来源:Amazon AWS Certified Solutions Architect - Associate SAA-C03 Exam
100 题 (No.601 ~ No.700) 只记录了 24 道首次碰到的、错误的或有疑问的题目,仅供自己复习使用。
其中后 65 题与正式考试题量一样,总共耗时 81/(130+30) 分钟,正确率为 47/65。
如果侵权请联系删除。
一、AWS Step Functions Map
A company recently migrated to the AWS Cloud. The company wants a serverless solution for large-scale parallel on-demand processing of a semistructured dataset. The data consists of logs, media files, sales transactions, and IoT sensor data that is stored in Amazon S3. The company wants the solution to process thousands of items in the dataset in parallel.
Which solution will meet these requirements with the MOST operational efficiency?
- Use the AWS Step Functions Map state in Inline mode to process the data in parallel.
- ✅ Use the AWS Step Functions Map state in Distributed mode to process the data in parallel.
- ❌ Use AWS Glue to process the data in parallel.
- Use several AWS Lambda functions to process the data in parallel.
✨ 关键词:
3️⃣ ❌ -> 2️⃣ ✅
💡 解析:在 Step Functions 中为大规模并行工作负载在分布模式下使用 Map 状态
借助 Step Functions,您可以编排大规模的并行工作负载来执行任务,例如按需处理半结构化数据。这些并行工作负载允许您同时处理存储在 Amazon S3 中的大规模数据来源。例如,您可以处理包含大量数据的单个CSV文件JSON或文件。或者,您也可以处理一大组 Amazon S3 对象。
如果您未指定,Step Functions 将并行运行 1 万个并行子工作流执行。
在 Step Functions 工作流程中以内联模式使用 Map 状态
默认情况下,Map 状态以内联模式运行。在内联模式下,Map 状态仅接受JSON数组作为输入。它接收来自工作流中上一步的数组。在此模式下,Map 状态的每次迭代都在包含 Map 状态的工作流的上下文中运行。Step Functions 会将这些迭代的执行历史记录添加到父工作流的执行历史记录中。
在此模式下,Map 状态最多支持 40 次并发迭代。
1️⃣ 选项是流水线类型(串联),而 2️⃣ 是并行。 。。
👨👨👦👦 社区讨论:AWS Step Functions allows you to orchestrate and scale distributed processing using the Map state. The Map state can process items in a large dataset in parallel by distributing the work across multiple resources.
Using the Map state in Distributed mode will automatically handle the parallel processing and scaling. Step Functions will add more workers to process the data as needed.
Step Functions is serverless so there are no servers to manage. It will scale up and down automatically based on demand.
二、AWS WAF
A company has an application that serves clients that are deployed in more than 20.000 retail storefront locations around the world. The application consists of backend web services that are exposed over HTTPS on port 443. The application is hosted on Amazon EC2 instances behind an Application Load Balancer (ALB). The retail locations communicate with the web application over the public internet. The company allows each retail location to register the IP address that the retail location has been allocated by its local ISP.
The company’s security team recommends to increase the security of the application endpoint by restricting access to only the IP addresses registered by the retail locations.
What should a solutions architect do to meet these requirements?
- ✅ Associate an AWS WAF web ACL with the ALB. Use IP rule sets on the ALB to filter traffic. Update the IP addresses in the rule to include the registered IP addresses.
- ❌ Deploy AWS Firewall Manager to manage the ALConfigure firewall rules to restrict traffic to the ALModify the firewall rules to include the registered IP addresses.
- Store the IP addresses in an Amazon DynamoDB table. Configure an AWS Lambda authorization function on the ALB to validate that incoming requests are from the registered IP addresses.
- Configure the network ACL on the subnet that contains the public interface of the ALB. Update the ingress rules on the network ACL with entries for each of the registered IP addresses.
✨ 关键词:
2️⃣ ❌ -> 1️⃣ ✅
💡 解析:AWS Firewall Manager 和 AWS Organizations
AWS Firewall Manager 是一项安全管理服务,您可以使用它集中配置和管理组织中AWS 账户和应用程序的防火墙规则。使用 Firewall Manager,您可以轻松地推行 AWS WAF 规则,创建 AWS Shield Advanced 保护、配置和审计 Amazon Virtual Private Cloud(Amazon VPC)安全组,并部署 AWS Network Firewall。使用 Firewall Manager 一次设置好保护措施,并让它们跨组织中的所有账户和资源自动应用,即使添加新资源和账户时也是如此。
AWS Firewall Manager 是一种安全性管理工具,可跨帐户和应用程序集中设定和管理 AWS WAF 规则。使用 Firewall Manager,您可一次性的向 Application Load Balancer 和 Amazon CloudFront 分配推送 WAF 规则,且可确保新应用程序和资源从一开始就符合通用的安全性规则集。
使用
AWS Firewall Manager当然也能够解决问题,但是这里 2️⃣ 说的不清不楚的。
1️⃣ 就很具体:在 AWS WAF 中使用 Web ACLWeb ACL 可让您对受保护资源响应的所有 HTTP(S) Web 请求进行精细控制。您可以保护 Amazon CloudFront、Amazon API Gateway、应用程序负载均衡器 AWS AppSync、Amazon Cognito AWS App Runner 和 AWS Verified Access 资源。
您可以使用如下条件来允许或阻止请求:
- 请求的 IP 地址源
- 请求的源国家/地区
- 部分请求中的字符串匹配或正则表达式匹配
- 请求特定部分的大小
- 检测恶意 SQL 代码或脚本
并且它总共支持 100 条规则,每个可以包含 10,000 个 IP 地址源,符合题目需求。
👨👨👦👦 社区讨论:WAF, you can have 100 “rule sets” per account, each with up to 10,000 IP addresses.
https://docs.aws.amazon.com/waf/latest/developerguide/limits.html
三、AWS Lake Formation
A company is building a data analysis platform on AWS by using AWS Lake Formation. The platform will ingest data from different sources such as Amazon S3 and Amazon RDS. The company needs a secure solution to prevent access to portions of the data that contain sensitive information.
Which solution will meet these requirements with the LEAST operational overhead?
- Create an IAM role that includes permissions to access Lake Formation tables.
- ✅ Create data filters to implement row-level security and cell-level security.
- Create an AWS Lambda function that removes sensitive information before Lake Formation ingests the data.
- Create an AWS Lambda function that periodically queries and removes sensitive information from Lake Formation tables.
