来源:Amazon AWS Certified Solutions Architect - Associate SAA-C03 Exam
50 题 (No.236 ~ No.285) 只记录了 14 道首次碰到的、错误的或有疑问的题目,仅供自己复习使用。
如果侵权请联系删除。
🌟 单词:
- layern. 层,层次,表层,阶层 | v. 把…分层堆放
- beanstalkn. 豆茎
- amplifyv. 放大,阐发
- budgetn. 预算 | v. 做预算;节省开支 | adj. 不贵的,廉价的
- associatev. 联系,联想 | n. 同事;合作人;伙伴 | adj. (等级或头衔)副的;准的
- hierarchicaladj. 按等级划分的,等级制度的
- structuredadj. 有结构的;有组织的 | v. 组织;构成(“structure”的过去式和过去分词)
一、Three-tier application HA
A company has a three-tier application for image sharing. The application uses an Amazon EC2 instance for the front-end layer, another EC2 instance for the application layer, and a third EC2 instance for a MySQL database. A solutions architect must design a scalable and highly available solution that requires the least amount of change to the application.
Which solution meets these requirements?
- Use Amazon S3 to host the front-end layer. Use AWS Lambda functions for the application layer. Move the database to an Amazon DynamoDB table. Use Amazon S3 to store and serve users’ images.
- Use load-balanced Multi-AZ AWS Elastic Beanstalk environments for the front-end layer and the application layer. Move the database to an Amazon RDS DB instance with multiple read replicas to serve users’ images.
- Use Amazon S3 to host the front-end layer. Use a fleet of EC2 instances in an Auto Scaling group for the application layer. Move the database to a memory optimized instance type to store and serve users’ images.
- ✅ Use load-balanced Multi-AZ AWS Elastic Beanstalk environments for the front-end layer and the application layer. Move the database to an Amazon RDS Multi-AZ DB instance. Use Amazon S3 to store and serve users’ images.
✨ 关键词:three-tier application
4️⃣ ✅
💡 解析:前端、后端和数据库三层应用需要高可用化。
AWS Elastic Beanstalk是用来简化应用程序部署流程的,并且使你不需要维护相关的EC2等基础设施:什么是 AWS Elastic Beanstalk?借助 Elastic Beanstalk,您可以在 AWS Cloud 中快速部署和管理应用程序,而不必了解运行这些应用程序的基础设施。
Elastic Beanstalk 支持在 Go、Java、.NET、Node.js、PHP、Python 和 Ruby 中开发的应用程序。Elastic Beanstalk 还支持 Docker 平台。
顺便带一下 TypeScript 技术栈的 AWS 相关应用服务:AWS Amplify
凭借全栈 TypeScript 功能,Amplify 将 AWS 服务的强大功能和广度融入熟悉的前端开发人员体验中。只需在 TypeScript 中编写数据模型、业务逻辑和身份验证规则等应用程序需求即可。Amplify 会自动配置正确的云资源并将其部署到每个开发人员的云沙盒环境中,以实现快速的本地迭代。
👨👨👦👦 社区讨论:B and D very similar with D being the ‘best’ solution but it is not the one that requires the least amount of development changesas the application would need to be changed to store images in S3 instead of DB
二、Cost notification
A company wants to experiment with individual AWS accounts for its engineer team. The company wants to be notified as soon as the Amazon EC2 instance usage for a given month exceeds a specific threshold for each account.
What should a solutions architect do to meet this requirement MOST cost-effectively?
- Use Cost Explorer to create a daily report of costs by service. Filter the report by EC2 instances. Configure Cost Explorer to send an Amazon Simple Email Service (Amazon SES) notification when a threshold is exceeded.
- Use Cost Explorer to create a monthly report of costs by service. Filter the report by EC2 instances. Configure Cost Explorer to send an Amazon Simple Email Service (Amazon SES) notification when a threshold is exceeded.
- ✅ Use AWS Budgets to create a cost budget for each account. Set the period to monthly. Set the scope to EC2 instances. Set an alert threshold for the budget. Configure an Amazon Simple Notification Service (Amazon SNS) topic to receive a notification when a threshold is exceeded.
- Use AWS Cost and Usage Reports to create a report with hourly granularity. Integrate the report data with Amazon Athena. Use Amazon EventBridge to schedule an Athena query. Configure an Amazon Simple Notification Service (Amazon SNS) topic to receive a notification when a threshold is exceeded.
