来源:Amazon AWS Certified Solutions Architect - Associate SAA-C03 Exam
100 题 (No.501 ~ No.600) 只记录了 21 道首次碰到的、错误的或有疑问的题目,仅供自己复习使用。
其中后 65 题与正式考试题量一样,总共耗时 85/(130+30) 分钟,正确率为 48/65。
如果侵权请联系删除。
一、Transit
A company needs to connect several VPCs in the us-east-1 Region that span hundreds of AWS accounts. The company’s networking team has its own AWS account to manage the cloud network.
What is the MOST operationally efficient solution to connect the VPCs?
- Set up VPC peering connections between each VPC. Update each associated subnet’s route table
- Configure a NAT gateway and an internet gateway in each VPC to connect each VPC through the internet
- ✅ Create an AWS Transit Gateway in the networking team’s AWS account. Configure static routes from each VPC.
- ❌ Deploy VPN gateways in each VPC. Create a transit VPC in the networking team’s AWS account to connect to each VPC.
✨ 关键词:
4️⃣ ❌ -> 3️⃣ ✅
💡 解析:需要将几个
VPC组网。
无疑是需要用到Transit的,来看下用法:什么是 Amazon VPC Transit Gateway?Amazon VPC Transit Gateway 是网络中转中心,您可用它来互连虚拟私有云(VPC)和本地网络。随着云基础架构的全球扩展,区域间对等使用全球基础架构将 AWS 中转网关连接在一起。AWS 数据中心之间的所有网络流量都在物理层自动加密。
需要使用到
AWS Transit Gateway因此选 3️⃣。
👨👨👦👦 社区讨论:The main difference between AWS Transit Gateway and VPC peering is that AWS Transit Gateway is designed to connect multiple VPCs together in a hub-and-spoke model, while VPC peering is designed to connect two VPCs together in a peer-to- peer model.
As we have several VPCs here, the answer should be C.
二、Security group ID cross Region
A global marketing company has applications that run in the ap-southeast-2 Region and the eu-west-1 Region. Applications that run in a VPC in eu-west-1 need to communicate securely with databases that run in a VPC in ap-southeast-2.
Which network design will meet these requirements?
- Create a VPC peering connection between the eu-west-1 VPC and the ap-southeast-2 VPC. Create an inbound rule in the eu-west-1 application security group that allows traffic from the database server IP addresses in the ap-southeast-2 security group.
- ❌ Configure a VPC peering connection between the ap-southeast-2 VPC and the eu-west-1 VPC. Update the subnet route tables. Create an inbound rule in the ap-southeast-2 database security group that references the security group ID of the application servers in eu-west-1.
- ✅ Configure a VPC peering connection between the ap-southeast-2 VPC and the eu-west-1 VPUpdate the subnet route tables. Create an inbound rule in the ap-southeast-2 database security group that allows traffic from the eu-west-1 application server IP addresses.
- Create a transit gateway with a peering attachment between the eu-west-1 VPC and the ap-southeast-2 VPC. After the transit gateways are properly peered and routing is configured, create an inbound rule in the database security group that references the security group ID of the application servers in eu-west-1.
✨ 关键词:
2️⃣ ❌ -> 3️⃣ ✅
💡 解析:无法跨区域引用安全组。
更新您的安全组以引用对等安全组
- 对等 VPC 可以是您的账户中的 VPC,也可以是另一AWS账户中的 VPC。要引用位于其他 AWS 账户但属于相同区域的安全组,请将账号与安全组的 ID 一起包括在内。例如,123456789012/sg-1a2b3c4d。
- 您无法引用位于不同区域内的对等 VPC 的安全组。而是使用对等 VPC 的 CIDR 块。
可以跨账号引用相同区域的安全组。
👨👨👦👦 社区讨论:Answer: C —>“You cannot reference the security group of a peer VPC that’s in a different Region. Instead, use the CIDR block of the peer VPC.”
https://docs.aws.amazon.com/vpc/latest/peering/vpc-peering-security-groups.html
三、EKS node
A company is running a microservices application on Amazon EC2 instances. The company wants to migrate the application to an Amazon Elastic Kubernetes Service (Amazon EKS) cluster for scalability. The company must configure the Amazon EKS control plane with endpoint private access set to true and endpoint public access set to false to maintain security compliance. The company must also put the data plane in private subnets. However, the company has received error notifications because the node cannot join the cluster.
Which solution will allow the node to join the cluster?
- ✅ Grant the required permission in AWS Identity and Access Management (IAM) to the AmazonEKSNodeRole IAM role.
- ❌ Create interface VPC endpoints to allow nodes to access the control plane.
- Recreate nodes in the public subnet. Restrict security groups for EC2 nodes.
- Allow outbound traffic in the security group of the nodes.
✨ 关键词:
2️⃣ ❌ -> 1️⃣ ✅
💡 解析:Amazon EKS 节点 IAM 角色
Amazon EKS 节点 kubelet 守护进程代表您调用 AWS API。节点通过 IAM 实例配置文件和关联的策略获得这些 API 调用的权限。您必须先为节点创建 IAM 角色以在启动它们时使用,然后才能启动这些节点并在集群中注册它们。
必须先使用以下权限创建 IAM 角色,然后才能创建节点:
kubelet描述 VPC 中 Amazon EC2 资源的权限,例如 AmazonEKSWorkerNodePolicy 策略提供的权限。该策略还为 Amazon EKS 容器组身份代理提供权限。
👨👨👦👦 社区讨论:Check this : https://docs.aws.amazon.com/eks/latest/userguide/create-node-role.html
Also, EKS does not require VPC endpoints. This is not the right use case for EKS
四、Amazon Redshift
A company is migrating an on-premises application to AWS. The company wants to use Amazon Redshift as a solution.
