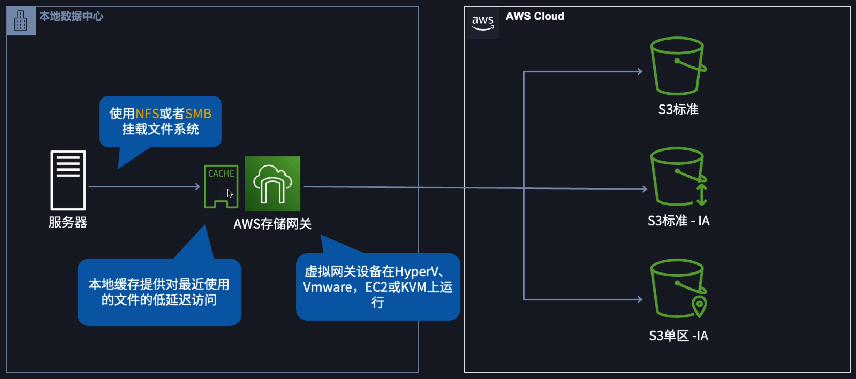
- ❌ Deploy an AWS Storage Gateway file gateway with an Amazon S3 bucket as the target storage. Migrate the data to the Storage Gateway appliance.
- ✅ Deploy an AWS Storage Gateway volume gateway with cached volumes with an Amazon S3 bucket as the target storage. Migrate the data to the Storage Gateway appliance.
- Configure an AWS Site-to-Site VPN connection from the on-premises environment to AWS. Migrate data to an Amazon ElasticFile System (Amazon EFS) file system.
✨ 关键词:
2️⃣ ❌ -> 3️⃣ ✅
💡 解析:
file gateway和volume gateway (cached mode)都支持对频繁访问的文件进行本地缓存:
但是题目中提到了
storage arrays存储整列,这种情况下 3️⃣ 的卷网关更符合。
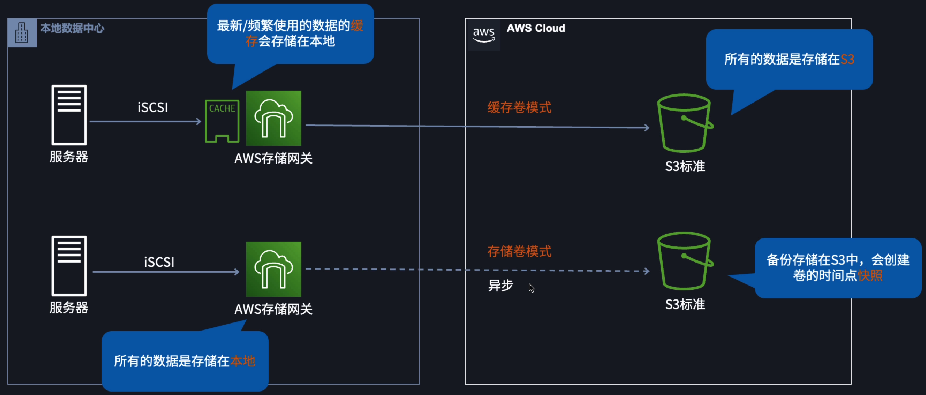
👨👨👦👦 社区讨论:Deploying an AWS Storage Gateway file gateway with an Amazon S3 bucket as the target storage would require the entire dataset to be stored in Amazon S3, which might not be cost-effective considering that onlya subset of the data needs to be accessed regularly. Additionally,accessing data directly from S3 might introduce latency. so correct option is C bcz AWS Storage Gateway volume gateway with cached volumesallows the company to keep frequentlyaccessed data locally on-premises while storing the entire dataset in Amazon S3.This solution provides immediate access to the subset of data with minimal lag,as frequentlyaccessed data is cached locally. It also reduces ongoing capital expensesas it leverages Amazon S3 storage, which is cost-effective.
十、AWS Config
A solutions architect must provide an automated solution for a company’s compliance policy that states security groups cannot include a rule that allows SSH from 0.0.0.0/0. The company needs to be notified if there is any breach in the policy. A solution is needed as soon as possible.
What should the solutions architect do to meet these requirements with the LEAST operational overhead?
- Write an AWS Lambda script that monitors security groups for SSH being open to 0.0.0.0/0 addresses and creates a notification every time it finds one.