✨ 关键词:
2️⃣ ✅
AWS Lake Formation 帮助您集中管理、保护和全球共享用于分析和机器学习的数据。您可以对 Amazon Simple Storage Service (Amazon S3) 上的数据湖数据及其在 AWS Glue Data Catalog 中的元数据进行精细访问控制 (fine-grained access control)。
安全管理
- 定义和管理访问控制
- 混合访问模式
- 实施审计日志记录
- 行和单元格级别安全功能
- 基于标签的访问控制
- 跨账户访问
👨👨👦👦 社区讨论:The key reasons are:
Lake Formation data filters allow restricting access to rows or cells in data tables based on conditions. This allows preventing access to sensitive data.
Data filters are implemented within Lake Formation and do not require additional coding or Lambda functions. Lambda functions to pre-process data or purge tables would require ongoing development and maintenance.
IAM roles only provide user-level permissions, not row or cell level security.
Data filters give granular access control over Lake Formation data with minimal configuration, avoiding complex custom code.
四、EKS secrets
A company uses Amazon Elastic Kubernetes Service (Amazon EKS) to run a container application. The EKS cluster stores sensitive information in the Kubernetes secrets object. The company wants to ensure that the information is encrypted.
Which solution will meet these requirements with the LEAST operational overhead?
- Use the container application to encrypt the information by using AWS Key Management Service (AWS KMS).
- ✅ Enable secrets encryption in the EKS cluster by using AWS Key Management Service (AWS KMS).
- Implement an AWS Lambda function to encrypt the information by using AWS Key Management Service (AWS KMS).
- ❌ Use AWS Systems Manager Parameter Store to encrypt the information by using AWS Key Management Service (AWS KMS).
✨ 关键词:
4️⃣ ❌ -> 2️⃣ ✅
💡 解析:在现有集群上使用 AWS KMS 加密 Kubernetes 密钥
如果启用密钥加密,将使用您选择的 AWS KMS 对 Kubernetes 密钥加密。KMS 密钥必须符合以下条件:
- 对称
- 可以加密和解密数据
- 在与集群相同的 AWS 区域中创建
- 如果 KMS 密钥是在其他账户中创建的,则 IAM 主体必须拥有对 KMS 密钥的访问权限。
👨👨👦👦 社区讨论:EKS supports encrypting Kubernetes secrets at the cluster level using AWS KMS keys. This provides an automated way to encrypt secrets.
Enabling this feature requires minimal configuration changes to the EKS cluster and no code changes.
Other options like using Lambda functions or modifying the application code to encrypt secrets require additional development effort and overhead.
Systems Manager Parameter Store could store encrypted parameters but does not natively integrate with EKS to encrypt Kubernetes secrets.
The EKS secrets encryption feature leverages AWS KMS without the need to directly call KMS APIs from the application.
五、CloudWatch and EKS
A company runs a critical, customer-facing application on Amazon Elastic Kubernetes Service (Amazon EKS). The application has a microservices architecture. The company needs to implement a solution that collects, aggregates, and summarizes metrics and logs from the application in a centralized location.
Which solution meets these requirements?
- ❌ Run the Amazon CloudWatch agent in the existing EKS cluster. View the metrics and logs in the CloudWatch console.
- Run AWS App Mesh in the existing EKS cluster. View the metrics and logs in the App Mesh console.
- Configure AWS CloudTrail to capture data events. Query CloudTrail by using Amazon OpenSearch Service.
- ✅ Configure Amazon CloudWatch Container Insights in the existing EKS cluster. View the metrics and logs in the CloudWatch console.
✨ 关键词:
1️⃣ ❌ -> 4️⃣ ✅
💡 解析:安装 CloudWatch 代理
CloudWatch 代理在 Amazon Linux 2023 和 Amazon Linux 2 中,可作为软件包使用。如果您使用其中一个操作系统,则可以通过输入以下命令来安装该软件包。
使用 CloudWatch Container Insights 可以从容器化应用程序和微服务中收集、聚合和汇总指标与日志。Container Insights 可用于 Amazon EC2 上的 Amazon Elastic Container Service (Amazon ECS)、Amazon Elastic Kubernetes Service (Amazon EKS) 和 Kubernetes 平台。Container Insights 支持从部署在 AWS Fargate 上的集群中收集针对 Amazon ECS 和 Amazon EKS 的指标。
Agent 是部署在实例上的,Container Insights 是部署在容器和集群中的。
👨👨👦👦 社区讨论:Use CloudWatch Container Insights to collect, aggregate, and summarize metrics and logs from your containerized applications and microservices. Container Insights is available for Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Kubernetes Service (Amazon EKS), and Kubernetes platforms on Amazon EC2. Container Insights supports collecting metrics from clusters deployed on AWS Fargate for both Amazon ECS and Amazon EKS.
六、Security
A company has deployed its newest product on AWS. The product runs in an Auto Scaling group behind a Network Load Balancer. The company stores the product’s objects in an Amazon S3 bucket.
The company recently experienced malicious attacks against its systems. The company needs a solution that continuously monitors for malicious activity in the AWS account, workloads, and access patterns to the S3 bucket. The solution must also report suspicious activity and display the information on a dashboard.
Which solution will meet these requirements?
- Configure Amazon Macie to monitor and report findings to AWS Config.
- ❌ Configure Amazon Inspector to monitor and report findings to AWS CloudTrail.
- ✅ Configure Amazon GuardDuty to monitor and report findings to AWS Security Hub.
- Configure AWS Config to monitor and report findings to Amazon EventBridge.
✨ 关键词:
2️⃣ ❌ -> 3️⃣ ✅
💡 解析:什么是 Amazon Inspector? - 针对 AWS 服务的漏洞扫描
Amazon Inspector 是一项自动化漏洞管理服务,可近乎实时地持续扫描 Amazon Elastic Compute Cloud(EC2)、Amazon Lambda 函数以及 Amazon ECR 中的容器映像以及持续集成和持续交付(CI/CD)工具中的软件漏洞和意外网络暴露。
什么是 AWS CloudTrail? - 记录 AWS 账号操作
AWS CloudTrail 是一项 AWS 服务,可帮助您实现 AWS 账户 的运营和风险审计、治理和合规性。用户、角色或 AWS 服务执行的操作将记录为 CloudTrail 中的事件。事件包括在 AWS Management Console、AWS Command Line Interface 和 AWS 开发工具包和 API 中执行的操作。
什么是 Amazon GuardDuty? - 监控恶意活动,保护账号、工作负载和数据
Amazon GuardDuty 是一项威胁检测服务,用于持续监控、分析和处理 AWS 环境中的 AWS 数据来源和日志。GuardDuty 使用恶意 IP 地址和域列表、文件哈希值和机器学习(ML)模型等威胁情报源,来识别 AWS 环境中的可疑和潜在有恶意的活动。
什么是 AWS Security Hub? - 安全状态大屏
AWS Security Hub 为您提供了 AWS 中安全状态的全面视图,可帮助您评测您的 AWS 环境是否符合安全行业标准和最佳实践。
Security Hub 可跨 AWS 账户、AWS 服务、和受支持的第三方产品收集安全数据,并可帮助您分析安全趋势,以及确定最高优先级的安全问题。
👨👨👦👦 社区讨论:- Amazon Inspector = automated vulnerability management service
- Amazon GuardDuty = threat detection service that monitors for malicious activity and anomalous behavior to protect AWS accounts, workloads, and data.