Which use cases are suitable for Amazon Redshift in this scenario? (Choose three.)
- ✅ Supporting data APIs to access data with traditional, containerized, and event-driven applications
- ✅ Supporting client-side and server-side encryption
- ❌ Building analytics workloads during specified hours and when the application is not active
- Caching data to reduce the pressure on the backend database
- ✅ Scaling globally to support petabytes of data and tens of millions of requests per minute
- Creating a secondary replica of the cluster by using the AWS Management Console
✨ 关键词:
1️⃣ 3️⃣ 5️⃣ ❌ -> 1️⃣ 2️⃣ 5️⃣ ✅
💡 解析:1️⃣ 正确:Using the Amazon Redshift Data API to interact with Amazon Redshift clusters
2️⃣ 正确:数据加密
- 使用服务器端加密 – 您请求 Amazon Redshift 在将数据保存到数据中心的磁盘上之前加密对象,并在下载对象时进行解密。
- 使用客户端加密 – 您可以在客户端加密数据并将加密的数据上载到 Amazon Redshift。在这种情况下,您需要管理加密过程、加密密钥和相关的工具。
社区争议很大。

👨👨👦👦 社区讨论:A: https://aws.amazon.com/de/blogs/big-data/get-started-with-the-amazon-redshift-data-api/
B: https://docs.aws.amazon.com/redshift/latest/mgmt/security-encryption.html D: https://docs.aws.amazon.com/redshift/latest/dg/c_challenges_achieving_high_performance_queries.html#result-cachingNot C: Redshift is a Data Warehouse; you can use that for analytics, but it is not directly related to an “application” . Not E: “Petabytes of data” yes, but “tens of millions of requests per minute” is not a typical feature of Redshift Not F: Replicas are not a Redshift feature
五、Lambda concurrency
A company provides an API interface to customers so the customers can retrieve their financial information. Еhe company expects a larger number of requests during peak usage times of the year.
The company requires the API to respond consistently with low latency to ensure customer satisfaction. The company needs to provide a compute host for the API.
Which solution will meet these requirements with the LEAST operational overhead?
- Use an Application Load Balancer and Amazon Elastic Container Service (Amazon ECS).
- ✅ Use Amazon API Gateway and AWS Lambda functions with provisioned concurrency.
- Use an Application Load Balancer and an Amazon Elastic Kubernetes Service (Amazon EKS) cluster.
- Use Amazon API Gateway and AWS Lambda functions with reserved concurrency.
✨ 关键词:
2️⃣ ✅
💡 解析:为函数配置预留并发
预留并发 (Reserved concurrency)– 指分配给函数的最大并发实例数。当一个函数有预留并发时,任何其他函数都不可以使用该并发。对于确保最关键的函数始终具有足够的并发性来处理传入请求,预留并发非常有用。为函数配置预留并发不产生任何额外费用。预置并发 (Provisioned concurrency)– 指分配给函数的预初始化执行环境的数量。这些执行环境已准备就绪,可以立即响应传入的函数请求。预置并发对于缩短函数冷启动延迟很有用。配置预置并发会让您的 AWS 账户产生额外费用。预置 (Provisioned) 后相应延迟更低。
👨👨👦👦 社区讨论:In the context of the given scenario, where the company wants low latency and consistent performance for their API during peak usage times, it would be more suitable to use provisioned concurrency. By allocating a specific number of concurrent executions, the company can ensure that there are enough function instances available to handle the expected load and minimize the impact of cold starts. This will result in lower latency and improved performance for the API.
六、AWS Service Catalog
A consulting company provides professional services to customers worldwide. The company provides solutions and tools for customers to expedite gathering and analyzing data on AWS. The company needs to centrally manage and deploy a common set of solutions and tools for customers to use for self-service purposes.
Which solution will meet these requirements?
- ❌ Create AWS CloudFormation templates for the customers.
- ✅ Create AWS Service Catalog products for the customers.
- Create AWS Systems Manager templates for the customers.
- Create AWS Config items for the customers.
✨ 关键词:
1️⃣ ❌ -> 2️⃣ ✅
💡 解析:什么是 Service Catalog?
借助 Service Catalog,组织可以创建和管理获准在 AWS 上使用的 IT 服务的目录。这些 IT 服务可谓包罗万象,从虚拟机映像、服务器、软件和数据库,再到完整的多层应用程序架构等。
和它很像的服务:什么是 Amazon Cognito?
Amazon Cognito 是 Web 和移动应用程序的身份平台。它是一个用户目录、一个身份验证服务器以及一个用于 OAuth 2.0 访问令牌和 AWS 凭据的授权服务。使用 Amazon Cognito,您可以对内置用户目录、企业目录以及 Google 和 Facebook 等使用者身份提供者中的用户进行身份验证和授权。
👨👨👦👦 社区讨论:CloudFormation: a code as infrastructure service
Systems Manager: management solution for resources
Config: assess, audit and evaluate configurations
Other options does not fit this scenario.