✨ 关键词:individual AWS accounts、cost notification
3️⃣ ✅
💡 解析:公司需要得到通知如果账户的
EC2使用量触发了给定的限额。
使用 AWS 预算管理成本 (AWS Budgets)您可以使用 AWS 预算来跟踪 AWS 成本和使用情况并采取行动。您可以使用 AWS 预算来监控您的预留实例 (RIs) 或 Savings Plans 的总利用率和覆盖率指标。
Amazon Simple Email Service (SES) 是一个电子邮件平台,它为您提供一种简单、经济实惠的方式,让您使用自己的电子邮件地址和域名发送和接收电子邮件。
需要注意的是,
SNS通过邮件订阅(通知以邮件形式发送),是不需要使用到SES服务的,它有自己的计费:Amazon SNS 定价
终端节点类型 免费套餐 价格 电子邮件/电子邮件-JSON 1000 个通知 每 10 万个通知 USD 2.00
👨👨👦👦 社区讨论:AWS Budgets allows you to create budgets for your AWS accountsand set alerts when usage exceedsa certain threshold. By creating a budget foreach account, specifying the period as monthlyand the scope asEC2 instances, you can effectively track the EC2 usage foreach account and be notified when a threshold isexceeded.This solution is the most cost-effective option as it does not require additional resources such as Amazon Athena or Amazon EventBridge.
三、ALB to private subnet
A company runs a web application on Amazon EC2 instances in multiple Availability Zones. The EC2 instances are in private subnets. A solutions architect implements an internet-facing Application Load Balancer (ALB) and specifies the EC2 instances as the target group. However, the internet traffic is not reaching the EC2 instances.
How should the solutions architect reconfigure the architecture to resolve this issue?
- Replace the ALB with a Network Load Balancer. Configure a NAT gateway in a public subnet to allow internet traffic.
- Move the EC2 instances to public subnets. Add a rule to the EC2 instances’ security groups to allow outbound traffic to 0.0.0.0/0.
- ❌ Update the route tables for the EC2 instances’ subnets to send 0.0.0.0/0 traffic through the internet gateway route. Add a rule to the EC2 instances’ security groups to allow outbound traffic to 0.0.0.0/0.
- ✅ Create public subnets in each Availability Zone. Associate联系 the public subnets with the ALB. Update the route tables for the public subnets with a route to the private subnets.
✨ 关键词:private subnet、ALB、the internet traffic is not reaching the EC2 instances
3️⃣ ❌ -> 4️⃣ ✅
💡 解析:流量无法通过
ALB到达私有子网中的EC2实例。
3️⃣ 选项中的第一个操作是更新EC2所在子网的路由表,使得来自公网的流量能够流经互联网网关,这看上去没有什么问题。但是社区讨论中指出了来自互联网的流量会通过ALB的弹性网络接口 (ENIs, Elastic Network Interfaces)来到EC2实例。
看上去是这样的。
而安全组默认是放行所有出栈流量的,因此 3️⃣ 的两个操作都没有必要。4️⃣ 的操作是为每个可用区创建一个公有子网,将公有子网与
ALB绑定,然后更新路由表将流量路由到私有子网。
唯一的正解。社区中有人提到 4️⃣ 的第二个操作没有必要 “no need as the local prefix entry in the route tables would take care of this point”,这是对的。
同一VPC内的子网默认有一条本地的路由,可以互相访问:客户 Amazon VPC 内部资源和服务的相互访问如下图所示,由于主路由表和各个子网隐式关联,因此,上述两个路由表中都可以看到一条本地路由,这条本地路由的目的地(Destination)为 VPC 关联的 CIDR 10.192.0.0/16,目标(Target)为 local, 这里 local 代表一个用于在 VPC 内部通信的本地路由。

👨👨👦👦 社区讨论:I think either the question or the answersare not formulated correctly because of this document:
https://docs.aws.amazon.com/prescriptive-guidance/latest/load-balancer-stickiness/subnets-routing.htmlA - Might be possible but it’s quite impractical
B - Not needed as the setup described should workas is provided the SGs of the EC2 instancesaccept traffic from the ALB
C - Update the route tables for the EC2 instances’ subnets to send 0.0.0.0/0 traffic through the internet gateway route - not needed as the EC2 instances would receive the traffic from the ALB ENIs. Add a rule to the EC2 instances’ security groups to allow outbound traffic to 0.0.0.0/0 - the default behaviour of the SG is to allow outbound traffic only.