七、Amazon Route 53
A company is hosting a website behind multiple Application Load Balancers. The company has different distribution rights for its content around the world. A solutions architect needs to ensure that users are served the correct content without violating distribution rights.
Which configuration should the solutions architect choose to meet these requirements?
- Configure Amazon CloudFront with AWS WAF.
- Configure Application Load Balancers with AWS WAF
- ✅ Configure Amazon Route 53 with a geolocation policy
- ❌ Configure Amazon Route 53 with a geoproximity routing policy
✨ 关键词:
4️⃣ ❌ -> 3️⃣ ✅
💡 解析:选择路由策略
- 地理位置路由策略 (Geolocation routing policy) - 如果您想要根据用户的位置来路由流量,则可以使用该策略。在私有托管区域中,可以使用地理位置路由创建记录。
- 地理位置临近度路由策略 (Geoproximity routing policy) - 用于根据资源的位置来路由流量,以及(可选)将流量从一个位置中的资源转移到另一个位置中的资源。在私有托管区中,可以使用地理位置临近度路由创建记录。
👨👨👦👦 社区讨论:Geolocation routing policy — Use when you want to route traffic based on the location of users
Geo-proximity routing policy — Use when you want to route traffic based on the location of your resourcesand optionally switch resource traffic at one location to resourceselsewhere.
八、S3 Storage Lens
A global company runs its applications in multiple AWS accounts in AWS Organizations. The company’s applications use multipart uploads to upload data to multiple Amazon S3 buckets across AWS Regions. The company wants to report on incomplete multipart uploads for cost compliance purposes.
Which solution will meet these requirements with the LEAST operational overhead?
- Configure AWS Config with a rule to report the incomplete multipart upload object count.
- ❌ Create a service control policy (SCP) to report the incomplete multipart upload object count.
- ✅ Configure S3 Storage Lens to report the incomplete multipart upload object count.
- Create an S3 Multi-Region Access Point to report the incomplete multipart upload object count.
✨ 关键词:
2️⃣ ❌ -> 3️⃣ ✅
💡 解析:了解 Amazon S3 Storage Lens 存储统计管理工具
Amazon S3 Storage Lens 存储统计管理工具是一项云存储分析功能,您可以使用它在整个组织范围内了解对象存储的使用情况和活动。
- 您可以使用 S3 Storage Lens 存储统计管理工具指标生成摘要见解,例如,了解整个组织中有多少存储空间,或增长最快的桶和前缀是哪些。
- 您还可以使用 S3 Storage Lens 存储统计管理工具指标来识别成本优化机会,实施数据保护和安全最佳实践,并提高应用程序工作负载的性能。例如,您可以识别没有 S3 生命周期规则的桶,使超过 7 天的未完成分段上传过期。
- 您还可以识别未遵循数据保护最佳实践(例如使用 S3 复制或 S3 版本控制)的桶。S3 Storage Lens 存储统计管理工具还分析指标以提供上下文建议,您可以使用这些建议来优化存储成本并应用最佳实践来保护数据。
👨👨👦👦 社区讨论:S3 storage lenses can be used to find incomplete multipart uploads:
https://aws.amazon.com/blogs/aws-cloud-financial-management/discovering-and-deleting-incomplete-multipart-uploads-to-lower-amazon-s3-costs/
九、Amazon Neptune and Amazon Quantum Ledger Database
A social media company wants to store its database of user profiles, relationships, and interactions in the AWS Cloud. The company needs an application to monitor any changes in the database. The application needs to analyze the relationships between the data entities and to provide recommendations to users.
Which solution will meet these requirements with the LEAST operational overhead?
- Use Amazon Neptune to store the information. Use Amazon Kinesis Data Streams to process changes in the database.
- ✅ Use Amazon Neptune to store the information. Use Neptune Streams to process changes in the database.
- Use Amazon Quantum Ledger Database (Amazon QLDB) to store the information. Use Amazon Kinesis Data Streams to process changes in the database.
- ❌ Use Amazon Quantum Ledger Database (Amazon QLDB) to store the information. Use Neptune Streams to process changes in the database.
✨ 关键词:
4️⃣ ❌ -> 2️⃣ ✅
💡 解析:什么是 Amazon Neptune?
Amazon Neptune 是一项快速、可靠且完全托管式的图数据库服务,可帮助您轻松构建和运行适用于高度互连数据集的应用程序。Neptune 的核心是一个专门打造的高性能图形数据库引擎。该引擎经过优化,可存储数十亿个关系并能以毫秒级延迟进行图形查询。Neptune 支持流行的属性图查询语言 Apache TinkerPop Gremlin 和 Neo4j,以及 W3C 的openCypher查询语言。RDF SPARQL这可让您构建能够高效地浏览高度互联的数据集的查询。Neptune 支持图形用例,如建议引擎、欺诈检测、知识图谱、药物开发和网络安全。
Neptune Streams 以完全托管式方式按发生顺序即时记录对图形所做的每一个更改。启用 Streams 后,Neptune 将负责管理可用性、备份、安全性和到期等事宜。
在许多使用案例中,都可能需要即时捕获对图的更改,下面是一些示例:
- 您可能希望在发生某些更改时应用程序能够自动通知用户。
- 您可能还想在其他数据存储中维护图表数据的最新版本,例如亚马逊 OpenSearch 服务、亚马逊或亚马逊 ElastiCache简单存储服务 (Amazon S3)。
终止支持通知:现有客户可以在2025年7月31日终止支持QLDB之前使用亚马逊。有关更多详细信息,请参阅将亚马逊QLDB账本迁移到亚马逊 Aurora PostgreSQL。
Amazon Quantum Ledger 数据库 (AmazonQLDB) 是一个完全托管的账本数据库,它提供由中央可信机构拥有的透明、不可变且可加密验证的交易日志。您可以使用 Amazon QLDB 来跟踪所有应用程序数据更改,并维护一段时间内完整且可验证的更改历史记录。
👨👨👦👦 社区讨论:Relationships between entities = Graph data = Neptune
十、FSx for Lustre deployment options
A weather forecasting company needs to process hundreds of gigabytes of data with sub-millisecond latency. The company has a high performance computing (HPC) environment in its data center and wants to expand its forecasting capabilities.