七、RDS cluster deployment
A company wants to provide data scientists with near real-time read-only access to the company’s production Amazon RDS for PostgreSQL database. The database is currently configured as a Single-AZ database. The data scientists use complex queries that will not affect the production database. The company needs a solution that is highly available.
Which solution will meet these requirements MOST cost-effectively?
- Scale the existing production database in a maintenance window to provide enough power for the data scientists.
- Change the setup from a Single-AZ to a Multi-AZ instance deployment with a larger secondary standby instance. Provide the data scientists access to the secondary instance.
- ❌ Change the setup from a Single-AZ to a Multi-AZ instance deployment. Provide two additional read replicas for the data scientists.
- ✅ Change the setup from a Single-AZ to a Multi-AZ cluster deployment with two readable standby instances. Provide read endpoints to the data scientists.
✨ 关键词:
3️⃣ ❌ -> 4️⃣ ✅
多可用区数据库集群部署是 Amazon RDS 的半同步、高可用性部署模式,具有两个可读副本数据库实例。多可用区数据库集群在同一个 AWS 区域 的三个独立可用区中有一个写入器数据库实例和两个读取器数据库实例。与多可用区数据库实例部署相比,多可用区数据库集群可提供高可用性、增加读取工作负载容量以及更低的写入延迟。
以
Aurora为例:Amazon Aurora 数据库集群Amazon Aurora 数据库集群包含一个或多个数据库实例以及一个管理这些数据库实例的数据的集群卷。Aurora 集群卷是一个跨多个可用区的虚拟数据库存储卷,每个可用区具有一个数据库集群数据副本。Aurora 数据库集群由两类数据库实例组成:
- 主(写入器)数据库实例 – 支持读取和写入操作,并执行针对集群卷的所有数据修改。每个 Aurora 数据库集群均有一个主数据库实例。
- Aurora 副本(读取器数据库实例)– 连接到同一存储卷作为主数据库实例,但仅支持读取操作。除主数据库实例之外,每个 Aurora 数据库集群最多可拥有 15 个 Aurora 副本。通过将 Aurora 副本放在单独的可用区中维护高可用性。当主数据库实例不可用时,Aurora 自动故障转移到 Aurora 副本。您可以为 Aurora 副本指定故障转移优先级。Aurora 副本还可以从主数据库实例分载读取工作负载。
集群天生带只读副本,更便宜。
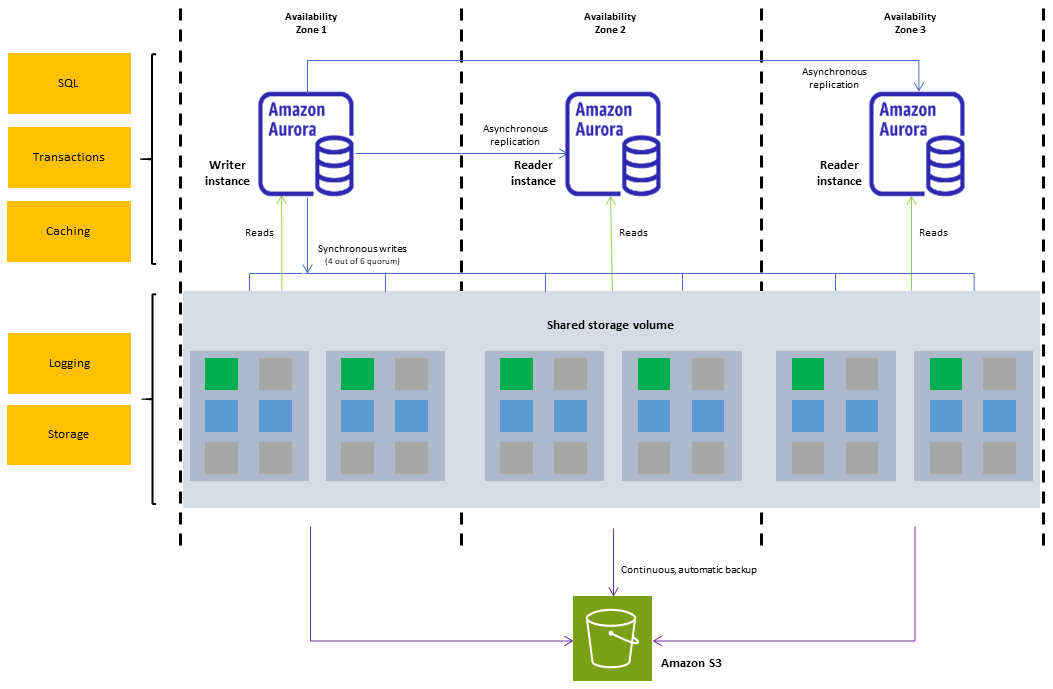
👨👨👦👦 社区讨论:Highly Available = Multi-AZ Cluster
Read-only + Near Real time = readable standby.
Read replicasare async whereas readable standby is synchronous.
https://stackoverflow.com/questions/70663036/differences-b-w-aws-read-replica-and-the-standby-instancesIt’seither C or D.To be honest, I find the newest questions to be ridiculously hard (roughly 500+). I agree with @alexandercamachop that Multi Az in Instance mode is cheaper than Cluster. However, with Cluster we have readerendpoint available to use out-of-box, so there is no need to provide read-replicas, which also has its own costs.The ridiculous part is that I’m pretty sure even the AWS support would have troubles to answer which configuration is MOST cost-effective.