- ✅ Enable the restricted-ssh AWS Config managed rule and generate an Amazon Simple Notification Service (Amazon SNS) notification when a noncompliant rule is created.
- Create an IAM role with permissions to globally open security groups and network ACLs. Create an Amazon Simple Notification Service (Amazon SNS) topic to generate a notification every time the role is assumed by a user.
- ❌ Configure a service control policy (SCP) that prevents non-administrative users from creating or editing security groups. Create a notification in the ticketing system when a user requests a rule that needs administrator permissions.
✨ 关键词:
4️⃣ ❌ -> 2️⃣ ✅
💡 解析:
AWS Config中有专门针对 SSH 来源的规则:restricted-ssh检查安全组的传入SSH流量是否可访问。规则是安全组中传入SSH流量的 IP 地址COMPLIANT是否受到限制(0.0.0.0/0 或:: /0 CIDR 除外)。否则,NON_ COMPLIANT。
- 标识符:INCOMING_ SSH _ DISABLED
- 资源类型: AWS::EC2::SecurityGroup
- 触发器类型:配置更改和定期
- AWS 区域: 全部支持 AWS 区域
- 参数:无
之后一些细节的配置限制可以都考虑选择
AWS Config进行实现。
👨👨👦👦 社区讨论:Option B
十一、VPC Lattice service network
Use Amazon Elastic Kubernetes Service (Amazon EKS) with Amazon EC2 worker nodes.
A company has deployed an application in an AWS account. The application consists of microservices that run on AWS Lambda and Amazon Elastic Kubernetes Service (Amazon EKS). A separate team supports each microservice. The company has multiple AWS accounts and wants to give each team its own account for its microservices.
A solutions architect needs to design a solution that will provide service-to-service communication over HTTPS (port 443). The solution also must provide a service registry for service discovery.
Which solution will meet these requirements with the LEAST administrative overhead?
- Create an inspection VPC. Deploy an AWS Network Firewall firewall to the inspection VPC. Attach the inspection VPC to a new transit gateway. Route VPC-to-VPC traffic to the inspection VPC. Apply firewall rules to allow only HTTPS communication.
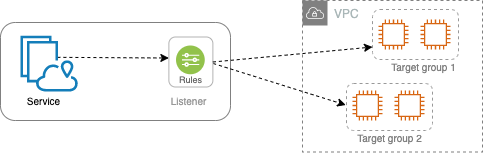
- ✅ Create a VPC Lattice service network. Associate the microservices with the service network. Define HTTPS listeners for each service. Register microservice compute resources as targets. Identify VPCs that need to communicate with the services. Associate those VPCs with the service network.
- Create a Network Load Balancer (NLB) with an HTTPS listener and target groups for each microservice. Create an AWS PrivateLink endpoint service for each microservice. Create an interface VPC endpoint in each VPC that needs to consume that microservice.
- Create peering connections between VPCs that contain microservices. Create a prefix list for each service that requires a connection to a client. Create route tables to route traffic to the appropriate VPC. Create security groups to allow only HTTPS communication.
✨ 关键词:
2️⃣ ✅
Amazon VPC Lattice 是一项完全托管的应用程序网络服务,用于连接、保护和监控应用程序的服务。您可以将 VPC Lattice 与单个虚拟私有云(VPC)一起使用,也可以从一个或多个账户跨多个 VPC 使用。
现代应用程序可以由多个小型模块化服务组成,这些服务通常称为微服务。现代化固然有其优势,但在连接这些微服务时,也可能带来网络复杂性和挑战。例如,如果开发人员分布在不同的团队,他们可能会在多个账户或 VPC 上构建和部署微服务。
👨👨👦👦 社区讨论:VPC Lattice is a completely new way to simplify API communication between services or microservices in one or more AWS accounts.
十二、Amazon ElastiCache for Redis
A company has a mobile game that reads most of its metadata from an Amazon RDS DB instance. As the game increased in popularity, developers noticed slowdowns related to the game’s metadata load times. Performance metrics indicate that simply scaling the database will not help. A solutions architect must explore all options that include capabilities for snapshots, replication, and sub-millisecond response times.
What should the solutions architect recommend to solve these issues?
- Migrate the database to Amazon Aurora with Aurora Replicas.
- Migrate the database to Amazon DynamoDB with global tables.
- ✅ Add an Amazon ElastiCache for Redis layer in front of the database.