A solutions architect must identify a highly available cloud storage solution that can handle large amounts of sustained throughput. Files that are stored in the solution should be accessible to thousands of compute instances that will simultaneously access and process the entire dataset.
What should the solutions architect do to meet these requirements?
- ❌ Use Amazon FSx for Lustre scratch file systems.
- ✅ Use Amazon FSx for Lustre persistent file systems.
- Use Amazon ElasticFile System (Amazon EFS) with Bursting Throughput mode.
- Use Amazon ElasticFile System (Amazon EFS) with Provisioned Throughput mode.
✨ 关键词:highly available cloud storage solution
1️⃣ ❌ -> 2️⃣ ✅
Amazon FSx for Lustre 提供两个文件系统部署选项:临时 (scratch) 和持久 (persistent)。
- 临时 (scratch) 文件系统 - 临时文件系统专为临时存储和短期数据处理而设计。如果文件服务器出现故障,则不会复制数据,也不会持久保留数据。临时文件系统提供高突增吞吐量,高达基准吞吐量(每 TiB 存储容量 200MBps)的六倍 当需要对处理量繁重的短期工作负载使用成本优化的存储时,可以使用临时文件系统。
- 持久性 (persistent) 文件系统 - 持久性文件系统专为长期存储和工作负载而设计。文件服务器具有高可用性,并且数据在文件系统所在的同一可用区内自动复制。附加到文件服务器的数据卷独立于所附加的文件服务器进行复制。 对于长期存储以及侧重于吞吐量的工作负载,且这些工作负载将长时间运行或无限期运行,并可能对可用性中断很敏感,在这两种情况下,使用持久性文件系统。
👨👨👦👦 社区讨论:HPC + the entire dataset -> FSx Lustre presistence
十一、Tag the resources
A company maintains an Amazon RDS database that maps users to cost centers. The company has accounts in an organization in AWS Organizations. The company needs a solution that will tag all resources that are created in a specific AWS account in the organization. The solution must tag each resource with the cost center ID of the user who created the resource.
Which solution will meet these requirements?
- Move the specific AWS account to a new organizational unit (OU) in Organizations from the management account. Create a service control policy (SCP) that requires all existing resources to have the correct cost center tag before the resources are created. Apply the SCP to the new OU.
- ✅ Create an AWS Lambda function to tag the resources after the Lambda function looks up the appropriate cost center from the RDS database. Configure an Amazon EventBridge rule that reacts to AWS CloudTrail events to invoke the Lambda function.
- ❌ Create an AWS CloudFormation stack to deploy an AWS Lambda function. Configure the Lambda function to look up the appropriate cost center from the RDS database and to tag resources. Create an Amazon EventBridge scheduled rule to invoke the CloudFormation stack.
- Create an AWS Lambda function to tag the resources with a default value. Configure an Amazon EventBridge rule that reacts to AWS CloudTrail events to invoke the Lambda function when a resource is missing the cost center tag.
✨ 关键词:
3️⃣ ❌ -> 2️⃣ ✅
💡 解析:使用 AWS Organizations 的标签进行基于属性的访问控制
检查附加到请求中指定资源的标签
当您使用AWS Management Console、AWS Command Line Interface(AWS CLI)或其中一个 AWS SDK 发出请求时,您可以指定要通过该请求访问的资源。无论您是试图列出给定类型的可用资源、读取资源还是写入、修改或更新资源,都可以将要访问的资源指定为请求中的参数。此类请求由您附加到用户和角色的 IAM 权限策略控制。在这些策略中,您可以比较附加到请求资源的标签,并根据这些标签的键和值选择允许或拒绝访问。
SCP可以对操作的资源进行标签检查,但是不能为其打上标签,这就是为什么 1️⃣ 是错的。
👨👨👦👦 社区讨论:A policy cannot look up “the cost center ID of the user who created the resource”, we need Lambda to do that.Thus A is out.
C would work but runs on a schedule which doesn’t make sense (and we would temporarily have untagged resources).
D tags resources “with a default value” which is not what we want.
十二、Customer-managed prefix lists
A company has multiple AWS accounts in an organization in AWS Organizations that different business units use. The company has multiple offices around the world. The company needs to update security group rules to allow new office CIDR ranges or to remove old CIDR ranges across the organization. The company wants to centralize the management of security group rules to minimize the administrative overhead that updating CIDR ranges requires.
Which solution will meet these requirements MOST cost-effectively?
- Create VPC security groups in the organization’s management account. Update the security groups when a CIDR range update is necessary.
- ✅ Create a VPC customer managed prefix list that contains the list of CIDRs. Use AWS Resource Access Manager (AWS RAM) to share the prefix list across the organization. Use the prefix list in the security groups across the organization.
- Create an AWS managed prefix list. Use an AWS Security Hub policy to enforce the security group update across the organization. Use an AWS Lambda function to update the prefix list automatically when the CIDR ranges change.
- ❌ Create security groups in a central administrative AWS account. Create an AWS Firewall Manager common security group policy for the whole organization. Select the previously created security groups as primary groups in the policy.
✨ 关键词:
4️⃣ ❌ -> 2️⃣ ✅
💡 解析:使用托管前缀列表 (managed prefix lists) 合并和管理网络 CIDR 块
托管式前缀列表是包含一个或多个 CIDR 块的集合。您可以使用前缀列表更轻松地配置和维护安全组和路由表。
您可以根据经常使用的 IP 地址创建前缀列表,并将它们作为安全组规则和路由中的集合引用,而不是单独引用它们。
例如,您可以将具有不同 CIDR 块但使用相同端口和协议的安全组规则整合到使用前缀列表的单个规则中。如果您扩展网络并需要允许来自另一个 CIDR 块的流量,则可以更新相关的前缀列表,使用该前缀列表的所有安全组都将更新。
您还可以使用资源访问管理器(RAM)与其他 AWS 账户一起使用托管式前缀列表。前缀列表有两种类型:
- 客户管理的前缀列表 (Customer-managed prefix lists) — 您定义和管理的 IP 地址范围集。您可以与其他AWS账户共享您的前缀列表,使这些账户能够在自己的资源中引用该前缀列表。
- AWS托管前缀列表 (AWS-managed prefix lists) — AWS服务的 IP 地址范围集。您无法创建、修改、共享或删除AWS托管的前缀列表。
👨👨👦👦 社区讨论:A managed prefix list isa set of one or more CIDR blocks. You can use prefix lists to make it easier to configure and maintain your security groupsand route tables. You can create a prefix list from the IP addresses that you frequently use,and reference them asa set in security group rulesand routes instead of referencing them individually. If you scale your networkand need to allow traffic from another CIDR block, you can update the relevant prefix list and all security groups that use the prefix list are updated. You can also use managed prefix lists with other AWS accounts using Resource Access Manager (RAM).