八、Session storage
A company runs a three-tier web application in the AWS Cloud that operates across three Availability Zones. The application architecture has an Application Load Balancer, an Amazon EC2 web server that hosts user session states, and a MySQL database that runs on an EC2 instance. The company expects sudden increases in application traffic. The company wants to be able to scale to meet future application capacity demands and to ensure high availability across all three Availability Zones.
Which solution will meet these requirements?
- ✅ Migrate the MySQL database to Amazon RDS for MySQL with a Multi-AZ DB cluster deployment. Use Amazon ElastiCache for Redis with high availability to store session data and to cache reads. Migrate the web server to an Auto Scaling group that is in three Availability Zones.
- ❌ Migrate the MySQL database to Amazon RDS for MySQL with a Multi-AZ DB cluster deployment. Use Amazon ElastiCache for Memcached with high availability to store session data and to cache reads. Migrate the web server to an Auto Scaling group that is in three Availability Zones.
- Migrate the MySQL database to Amazon DynamoDB Use DynamoDB Accelerator (DAX) to cache reads. Store the session data in DynamoDB. Migrate the web server to an Auto Scaling group that is in three Availability Zones.
- Migrate the MySQL database to Amazon RDS for MySQL in a single Availability Zone. Use Amazon ElastiCache for Redis with high availability to store session data and to cache reads. Migrate the web server to an Auto Scaling group that is in three Availability Zones.
✨ 关键词:session
2️⃣ ❌ -> 1️⃣ ✅
💡 解析:与 Redis OSS 兼容的 Amazon ElastiCache
Redis OSS 是一种得到广泛采用的内存数据存储,可用作数据库、缓存、消息代理、队列、会话存储和排行榜。
适用于 Memcached 的 Amazon ElastiCache 可以用作内存数据存储和缓存,能够支持要求最严苛且需要亚毫秒级响应时间的应用程序。
非超低延迟需求的场景都选
Redis即可。
👨👨👦👦 社区讨论:Memcached is best suited for caching data, while Redis is better for storing data that needs to be persisted. If you need to store data that needs to be accessed frequently, such as user profiles, session data,and application settings, then Redis is the better choice.
九、Multi-AZ DB cluster
A company has an on-premises server that uses an Oracle database to process and store customer information. The company wants to use an AWS database service to achieve higher availability and to improve application performance. The company also wants to offload reporting from its primary database system.
Which solution will meet these requirements in the MOST operationally efficient way?
- ❌ Use AWS Database Migration Service (AWS DMS) to create an Amazon RDS DB instance in multiple AWS Regions. Point the reporting functions toward a separate DB instance from the primary DB instance.
- Use Amazon RDS in a Single-AZ deployment to create an Oracle database. Create a read replica in the same zone as the primary DB instance. Direct the reporting functions to the read replica.
- Use Amazon RDS deployed in a Multi-AZ cluster deployment to create an Oracle database. Direct the reporting functions to use the reader instance in the cluster deployment.
- ✅ Use Amazon RDS deployed in a Multi-AZ instance deployment to create an Amazon Aurora database. Direct the reporting functions to the reader instances.
✨ 关键词:
1️⃣ ❌ -> 4️⃣ ✅
💡 解析:支持 Amazon RDS 中多可用区数据库集群的区域和数据库引擎
多可用区数据库集群不适用于以下引擎:
- RDS for Db2
- RDS for MariaDB
- RDS for Oracle
- RDS for SQL Server
因此本题只能迁移到
Aurora集群。
👨👨👦👦 社区讨论:Its D
Multi-AZ DB clustersaren’t available with the following engines:
- RDS for MariaDB
- RDS for Oracle
- RDS forSQL Server
十、AWS Organization
A company runs Amazon EC2 instances in multiple AWS accounts that are individually bled. The company recently purchased a Savings Pian. Because of changes in the company’s business requirements, the company has decommissioned a large number of EC2 instances. The company wants to use its Savings Plan discounts on its other AWS accounts.
Which combination of steps will meet these requirements? (Choose two.)
- ✅ From the AWS Account Management Console of the management account, turn on discount sharing from the billing preferences section.
- From the AWS Account Management Console of the account that purchased the existing Savings Plan, turn on discount sharing from the billing preferences section. Include all accounts.
- ❌ From the AWS Organizations management account, use AWS Resource Access Manager (AWS RAM) to share the Savings Plan with other accounts.
- ✅ Create an organization in AWS Organizations in a new payer account. Invite the other AWS accounts to join the organization from the management account.
- Create an organization in AWS Organizations in the existing AWS account with the existing EC2 instances and Savings Plan. Invite the other AWS accounts to join the organization from the management account.
✨ 关键词:
1️⃣ 3️⃣ ❌ -> 1️⃣ 4️⃣ ✅
💡 解析:社区在 4️⃣ 5️⃣ 间争执较大,不用纠结。如果想强行记忆的话可以认定管理账户不适合做资源操作,因此 5️⃣ 不合适。
明确 1️⃣ 相关知识点吧:预留实例和实惠配套折扣共享激活共享的预留实例和实惠配套折扣
- 登录 AWS Management Console 并打开 AWS Billing and Cost Management 控制台
- 在导航窗格中,选择账单首选项。
- 在按账户的预留实例和实惠配套折扣共享首选项下,选择要激活折扣共享的账户。
- 选择激活。
- 在激活预留实例和实惠配套共享对话框中,选择激活。
您也可以选择操作,然后选择全部激活,以为所有账户激活预留实例和实惠配套共享。
在(Organizations 管理账户的)管理控制台的账单和费用控制台,为所有 AWS 账户启动预留实例和节省套餐。
👨👨👦👦 社区讨论:Organization should be created by a new account that is reserved for management.