- ❌ Add an Amazon ElastiCache for Memcached layer in front of the database.
✨ 关键词:
4️⃣ ❌ -> 3️⃣ ✅
💡 解析:Redis 和 Memcached 都支持亚毫秒级延迟,但是只有 Redis 支持快照和复制功能:比较 Redis OSS 与 Memcached
特点 Memcached Redis 亚毫秒级延迟 是 是 开发人员易用性 是 是 数据分区 是 是 支持多种编程语言 是 是 高级数据结构 - 是 多线程架构 是 - 快照 - 是 复制 - 是 事务处理 - 是 发布/订阅 - 是 Lua 脚本编写 - 是 地理空间支持 - 是
👨👨👦👦 社区讨论:Option C is better as we need replication and snapshots
十三、Amazon Quantum Ledger Database
A company maintains its accounting records in a custom application that runs on Amazon EC2 instances. The company needs to migrate the data to an AWS managed service for development and maintenance of the application data. The solution must require minimal operational support and provide immutable, cryptographically verifiable logs of data changes.
Which solution will meet these requirements MOST cost-effectively?
- Copy the records from the application into an Amazon Redshift cluster.
- Copy the records from the application into an Amazon Neptune cluster.
- Copy the records from the application into an Amazon Timestream database.
- ✅ Copy the records from the application into an Amazon Quantum Ledger Database (Amazon QLDB) ledger.
✨ 关键词:
4️⃣ ✅
💡 解析:什么是 Amazon QLDB?
Amazon Quantum Ledger 数据库 (AmazonQLDB) 是一个完全托管的账本数据库,它提供由中央可信机构拥有的透明、不可变且可加密验证的交易日志。您可以使用 Amazon QLDB 来跟踪所有应用程序数据更改,并维护一段时间内完整且可验证的更改历史记录。
Amazon Neptune 是一项快速、可靠且完全托管式的图数据库服务,可帮助您轻松构建和运行适用于高度互连数据集的应用程序。Neptune 的核心是一个专门打造的高性能图形数据库引擎。该引擎经过优化,可存储数十亿个关系并能以毫秒级延迟进行图形查询。Neptune 支持流行的属性图查询语言 Apache TinkerPop Gremlin 和 Neo4j,以及 W3C 的openCypher查询语言。RDF SPARQL这可让您构建能够高效地浏览高度互联的数据集的查询。Neptune 支持图形用例,如建议引擎、欺诈检测、知识图谱、药物开发和网络安全。
Amazon Timestream 易于管理的时间序列数据库,针对安全性、性能、可用性和可扩展性进行了优化
Amazon Timestream 为从低延迟查询到大规模数据摄取的工作负载提供完全托管、专门构建的时间序列数据库引擎。借助 Timestream for LiveAnalytics,您可以每分钟摄取数十 GB 以上的时间序列数据,并在几秒钟内对数 TB 的时间序列数据运行 SQL 查询,可用性最高达 99.99%。
👨👨👦👦 社区讨论:Option D
十四、Amazon Athena
A company has stored 10 TB of log files in Apache Parquet format in an Amazon S3 bucket. The company occasionally needs to use SQL to analyze the log files.
Which solution will meet these requirements MOST cost-effectively?
- Create an Amazon Aurora MySQL database. Migrate the data from the S3 bucket into Aurora by using AWS Database Migration Service (AWS DMS). Issue SQL statements to the Aurora database.
- ❌ Create an Amazon Redshift cluster. Use Redshift Spectrum to run SQL statements directly on the data in the S3 bucket.
- ✅ Create an AWS Glue crawler to store and retrieve table metadata from the S3 bucket. Use Amazon Athena to run SQL statements directly on the data in the S3 bucket.
- Create an Amazon EMR cluster. Use Apache Spark SQL to run SQL statements directly on the data in the S3 bucket.