十三、KMS
A company is developing a new application on AWS. The application consists of an Amazon Elastic Container Service (Amazon ECS) cluster, an Amazon S3 bucket that contains assets for the application, and an Amazon RDS for MySQL database that contains the dataset for the application. The dataset contains sensitive information. The company wants to ensure that only the ECS cluster can access the data in the RDS for MySQL database and the data in the S3 bucket.
Which solution will meet these requirements?
- ✅ Create a new AWS Key Management Service (AWS KMS) customer managed key to encrypt both the S3 bucket and the RDS for MySQL database. Ensure that the KMS key policy includes encrypt and decrypt permissions for the ECS task execution role.
- Create an AWS Key Management Service (AWS KMS) AWS managed key to encrypt both the S3 bucket and the RDS for MySQL database. Ensure that the S3 bucket policy specifies the ECS task execution role as a user.
- ❌ Create an S3 bucket policy that restricts bucket access to the ECS task execution role. Create a VPC endpoint for Amazon RDS for MySQL. Update the RDS for MySQL security group to allow access from only the subnets that the ECS cluster will generate tasks in.
- Create a VPC endpoint for Amazon RDS for MySQL. Update the RDS for MySQL security group to allow access from only the subnets that the ECS cluster will generate tasks in. Create a VPC endpoint for Amazon S3. Update the S3 bucket policy to allow access from only the S3 VPC endpoint.
✨ 关键词:
3️⃣ ❌ -> 1️⃣ ✅
💡 解析:只有
ECS集群可以访问S3和RDS数据库。
3️⃣ 和 4️⃣ 的问题都在允许子网或VPC内的所有实例访问S3或RDS。
2️⃣ 没有限制RDS。
只能选 1️⃣。
社区争议很大。
👨👨👦👦 社区讨论:We’re asked to restrict access to both, RDS and S3, to “the ECS cluster” (not to a subnet orendpoint).
Not B: Does not restrict RDS at all. Wording aboutS3 is unusual.
Not C: Would workforS3, but would allow RDS access from whole subnet which may contain other resources besides the ECS cluster.
Not D: Would allow RDS access from whole subnet which may contain other resources besides the ECS cluster. Would allow S3 access from VPC endpoint which might be accessed by other resources besides the ECS cluster.
十四、Elastic Beanstalk
A company has a web application that runs on premises. The application experiences latency issues during peak hours. The latency issues occur twice each month. At the start of a latency issue, the application’s CPU utilization immediately increases to 10 times its normal amount.
The company wants to migrate the application to AWS to improve latency. The company also wants to scale the application automatically when application demand increases. The company will use AWS Elastic Beanstalk for application deployment. Which solution will meet these requirements?
- ✅ Configure an Elastic Beanstalk environment to use burstable performance instances in unlimited mode. Configure the environment to scale based on requests.
- Configure an Elastic Beanstalk environment to use compute optimized instances. Configure the environment to scale based on requests.
- Configure an Elastic Beanstalk environment to use compute optimized instances. Configure the environment to scale on a schedule.
- Configure an Elastic Beanstalk environment to use burstable performance instances in unlimited mode. Configure the environment to scale on predictive metrics.
✨ 关键词:
1️⃣ ✅
💡 解析:实例指标
Web 服务器指标
- 过去 10 秒内 Web 服务器每秒处理的请求数。
- 过去 10 秒内导致每种类型的状态代码的请求数。
- 过去 10 秒内最慢的 x% 的请求的平均延迟,其中 x 是数字与 100 之差。
操作系统指标
- 自启动实例以来经过的时间量。
- (只有 Linux 系统支持)过去一分钟和五分钟时段内的负载平均值。
- 过去 10 秒内 CPU 在每个状态中耗费的时间的百分比。
👨👨👦👦 社区讨论:“Scale on predictive metrics” does not sound like something that Beanstalkcan do. In EC2 you can create a “predictive scaling policy”, but apparently this is not supported by Beanstalk.That would rule out D.
We have no indication that the application is CPU-intensive in general. If CPU utilization “increases to 10 times its normal amount” then the “normal amount” cannot be higher than 10 %.This would rule out B and C.
十五、Gateway endpoints and interface endpoints
A company is moving its data and applications to AWS during a multiyear migration project. The company wants to securely access data on Amazon S3 from the company’s AWS Region and from the company’s on-premises location. The data must not traverse the internet. The company has established an AWS Direct Connect connection between its Region and its on-premises location.
Which solution will meet these requirements?
- ❌ Create gateway endpoints for Amazon S3. Use the gateway endpoints to securely access the data from the Region and the on-premises location.
- Create a gateway in AWS Transit Gateway to access Amazon S3 securely from the Region and the on-premises location.
- ✅ Create interface endpoints for Amazon S3. Use the interface endpoints to securely access the data from the Region and the on-premises location.
- Use an AWS Key Management Service (AWS KMS) key to access the data securely from the Region and the on-premises location.
✨ 关键词:
1️⃣ ❌ -> 3️⃣ ✅
💡 解析:适用于 Amazon S3 的网关端点
Amazon S3 同时支持网关端点和接口端点。
- 借助网关端点,您可以从 VPC 访问 Amazon S3,而无需为 VPC 配备互联网网关或 NAT 设备,也无需任何额外费用。
但是,网关端点不允许从本地网络、其他 AWS 区域的对等 VPC 或通过传输网关进行访问。- 必须使用接口端点(以允许从本地网络、其他 AWS 区域的对等 VPC 或通过传输网关进行访问),后者需要额外付费。
网关终端节点不支持端到端,接口终端节点支持。
👨👨👦👦 社区讨论:Ans is C: >>You can access Amazon S3 from your VPC using gateway VPC endpoints. After you create the gatewayendpoint, you can add it asa target in your route table for traffic destined from your VPC to Amazon S3.