Thus D, followed by A (discount sharing must be enabled in the management account).
十一、S3 Storage
A company has a financial application that produces reports. The reports average 50 KB in size and are stored in Amazon S3.
The reports are frequently accessed during the first week after production and must be stored for several years. The reports must be retrievable within 6 hours.
Which solution meets these requirements MOST cost-effectively?
- ✅ Use S3 Standard. Use an S3 Lifecycle rule to transition the reports to S3 Glacier after 7 days.
- Use S3 Standard. Use an S3 Lifecycle rule to transition the reports to S3 Standard-Infrequent Access (S3 Standard-IA) after 7 days.
- Use S3 Intelligent-Tiering. Configure S3 Intelligent-Tiering to transition the reports to S3 Standard-Infrequent Access (S3 Standard-IA) and S3 Glacier.
- ❌ Use S3 Standard. Use an S3 Lifecycle rule to transition the reports to S3 Glacier Deep Archive after 7 days.
✨ 关键词:
3️⃣ ❌ -> 1️⃣ ✅
💡 解析:归档存储检索时间问题,参考社区回答,普通归档在 3 ~ 5 小时,深度在 12 小时。
👨👨👦👦 社区讨论:Answer is A
Amazon S3 Glacier:
Expedited Retrieval: Providesaccess to data within 1-5 minutes.
Standard Retrieval: Providesaccess to data within 3-5 hours.
Bulk Retrieval: Providesaccess to data within 5-12 hours.Amazon S3 Glacier Deep Archive:
Standard Retrieval: Providesaccess to data within 12 hours.
Bulk Retrieval: Providesaccess to data within 48 hours.
十二、SQS security group
A company runs an application in a VPC with publicand private subnets. The VPC extends across multiple Availability Zones. The application runs on Amazon EC2 instances in private subnets. The application uses an Amazon Simple Queue Service (Amazon SQS) queue.
A solutions architect needs to design a secure solution to establish a connection between the EC2 instances and the SQS queue.
Which solution will meet these requirements?
- ✅ Implement an interface VPC endpoint for Amazon SQS. Configure the endpoint to use the private subnets. Add to the endpoint a security group that has an inbound access rule that allows traffic from the EC2 instances that are in the private subnets.
- Implement an interface VPC endpoint for Amazon SQS. Configure the endpoint to use the public subnets. Attach to the interface endpoint a VPC endpoint policy that allows access from the EC2 instances that are in the private subnets.
- ❌ Implement an interface VPC endpoint for Amazon SQS. Configure the endpoint to use the public subnets. Attach an Amazon SQS access policy to the interface VPC endpoint that allows requests from only a specified VPC endpoint.
- Implement a gateway endpoint for Amazon SQS. Add a NAT gateway to the private subnets. Attach an IAM role to the EC2 instances that allows access to the SQS queue.
✨ 关键词:
3️⃣ ❌ -> 1️⃣ ✅
💡 解析:
VPC 接口终端节点可以配置安全组:AWS 服务 使用接口VPC终端节点访问一个为终端节点网络接口创建一个安全组,允许来自您的资源的预期流量VPC。例如,为了确保 AWS CLI 可以向发送HTTPS请求 AWS 服务,安全组必须允许入站HTTPS流量。
👨👨👦👦 社区讨论:BC are using public subnets so not useful for security
D uses gatewayendpoint which is not useful to connect to SQS
A: https://docs.aws.amazon.com/vpc/latest/privatelink/aws-services-privatelink-support.html
十三、Amazon EMR
A solutions architect manages an analytics application. The application stores large amounts of semistructured data in an Amazon S3 bucket. The solutions architect wants to use parallel data processing to process the data more quickly. The solutions architect also wants to use information that is stored in an Amazon Redshift database to enrich the data.
Which solution will meet these requirements?
- Use Amazon Athena to process the S3 data. Use AWS Glue with the Amazon Redshift data to enrich the S3 data.
- ✅ Use Amazon EMR to process the S3 data. Use Amazon EMR with the Amazon Redshift data to enrich the S3 data.
- Use Amazon EMR to process the S3 data. Use Amazon Kinesis Data Streams to move the S3 data into Amazon Redshift so that the data can be enriched.
- ❌ Use AWS Glue to process the S3 data. Use AWS Lake Formation with the Amazon Redshift data to enrich the S3 data.
✨ 关键词:
4️⃣ ❌ -> 2️⃣ ✅
💡 解析:什么是 Amazon EMR?