✨ 关键词:
2️⃣ ❌ -> 3️⃣ ✅
💡 解析:Redshift Spectrum 介绍
Redshift Spectrum可以帮助客户通过Redshift直接查询S3中的数据。如同Amazon EMR,通过Redshift Spectrum客户可以方便的使用多种开放数据格式并享有低廉的存储成本,同时还可以轻松扩展到上千个计算节点实现数据的提取、筛选、投影、聚合、group、排序等等操作。
Redshift Spectrum采用了无服务器架构,所以客户不需要额外配置或管理任何资源,而只需为Redshift Spectrum的用量付费。需要注意的是,
Athena SQL可以和AWS Glue Data Catalog等进行配合:使用 Athena SQL您可以使用 Athena SQL,借助 AWS Glue Data Catalog(外部 Hive 元存储)或者通过各种预构建连接器对其他数据来源进行联合查询,从而在 Amazon S3 中就地查询数据。
这就是 3️⃣ 中
Glue在做的事情。
而相关的Apache Spark:在 Amazon Athena 中使用 Apache SparkAmazon Athena 让您可以轻松使用 Apache Spark 以交互方式运行数据分析和探索,无需规划、配置或管理资源。在 Athena 上运行 Apache Spark 应用程序意味着,无需额外配置即可提交 Spark 代码进行处理和直接接收结果。您可以使用 Amazon Athena 控制台中简化的笔记本体验,以通过 Python 或 Athena notebook API 开发 Apache Spark 应用程序。Amazon Athena 上的 Apache Spark 无服务器,可通过提供即时计算实现自动按需扩展,从而满足不断变化的数据卷和处理要求。
👨👨👦👦 社区讨论:S3 + SQL = Athena
十五、Cross Account Lambda
A company needs to create an AWS Lambda function that will run in a VPC in the company’s primary AWS account. The Lambda function needs to access files that the company stores in an Amazon Elastic File System (Amazon EFS) file system. The EFS file system is located in a secondary AWS account. As the company adds files to the file system, the solution must scale to meet the demand.
Which solution will meet these requirements MOST cost-effectively?
- Create a new EFS file system in the primary account. Use AWS DataSync to copy the contents of the original EFS file system to the new EFS file system.
- ✅ Create a VPC peering connection between the VPCs that are in the primary account and the secondary account.
- Create a second Lambda function in the secondary account that has a mount that is configured for the file system. Use the primary account’s Lambda function to invoke the secondary account’s Lambda function.
- ❌ Move the contents of the file system to a Lambda layer. Configure the Lambda layer’s permissions to allow the company’s secondary account to use the Lambda layer.
✨ 关键词:
4️⃣ ❌ -> 2️⃣ ✅
💡 解析:从其他EFS服务器挂载文件系统 AWS 账户 或 VPC
您可以使用挂载帮助程序使用NFS客户端和EFS接入点的IAM授权来EFS挂载您的 Amazon EFS 文件系统。默认情况下,EFS挂载助手使用域名服务 (DNS) 来解析您的EFS挂载目标的 IP 地址。如果要从其他账户或虚拟私有云 (VPC) 挂载文件系统,则需要手动解析EFS挂载目标。
接下来,您可以找到有关确定用于NFS客户端的正确EFS挂载目标 IP 地址的说明。您还可以找到有关将客户机配置为使用该 IP 地址挂载EFS文件系统的说明。
可以提供
EFS服务给其他 AWS 账号使用,因此这个问题从Lambda如何访问其他账号中的EFS变为了如何跨VPC访问。顺便看下
Lambda Layer:使用层管理 Lambda 依赖项Lambda 层是包含补充代码或数据的 .zip 文件存档。层通常包含库依赖项、自定义运行时系统或配置文件。
您可能会基于很多原因考虑使用层:
- 减小部署包的大小。与其将所有函数依赖项和函数代码都包含在部署包中,不如将其放在一个层中。这样可以减小部署包的大小并对其进行组织。
- 分离核心函数逻辑与依赖项。借助层,您无需使用函数代码即可更新函数依赖项,反之亦然。这有助于将二者分离,并帮助您专注于函数逻辑。
- 在多个函数之间共享依赖项。创建层后,您可以将其应用到账户中任意数量的函数。如果没有层,则需要在每个单独的部署包中包含相同的依赖项。
- 使用 Lambda 控制台代码编辑器。代码编辑器是快速测试次要功能代码更新的得力工具。但是,如果部署包过大,则无法使用编辑器。使用层可以减小部署包的大小,并解锁代码编辑器的用法。
👨👨👦👦 社区讨论:B -> VPC peering allows the Lambda access secondary account securely and efficiently
A -> redundancy
C -> additional complexity
D -> sharing code librariesYou can configure a function to mount an Amazon EFS file system in another AWS account. Before you mount the file system, you must ensure the following:
VPC peering must be configured, and appropriate routes must be added to the route tables in each VPC.