D - Create public subnets in each Availability Zone. Associate the public subnets with the ALB - if it’sa internet facing ALB these should already be in place. Update the route tables for the public subnets with a route to the private subnets - no need as the local prefix entry in the route tables would take care of this pointI’m 110% sure the question or answers or both are wrong. Prove me wrong! :)
四、RDS read replica
A company has deployed a database in Amazon RDS for MySQL. Due to increased transactions, the database support team is reporting slow reads against the DB instance and recommends adding a read replica.
Which combination of actions should a solutions architect take before implementing this change? (Choose two.)
- ❌ Enable binlog replication on the RDS primary node.
- Choose a failover priority for the source DB instance.
- ✅ Allow long-running transactions to complete on the source DB instance.
- ❌ Create a global table and specify the AWS Regions where the table will be available.
- ✅ Enable automatic backups on the source instance by setting the backup retention period to a value other than 0.
✨ 关键词:
1️⃣ 4️⃣ ❌ -> 3️⃣ 5️⃣ ✅
💡 解析:数据库读取慢,需要只读副本。
首先来看下 binlog:必须了解的MySQL三大日志:binlog、redo log和undo logbinlog
binlog用于记录数据库执行的写入性操作(不包括查询)信息,以二进制的形式保存在磁盘中。binlog 使用场景
在实际应用中,binlog的主要使用场景有两个,分别是主从复制和数据恢复。
- 主从复制:在Master端开启binlog,然后将binlog发送到各个Slave端,Slave端重放binlog从而达到主从数据一致。
- 数据恢复:通过使用mysqlbinlog工具来恢复数据。
虽然使用场景符合,但是它似乎是只能在自建的数据库上开启的,虽然也能获取
RDS for MySQL的 binlog,但是并不常用:配置、启动和停止二进制日志(binlog)复制
而Global Table是DynamoDB的,因此 4️⃣ 不对。3️⃣ 的 “long-running transactions” 是长时间运行的事务,不理解开启它的意义。
5️⃣ 是创建只读副本的必要措施,需要开启自动备份并将保留时间设置不为 0 的值(我依然没有找到出处,但是这是社区的共识)。
👨👨👦👦 社区讨论:C,E
”An active, long-running transaction can slow the process of creating the read replica. We recommend that you wait for long-running transactions to complete before creating a read replica. If you create multiple read replicas in parallel from the same source DB instance, Amazon RDS takes only one snapshot at the start of the first create action.
When creating a read replica, there are a few things to consider. First, you must enable automatic backups on the source DB instance by setting the backup retention period to a value other than 0.This requirement also applies to a read replica that is the source DB instance for another read replica”
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_ReadRepl.html
五、SMB
A company is implementing a shared storage solution for a media application that is hosted in the AWS Cloud. The company needs the ability to use SMB clients to access data. The solution must be fully managed.
Which AWS solution meets these requirements?
- Create an AWS Storage Gateway volume gateway. Create a file share that uses the required client protocol. Connect the application server to the file share.
- Create an AWS Storage Gateway tape gateway. Configure tapes to use Amazon S3. Connect the application server to the tape gateway.
- Create an Amazon EC2 Windows instance. Install and configure a Windows file share role on the instance. Connect the application server to the file share.
- ✅ Create an Amazon FSx for Windows File Server file system. Attach the file system to the origin server. Connect the application server to the file system.
✨ 关键词:SMB
4️⃣ ✅
💡 解析:需要使用 SMB 访问存储,并且存储完全可管理。
NFS 和 SMB 之间有什么区别?
- SMB 协议是 Windows 原生文件共享的默认协议。Windows 功能是围绕 SMB 构建的。您需要 Samba 等外部工具才能在 Linux 计算机上使用 SMB 来访问远程 Windows 服务器文件。
- NFS 协议是专门为 Unix 系统设计的。它是大多数 Linux 发行版中的原生文件共享协议,也是默认的文件传输协议。
因此这里需要选择与 Windows 相关的 3️⃣ 或者 4️⃣。
挂载支持 SMB 的文件系统很符合直觉。
👨👨👦👦 社区讨论:SMB + fully managed = fsx for windows imo
Amazon FSx has native support for Windows file system featuresand for the industry-standard Server Message Block(SMB) protocol to access file storage over a network.
https://docs.aws.amazon.com/fsx/latest/WindowsGuide/what-is.html
六、Security Group ID
A company is reviewing a recent migration of a three-tier application to a VPC. The security team discovers that the principle of least privilege is not being applied to Amazon EC2 security group ingress and egress rules between the application tiers.