There is no additional charge for using gatewayendpoints. Amazon S3 supports both gatewayendpointsand interface endpoints. With a gatewayendpoint, you can access Amazon S3 from your VPC, without requiring an internet gateway or NAT device for your VPC,and with no additional cost. However, gatewayendpoints do not allow access from on-premises networks, from peered VPCs in other AWS Regions, or through a transit gateway. For those scenarios, you must use an interface endpoint, which isavailable for an additional cost. For more information, see Types of VPC endpoints for Amazon S3 in the Amazon S3 User Guide.
https://docs.aws.amazon.com/vpc/latest/privatelink/vpc-endpoints-s3.html
十六、DynamoDB mode
A company performs tests on an application that uses an Amazon DynamoDB table. The tests run for 4 hours once a week. The company knows how many read and write operations the application performs to the table each second during the tests. The company does not currently use DynamoDB for any other use case. A solutions architect needs to optimize the costs for the table.
Which solution will meet these requirements?
- ❌ Choose on-demand mode. Update the read and write capacity units appropriately.
- ✅ Choose provisioned mode. Update the read and write capacity units appropriately.
- Purchase DynamoDB reserved capacity for a 1-year term.
- Purchase DynamoDB reserved capacity for a 3-year term.
✨ 关键词:
1️⃣ ❌ -> 2️⃣ ✅
💡 解析:公司对每周运行 4 小时的
DynamoDB有一定的使用量预测。
DynamoDB on-demand and provisioned capacity在无服务器应用程序中,您通常会使用亚马逊的完全托管 NoSQL 数据库服务 DynamoDB。亚马逊 DynamoDB 有两种定价模式:按需容量模式定价和配置容量模式定价。
- 使用预配置容量 (on-demand mode),您需要为 DynamoDB 表的读写容量单位支付费用。而按需使用 DynamoDB 时,您需要为应用程序在表上执行的数据读写按请求付费。 在按需容量模式下,DynamoDB 会根据应用程序在表上执行的数据读写来收费。您不需要指定您期望应用程序执行的读写吞吐量,因为 DynamoDB 会根据工作负载的增减即时调整。
- 在调配容量模式 (provisioned mode) 下,您可以指定应用程序每秒所需的读写量,并据此计费。此外,如果您能预测您的容量需求,您还可以预留一部分 DynamoDB 预配置容量,从而进一步优化您的成本。 通过预留容量,您还可以使用自动缩放功能,根据指定的利用率自动调整表的容量,以确保应用程序的性能,并降低潜在成本。要在 DynamoDB 中配置自动缩放,除了目标利用率百分比外,还要设置读写容量的最小和最大级别。
👨👨👦👦 社区讨论:With provisioned capacity mode, you specify the number of readsand writes per second that you expect your application to require,and you are billed based on that. Furthermore if you can forecast your capacity requirements you can also reserve a portion of DynamoDB provisioned capacityand optimize your costseven further.
https://docs.aws.amazon.com/wellarchitected/latest/serverless-applications-lens/capacity.html
十七、AWS Glue crawler and data analytics
A marketing company receives a large amount of new clickstream data in Amazon S3 from a marketing campaign. The company needs to analyze the clickstream data in Amazon S3 quickly. Then the company needs to determine whether to process the data further in the data pipeline.
Which solution will meet these requirements with the LEAST operational overhead?
- Create external tables in a Spark catalog. Configure jobs in AWS Glue to query the data.
- ✅ Configure an AWS Glue crawler to crawl the data. Configure Amazon Athena to query the data.
- Create external tables in a Hive metastore. Configure Spark jobs in Amazon EMR to query the data.
- ❌ Configure an AWS Glue crawler to crawl the data. Configure Amazon Kinesis Data Analytics to use SQL to query the data.
✨ 关键词:
4️⃣ ❌ -> 2️⃣ ✅
💡 解析:
Kinesis Data Analytics是用以处理数据的,并且即将被停用。
适用于 SQL 应用程序的 Amazon Kinesis Data Analytics:工作原理Kinesis Data Analytics 应用程序持续实时读取和处理流数据。您可以使用 SQL 编写应用程序代码来处理传入的流数据并生成输出。然后,Kinesis Data Analytics 会将输出写入到配置的目标中。以下示意图说明典型的应用程序架构。
除了这些基本属性外,每个应用程序还包括:
- Input - 应用程序的流式传输源。
- 应用程序代码 - 应用程序的流式传输源。
- 输出 - 应用程序的流式传输源。
👨👨👦👦 社区讨论:You’ve come a loooong way…keep going…
Kinesis Data Analytics applications continuously read and process streaming data in real time.
Data is already at rest in S3. So Athena.
https://docs.aws.amazon.com/kinesisanalytics/latest/dev/how-it-works.html
十八、RDS auto scaling is not a thing
A company runs a web application on Amazon EC2 instances in an Auto Scaling group. The application uses a database that runs on an Amazon RDS for PostgreSQL DB instance. The application performs slowly when traffic increases. The database experiences a heavy read load during periods of high traffic.
Which actions should a solutions architect take to resolve these performance issues? (Choose two.)
- ❌ Turn on auto scaling for the DB instance.
- ✅ Create a read replica for the DB instance. Configure the application to send read traffic to the read replica.
- Convert the DB instance to a Multi-AZ DB instance deployment. Configure the application to send read traffic to the standby DB instance.
- ✅ Create an Amazon ElastiCache cluster. Configure the application to cache query results in the ElastiCache cluster.
- Configure the Auto Scaling group subnets to ensure that the EC2 instances are provisioned in the same Availability Zone as the DB instance.
✨ 关键词:
1️⃣ 2️⃣ ❌ -> 2️⃣ 4️⃣ ✅
💡 解析:
RDS的弹性扩展确实是不存在的,只有Aurora数据库的读取副本支持弹性扩展。
Amazon Aurora Auto Scaling 与 Aurora 副本结合使用为了满足您的连接和工作负载要求,Aurora Auto Scaling 动态调整为 Aurora 数据库集群预调配的 Aurora 副本数(读取器数据库实例)。Aurora Auto Scaling 适用于 Aurora MySQL 和 Aurora PostgreSQL。通过使用 Aurora Auto Scaling,Aurora 数据库集群可以处理连接或工作负载突然增加的情况。在连接或工作负载减少时,Aurora Auto Scaling 删除不需要的 Aurora 副本,以便您无需为未使用的配置数据库实例付费。
Aurora Auto Scaling 不适用于写入器数据库实例上的工作负载。Aurora Auto Scaling 只能协助处理读取器实例上的工作负载。
👨👨👦👦 社区讨论:A: RDS DB instance Autoscaling is not a thing
C: You cannot read from standby even if this was done.