Amazon EMR(以前称为 Amazon Elastic MapReduce)是一个托管集群平台,可简化在AWS上运行大数据框架的过程,以处理和分析海量数据。
Hadoop 可用于处理 Web 和移动应用程序生成的日志。Hadoop 可帮助您将数 PB 的非结构化或半结构化数据转变为与应用程序或用户有关的有用洞察信息。
您可以使用 COPY 命令从一个具有如下配置的 Amazon EMR 集群并行加载数据(到 RedShift 中):将文本文件作为固定宽度文件、字符分隔文件、CSV 文件或 JSON 格式文件写入到集群的 Hadoop Distributed File System (HDFS)。
👨👨👦👦 社区讨论:Option B is the correct solution that meets the requirements:
- Use Amazon EMR to process the semi-structured data in Amazon S3.EMR providesa managed Hadoop framework optimized for processing large datasets in S3.
- EMR supports parallel data processing across multiple nodes to speed up the processing.
- EMR can integrate directly with Amazon Redshift using the EMR-Redshift integration.Thisallows querying the Redshift data from EMR and joining it with the S3 data. This enablesenriching the semi-structured S3 data with the information stored in Redshift
十四、EKS
A company runs its applications on both Amazon Elastic Kubernetes Service (Amazon EKS) clusters and on-premises Kubernetes clusters. The company wants to view all clusters and workloads from a central location.
Which solution will meet these requirements with the LEAST operational overhead?
- Use Amazon CloudWatch Container Insights to collect and group the cluster information.
- ✅ Use Amazon EKS Connector to register and connect all Kubernetes clusters.
- Use AWS Systems Manager to collect and view the cluster information.
- ❌ Use Amazon EKS Anywhere as the primary cluster to view the other clusters with native Kubernetes commands.
✨ 关键词:
4️⃣ ❌ -> 2️⃣ ✅
💡 解析:使用 Amazon EKS Connector 将 Kubernetes 集群连接到 Amazon EKS 管理控制台
您可以使用 Amazon EKS Connector 注册并将任何符合要求的 Kubernetes 集群连接至 AWS,并在 Amazon EKS 控制台中进行显示。连接集群后,您可以在 Amazon EKS 控制台中查看集群的状态、配置和工作负载。
您可以使用此功能在 Amazon EKS 控制台中查看已连接的集群,但您无法对其进行管理。Amazon EKS Anywhere 是由 AWS 构建的容器管理软件,便于在本地和边缘运行和管理 Kubernetes 集群。
👨👨👦👦 社区讨论:EKS Connector -> ‘view clustersand workloads’as requested
EKS Anywhere -> create and manage on-premisesEKS clusters
十五、Amazon EventBridge
An Amazon EventBridge rule targets a third-party API. The third-party API has not received any incoming traffic. A solutions architect needs to determine whether the rule conditions are being met and if the rule’s target is being invoked.
Which solution will meet these requirements?
- ✅ Check for metrics in Amazon CloudWatch in the namespace for AWS/Events.
- Review events in the Amazon Simple Queue Service (Amazon SQS) dead-letter queue.
- Check for the events in Amazon CloudWatch Logs.
- ❌ Check the trails in AWS CloudTrail for the EventBridge events.
✨ 关键词:
4️⃣ ❌ -> 1️⃣ ✅
💡 解析:监控亚马逊 EventBridge
EventBridge CloudWatch 每分钟向 Amazon 发送指标,从匹配的事件数到规则调用目标的次数,应有尽有。
AWS CloudTrail 是一项 AWS 服务,可帮助您实现 AWS 账户 的运营和风险审计、治理和合规性。用户、角色或 AWS 服务执行的操作将记录为 CloudTrail 中的事件。事件包括在 AWS Management Console、AWS Command Line Interface 和 AWS 开发工具包和 API 中执行的操作。
Amazon CloudWatch 可实时监控您的亚马逊云科技 (AWS) 资源以及您在 AWS 上运行的应用程序。您可以使用 CloudWatch 收集和跟踪指标,这些指标是您可衡量的相关资源和应用程序的变量。
👨👨👦👦 社区讨论:“EventBridge sends metrics to Amazon CloudWatch every minute foreverything from the number of matched events to the number of timesa target is invoked bya rule.”
from https://docs.aws.amazon.com/eventbridge/latest/userguide/eb-monitoring.htmlB: SQS, irrelevant
C: ‘Checkforevents’, this wording is confusing but could mean something in wrong context. I would have chosen C if A wasn’t an option
D: CloudTrail is for AWS resource monitoring so irrelevant
十六、Third-party CA on ACM
A company is creating a REST API. The company has strict requirements for the use of TLS. The company requires TLSv1.3 on the API endpoints. The company also requires a specific public third-party certificate authority (CA) to sign the TLS certificate.
Which solution will meet these requirements?
- ✅ Use a local machine to create a certificate that is signed by the third-party CImport the certificate into AWS Certificate Manager (ACM). Create an HTTP API in Amazon API Gateway with a custom domain. Configure the custom domain to use the certificate.
- ❌ Create a certificate in AWS Certificate Manager (ACM) that is signed by the third-party CA. Create an HTTP API in Amazon API Gateway with a custom domain. Configure the custom domain to use the certificate.
- Use AWS Certificate Manager (ACM) to create a certificate that is signed by the third-party CA. Import the certificate into AWS Certificate Manager (ACM). Create an AWS Lambda function with a Lambda function URL. Configure the Lambda function URL to use the certificate.
- Create a certificate in AWS Certificate Manager (ACM) that is signed by the third-party CA. Create an AWS Lambda function with a Lambda function URL. Configure the Lambda function URL to use the certificate.
✨ 关键词:
2️⃣ ❌ -> 1️⃣ ✅
💡 解析:无法在
ACM上申请第三方证书。
👨👨👦👦 社区讨论:I don’t understand why some many people vote B. In ACM, you can either request certificate from Amazon CA or import an existing certificate.There is no option in ACM that allow you to request a certificate that can be signed by third party CA.
十七、ACU
A company runs an application on AWS. The application receives inconsistent amounts of usage. The application uses AWS Direct Connect to connect to an on-premises MySQL-compatible database. The on-premises database consistently uses a minimum of 2 GiB of memory.
The company wants to migrate the on-premises database to a managed AWS service. The company wants to use auto scaling capabilities to manage unexpected workload increases.
Which solution will meet these requirements with the LEAST administrative overhead?
- Provision an Amazon DynamoDB database with default read and write capacity settings.
- ❌ Provision an Amazon Aurora database with a minimum capacity of 1 Aurora capacity unit (ACU).
- ✅ Provision an Amazon Aurora Serverless v2 database with a minimum capacity of 1 Aurora capacity unit (ACU).
- Provision an Amazon RDS for MySQL database with 2 GiB of memory.
✨ 关键词:
2️⃣ ❌ -> 3️⃣ ✅
Aurora Serverless v2 的计量单位是 Aurora 容量单位(ACU)。Aurora Serverless v2 容量与您用于预置集群的数据库实例类无关。
每个 ACU 是约 2 GiB 的内存、相应的 CPU 和网络的组合。您可以使用此计量单位指定数据库容量范围。
👨👨👦👦 社区讨论:The key reasons:
Aurora Serverless v2 providesauto-scaling so the database can handle inconsistent workloadsand spikesautomatically without admin intervention.
It can scale down to zero when not in use to minimize costs.
The minimum 1 ACU capacity is sufficient to replace the on-prem 2 GiB database based on the info given.
Serverless capabilities reduce admin overhead for capacity management.
DynamoDB lacks MySQL compatibilityand requires more hands-on management.
RDS and provisioned Aurora require manually resizing instances to scale, increasing admin overhead.
十八、Lambda SnapStart
A company wants to use an event-driven programming model with AWS Lambda. The company wants to reduce startup latency for Lambda functions that run on Java 11. The company does not have strict latency requirements for the applications. The company wants to reduce cold starts and outlier latencies when a function scales up.
Which solution will meet these requirements MOST cost-effectively?
- ❌ Configure Lambda provisioned concurrency.
- Increase the timeout of the Lambda functions.
- Increase the memory of the Lambda functions.
- ✅ Configure Lambda SnapStart.
✨ 关键词:
1️⃣ ❌ -> 4️⃣ ✅
💡 解析:使用 Lambda SnapStart 提高启动性能
适用于 Java 的 Lambda SnapStart 可以将延迟敏感型应用程序的启动性能提高多达 10 倍,而无需支付额外费用,通常也无需更改您的函数代码。导致启动延迟的最大因素(通常称为冷启动时间)是指 Lambda 在初始化函数上花费的时间,其中包括加载函数代码、启动运行时以及初始化函数代码。
支持的功能和限制
- SnapStart 支持 Java 11 和更高版本的 Java 托管运行时系统。不支持其他托管运行时系统(例如 nodejs20.x 和 python3.12)、仅限操作系统的运行时系统 和容器映像。
- SnapStart 不支持预置并发、Amazon Elastic File System(Amazon EFS)或大于 512MB 的短暂存储。
之后看到 Java11 +
Lambda的关键词要小心。
并且它和provisioned concurrency互斥。
👨👨👦👦 社区讨论:Both Lambda SnapStart and provisioned concurrency can reduce cold startsand outlier latencies when a function scales up. SnapStart helps you improve startup performance by up to 10x at no extra cost. Provisioned concurrency keeps functions initialized and ready to respond in double-digit milliseconds. Configuring provisioned concurrency incurs charges to your AWS account. Use provisioned concurrency if your application has strict cold start latency requirements. You can’t use both SnapStart and provisioned concurrency on the same function version.
十九、EBS
A company uses locally attached storage to run a latency-sensitive application on premises. The company is using a lift and shift method to move the application to the AWS Cloud. The company does not want to change the application architecture.
Which solution will meet these requirements MOST cost-effectively?
- ❌ Configure an Auto Scaling group with an Amazon EC2 instance. Use an Amazon FSx for Lustre file system to run the application.
- Host the application on an Amazon EC2 instance. Use an Amazon Elastic Block Store (Amazon EBS) GP2 volume to run the application.
- Configure an Auto Scaling group with an Amazon EC2 instance. Use an Amazon FSx for OpenZFS file system to run the application.
- ✅ Host the application on an Amazon EC2 instance. Use an Amazon Elastic Block Store (Amazon EBS) GP3 volume to run the application.
✨ 关键词:
1️⃣ ❌ -> 4️⃣ ✅
💡 解析:不想动架构的迁移,确实是部署到一台服务器上最好。
2️⃣ 和 4️⃣ 中 GP3 更便宜。
👨👨👦👦 社区讨论:gp3 offersSSD-performance at a 20% lower cost per GB than gp2 volumes.
二十、Multi-AZ Redis
A solutions architect is designing a highly available Amazon ElastiCache for Redis based solution. The solutions architect needs to ensure that failures do not result in performance degradation or loss of data locally and within an AWS Region. The solution needs to provide high availability at the node level and at the Region level.