E: Does not solve any problemCorrect answer B: Read replicas distribute load and help improving performance D: Caching of any kind will help with performance Remember: ” The database experiences a heavy read load during periods of high traffic.”
十九、Amazon EBS snapshot lock
A company uses Amazon EC2 instances and Amazon Elastic Block Store (Amazon EBS) volumes to run an application. The company creates one snapshot of each EBS volume every day to meet compliance requirements. The company wants to implement an architecture that prevents the accidental deletion of EBS volume snapshots. The solution must not change the administrative rights of the storage administrator user.
Which solution will meet these requirements with the LEAST administrative effort?
- Create an IAM role that has permission to delete snapshots. Attach the role to a new EC2 instance. Use the AWS CLI from the new EC2 instance to delete snapshots.
- Create an IAM policy that denies snapshot deletion. Attach the policy to the storage administrator user.
- ❌ Add tags to the snapshots. Create retention rules in Recycle Bin for EBS snapshots that have the tags.
- ✅ Lock the EBS snapshots to prevent deletion.
✨ 关键词:
3️⃣ ❌ -> 4️⃣ ✅
💡 解析:亚马逊EBS快照锁
您可以锁定您的 Amazon EBS 快照以防止意外或恶意删除,或者以 WORM (write-once-read-many) 格式将其存储在特定时间内。当快照处于锁定状态时,任何用户都无法将其删除,无论其IAM权限如何。您可以像使用任何其他快照一样继续使用锁定的快照。
👨👨👦👦 社区讨论:Locking EBS Snapshots (Option D): The “lock” feature in AWS allows you to prevent accidental deletion of resources, including EBS snapshots. This can be set at the snapshot level, providing a straightforward and effective way to meet the requirements without changing the administrative rights of the storage administrator user.
二十、EKS and spot instances
A company is developing an application that will run on a production Amazon Elastic Kubernetes Service (Amazon EKS) cluster. The EKS cluster has managed node groups that are provisioned with On-Demand Instances.
The company needs a dedicated EKS cluster for development work. The company will use the development cluster infrequently to test the resiliency of the application. The EKS cluster must manage all the nodes.
Which solution will meet these requirements MOST cost-effectively?
- Create a managed node group that contains only Spot Instances.
- ✅ Create two managed node groups. Provision one node group with On-Demand Instances. Provision the second node group with Spot Instances.
- Create an Auto Scaling group that has a launch configuration that uses Spot Instances. Configure the user data to add the nodes to the EKS cluster.
- ❌ Create a managed node group that contains only On-Demand Instances.
✨ 关键词:
4️⃣ ❌ -> 2️⃣ ✅
💡 解析:社区在 1️⃣ 和 2️⃣ 之间争议较大,但是争议点为题目描述方式,是需要一个“专用以开发环境的集群”还是“一个集群既包含生产节点又包含开发节点”。
无论如何将抢占 (Spot) 实例用以开发节点是共识。
竞价型实例的工作原理如果有可用容量,则您的竞价型实例将启动。您的 Spot 实例会一直运行,直到您停止或终止它,或者 Amazon EC2 中断它(称为 Spot 实例中断)。Amazon EC2 可以在中断竞价型实例时使实例停止、终止或休眠。
👨👨👦👦 社区讨论:This question is convoluted and missing some details.
We need:
- control plane running on on-demand EC2s
- worker nodes running on spot instances Read this to understand correct solution:
https://aws.amazon.com/blogs/containers/amazon-eks-now-supports-provisioning-and-managing-ec2-spot-instances-in-managed-node-groups/
二十一、EBS auto encryption
A company needs a solution to enforce data encryption at rest on Amazon EC2 instances. The solution must automatically identify noncompliant resources and enforce compliance policies on findings.
Which solution will meet these requirements with the LEAST administrative overhead?
- ✅ Use an IAM policy that allows users to create only encrypted Amazon Elastic Block Store (Amazon EBS) volumes. Use AWS Config and AWS Systems Manager to automate the detection and remediation of unencrypted EBS volumes.
- Use AWS Key Management Service (AWS KMS) to manage access to encrypted Amazon Elastic Block Store (Amazon EBS) volumes. Use AWS Lambda and Amazon EventBridge to automate the detection and remediation of unencrypted EBS volumes.
- Use Amazon Macie to detect unencrypted Amazon Elastic Block Store (Amazon EBS) volumes. Use AWS Systems Manager Automation rules to automatically encrypt existing and new EBS volumes.
- ❌ Use Amazon inspector to detect unencrypted Amazon Elastic Block Store (Amazon EBS) volumes. Use AWS Systems Manager Automation rules to automatically encrypt existing and new EBS volumes.
✨ 关键词:
4️⃣ ❌ -> 1️⃣ ✅
- AWS Config 检测到未加密的EBS卷。
- 管理员使用 AWS Config 向 Systems Manager 发送修复命令。
- Systems Manager 会自动拍摄未加密EBS卷的快照。
- Systems Manager 自动化用于AWSKMS创建快照的加密副本。
- Systems Manager 自动化执行以下操作:
- 如果受影响的EC2实例正在运行,则将其停止
- 将卷的新加密副本附加到实EC2例
- 将EC2实例恢复到其原始状态
示例:创建卷 - 以下策略允许用户使用该CreateVolumeAPI操作。系统只允许用户创建加密且大小不足 20 GiB 的卷
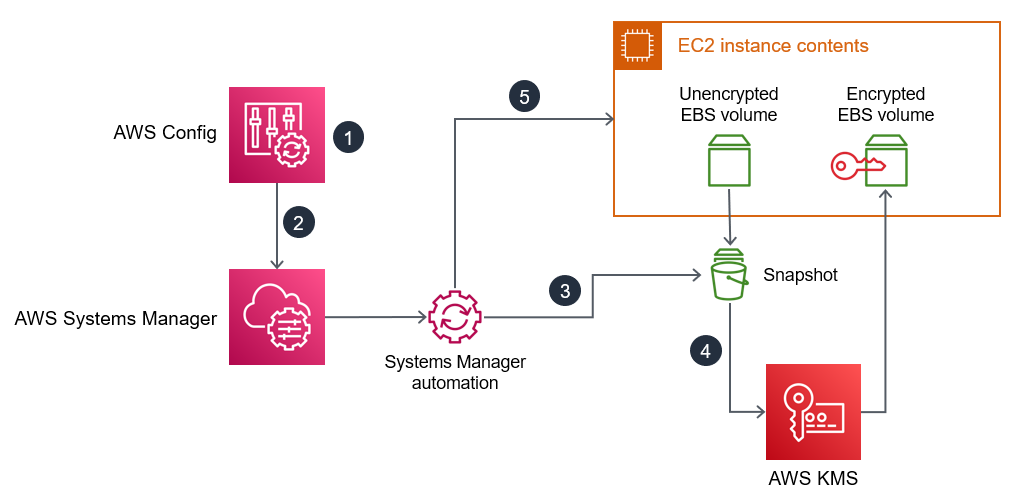
👨👨👦👦 社区讨论:A as exactly described here: https://docs.aws.amazon.com/prescriptive-guidance/latest/patterns/automatically-encrypt-existing-and-new-amazon-ebs-volumes.html
Not B, that could in theory work but would be massive operational overhead Not C, Macie detects PII data, not unencrypted volumes Not D, Inspector detects vulnerabilities, not unencrypted volumes
二十二、Amazon Forecast
A company that uses AWS needs a solution to predict the resources needed for manufacturing processes each month. The solution must use historical values that are currently stored in an Amazon S3 bucket. The company has no machine learning (ML) experience and wants to use a managed service for the training and predictions.