Which solution will meet these requirements?
- ✅ Use Multi-AZ Redis replication groups with shards that contain multiple nodes.
- ❌ Use Redis shards that contain multiple nodes with Redis append only files (AOF) turned on.
- Use a Multi-AZ Redis cluster with more than one read replica in the replication group.
- Use Redis shards that contain multiple nodes with Auto Scaling turned on.
✨ 关键词:
2️⃣ ❌ -> 1️⃣ ✅
💡 解析:Redis AOF
Redis 分别提供了 RDB 和 AOF 两种持久化机制:
- RDB 将数据库的快照(snapshot)以二进制的方式保存到磁盘中。
- AOF 则以协议文本的方式,将所有对数据库进行过写入的命令(及其参数)记录到 AOF 文件,以此达到记录数据库状态的目的。
👨👨👦👦 社区讨论:It seems like “Multi-AZ Redis replication group” (A) and “Multi-AZ Redis cluster” (C) are different wordings for the same configuration. However, “to minimize the impact of a node failure, we recommend that your implementation use multiple nodes in each shard” - and that is mentioned only in A.
high availabilityat the node level = shard and Multi A-Z = region level
二十一、Glue
A research company uses on-premises devices to generate data for analysis. The company wants to use the AWS Cloud to analyze the data. The devices generate .csv files and support writing the data to an SMB file share. Company analysts must be able to use SQL commands to query the data. The analysts will run queries periodically throughout the day.
Which combination of steps will meet these requirements MOST cost-effectively? (Choose three.)
- ✅ Deploy an AWS Storage Gateway on premises in Amazon S3 File Gateway mode.
- ❌ Deploy an AWS Storage Gateway on premises in Amazon FSx File Gateway made.
- ✅ Set up an AWS Glue crawler to create a table based on the data that is in Amazon S3.
- Set up an Amazon EMR cluster with EMR File System (EMRFS) to query the data that is in Amazon S3. Provide access to analysts.
- ❌ Set up an Amazon Redshift cluster to query the data that is in Amazon S3. Provide access to analysts.
- ✅ Setup Amazon Athena to query the data that is in Amazon S3. Provide access to analysts.
✨ 关键词:
2️⃣ 5️⃣ 6️⃣ ❌ -> 1️⃣ 3️⃣ 6️⃣ ✅
💡 解析:
Amazon S3 File Gateway提供了 SMB 协议(NFS 也支持):创建 SMB 文件共享8. 对于使用以下工具访问对象,选择服务器消息块 (SMB).
因此 1️⃣ 是正确的。
在 AWS Glue 中使用 CSV 格式和 AWS Glue 概念AWS Glue 是一项完全托管式的 ETL(提取、转换、加载)服务,让您能够在不同的数据来源和目标之间轻松移动数据。关键组件包括:
- Data Catalog:一种元数据存储,其中包含 ETL 工作流的表定义、作业定义和其他控制信息。
- 爬网程序:连接到数据来源、推断数据架构以及在 Data Catalog 中创建元数据表定义的程序。
- ETL 作业:从源中提取数据、使用 Apache Spark 脚本进行转换并将其加载到目标中的业务逻辑。
- 触发器:基于计划或事件启动作业运行的机制。
典型的工作流涉及:
- 在 Data Catalog 中定义数据来源和目标。
- 通过爬网程序以使用来自数据来源的表元数据填充 Data Catalog。
- 使用转换脚本定义 ETL 作业,以移动和处理数据。
- 按需运行作业或基于触发器运行作业。
- 使用控制面板监控作业性能。
因此 3️⃣ 也正确。
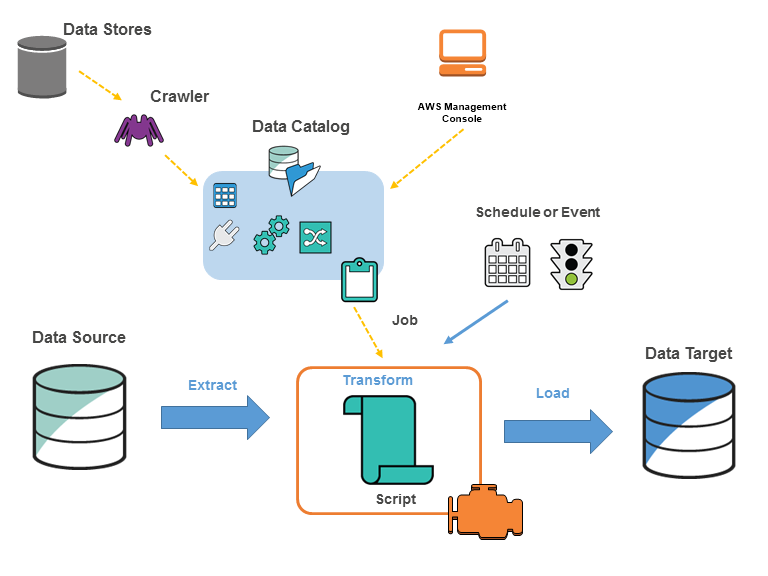
👨👨👦👦 社区讨论:SQL Queries is Athena so DE are wrong and we are now dependant on S3
A to get files into S3
C Glue to convert CSV to S3 table data
B irrelevant as we don’t have anything to consume data from FSx in other options