Which combination of steps will meet these requirements? (Choose two.)
- Deploy an Amazon SageMaker model. Create a SageMaker endpoint for inference.
- ❌ Use Amazon SageMaker to train a model by using the historical data in the S3 bucket.
- ❌ Configure an AWS Lambda function with a function URL that uses Amazon SageMaker endpoints to create predictions based on the inputs.
- ✅ Configure an AWS Lambda function with a function URL that uses an Amazon Forecast predictor to create a prediction based on the inputs.
- ✅ Train an Amazon Forsecast predictor by using the historical data in the S3 bucket.
✨ 关键词:
2️⃣ 3️⃣ ❌ -> 4️⃣ 5️⃣ ✅
💡 解析:什么是 Amazon Forecast?
Amazon Forecast 是一种完全托管式服务,可使用统计和机器学习算法提供高度精确的时间序列预测。Forecast 基于与 Amazon.com 用于时间序列预测的相同技术,提供基于历史数据预测未来时间序列数据的 state-of-the-art 算法,无需任何机器学习经验。
时间序列预测适用于多个领域,包括零售、金融、物流和医疗保健。您还可以使用 Forecast 来预测库存、人力、Web 流量、服务器容量和财务状况等特定领域的指标。Amazon Forecast 不再向新买家开放。Amazon Forecast 的现有客户可以继续照常使用该服务。
Amazon SageMaker 是一项完全托管的服务,可为每位开发人员和数据科学家提供快速构建、训练和部署机器学习 (ML) 模型的能力。SageMaker 消除了机器学习过程中每个步骤的繁重工作,让您能够更轻松地开发高质量模型。
两个也都能读取
S3内的数据,因此在这里理论上都能选。
👨👨👦👦 社区讨论:Amazon Forecast is no longer available to new customers.
https://aws.amazon.com/blogs/machine-learning/transition-your-amazon-forecast-usage-to-amazon-sagemaker-canvas/
二十三、IAM Identity Center
A company manages AWS accounts in AWS Organizations. AWS IAM Identity Center (AWS Single Sign-On) and AWS Control Tower are configured for the accounts. The company wants to manage multiple user permissions across all the accounts.
The permissions will be used by multiple IAM users and must be split between the developer and administrator teams. Each team requires different permissions. The company wants a solution that includes new users that are hired on both teams.
Which solution will meet these requirements with the LEAST operational overhead?
- Create individual users in IAM Identity Center for each account. Create separate developer and administrator groups in IAM Identity Center. Assign the users to the appropriate groups. Create a custom IAM policy for each group to set fine-grained permissions.
- ❌ Create individual users in IAM Identity Center for each account. Create separate developer and administrator groups in IAM Identity Center. Assign the users to the appropriate groups. Attach AWS managed IAM policies to each user as needed for fine-grained permissions.
- ✅ Create individual users in IAM Identity Center. Create new developer and administrator groups in IAM Identity Center. Create new permission sets that include the appropriate IAM policies for each group. Assign the new groups to the appropriate accounts. Assign the new permission sets to the new groups. When new users are hired, add them to the appropriate group.
为每个组创建包含适当IAM策略的新权限集。将新组分配给适当的帐户。将新的权限集分配给新的组。雇用新用户时,将其添加到适当的组中。
- Create individual users in IAM Identity Center. Create new permission sets that include the appropriate IAM policies for each user. Assign the users to the appropriate accounts. Grant additional IAM permissions to the users from within specific accounts. When new users are hired, add them to IAM Identity Center and assign them to the accounts.
✨ 关键词:
2️⃣ ❌ -> 3️⃣ ✅
💡 解析:与 AWS IAM 身份中心和 AWS Control Tower 合作
在 AWS Control Tower 中,IAM 身份中心允许中央云管理员和最终用户管理对多个 AWS 账户和业务应用程序的访问权限。默认情况下,AWS Control Tower 使用此服务来设置和管理对通过 Account Factory 创建的账户的访问权限,除非您选择了自行管理身份和访问控制的选项。
👨👨👦👦 社区讨论:C is least overhead
二十四、S3
A company regularly uploads GB-sized files to Amazon S3. After the company uploads the files, the company uses a fleet of Amazon EC2 Spot Instances to transcode the file format. The company needs to scale throughput when the company uploads data from the on-premises data center to Amazon S3 and when the company downloads data from Amazon S3 to the EC2 instances.
Which solutions will meet these requirements? (Choose two.)
- ❌ Use the S3 bucket access point instead of accessing the S3 bucket directly.
- Upload the files into multiple S3 buckets.
- ✅ Use S3 multipart uploads.
- ✅ Fetch multiple byte-ranges of an object in parallel.
- Add a random prefix to each object when uploading the files.
✨ 关键词:
1️⃣ 3️⃣ ❌ -> 3️⃣ 4️⃣ ✅
💡 解析:使用字节范围提取
通过在 GET 对象请求中使用范围 HTTP 标头,您可以从对象中提取字节范围,只传输指定的部分。您可以使用到 Amazon S3 的并行连接,从相同对象中提取不同的字节范围。这有助于您通过单一整个对象请求实现更高的聚合吞吐量。通过提取较小范围的大型对象,您的应用程序还可以在请求中断时改善重试次数。
👨👨👦👦 社区讨论:C: Increase the file upload throughput D: increase the file download throughput