What should a solutions architect do to correct this issue?
- ❌ Create security group rules using the instance ID as the source or destination.
- ✅ Create security group rules using the security group ID as the source or destination.
- Create security group rules using the VPC CIDR blocks as the source or destination.
- Create security group rules using the subnet CIDR blocks as the source or destination.
✨ 关键词:Security Group、PoLP
1️⃣ ❌ -> 2️⃣ ✅
💡 解析:实例的安全组需要使用最小权限原则。
涉及到引用安全组 (Security group referencing):引用安全组当您指定一个安全组作为规则的源或目标时,该规则会影响与安全组关联的所有实例。实例可以使用其私有 IP 地址,通过指定的协议和端口沿指定方向进行通信。
例如,下面的内容表示安全组的入站规则,该入站规则引用了安全组 sg-0abcdef1234567890。此规则允许来自与 sg-0abcdef1234567890 关联的实例的入站 SSH 流量。
来源 协议 端口范围 sg-0abcdef1234567890 TCP 22 在安全组规则中引用安全组时,请注意以下几点:
- 两个安全组必须属于同一 VPC 或对等 VPC。
- 不得向引用安全组的安全组添加引用安全组中的任何规则。
- 对于入站规则,与安全组关联的 EC2 实例可以接收来自与引用安全组关联的 EC2 实例的私有 IP 地址的入站流量。
- 对于出站规则,与安全组关联的 EC2 实例可以向与引用安全组关联的 EC2 实例的私有 IP 地址发送出站流量。
这意味着,对安全组的引用时链式的,2️⃣ 既可以实现最小权限原则,又易于后续的实例扩容。
👨👨👦👦 社区讨论:B. Create security group rules using the security group ID as the source or destination.
This way, the security team can ensure that the least privileged access is given to the application tiers byallowing only the necessary communication between the security groups. Forexample, the web tier security group should onlyallow incoming traffic from the load balancer security group and outgoing traffic to the application tier security group.Thisapproach provides a more granular and secure way to control traffic between the different tiers of the application and also allows foreasy modification of access if needed.
It’salso worth noting that it’s good practice to minimize the number of open portsand protocols,and use security groupsasa first line of defense, in addition to networkaccess control lists (ACLs) to control traffic between subnets.
七、Auto Scaling status data
A company is building a solution that will report Amazon EC2 Auto Scaling events across all the applications in an AWS account. The company needs to use a serverless solution to store the EC2 Auto Scaling status data in Amazon S3. The company then will use the data in Amazon S3 to provide near-real-time updates in a dashboard. The solution must not affect the speed of EC2 instance launches.
How should the company move the data to Amazon S3 to meet these requirements?
- ✅ Use an Amazon CloudWatch metric stream to send the EC2 Auto Scaling status data to Amazon Kinesis Data Firehose. Store the data in Amazon S3.
- Launch an Amazon EMR cluster to collect the EC2 Auto Scaling status data and send the data to Amazon Kinesis Data Firehose. Store the data in Amazon S3.
- ❌ Create an Amazon EventBridge rule to invoke an AWS Lambda function on a schedule. Configure the Lambda function to send the EC2 Auto Scaling status data directly to Amazon S3.
- Use a bootstrap script during the launch of an EC2 instance to install Amazon Kinesis Agent. Configure Kinesis Agent to collect the EC2 Auto Scaling status data and send the data to Amazon Kinesis Data Firehose. Store the data in Amazon S3.
✨ 关键词:serverless、store the EC2 Auto Scaling status data in Amazon S3
3️⃣ ❌ -> 1️⃣ ✅
💡 解析:需要将
EC2弹性的状态数据存储到S3存储桶中。使用无服务的解决方案。
3️⃣ 错在定时 (on a schedule) 调用了Lambda。
👨👨👦👦 社区讨论:B - EMR cluster is for Big Data, has nothing to do with this
C - invokes the function “on a schedule”, but you want to capture events
D - Could work, but would be overcomplex and would “affect the speed of EC2 instance launches” (which it should not)This solution meets the requirements because it is serverlessand does not affect the speed of EC2 instance launches. Amazon CloudWatch metric streams can continuously stream CloudWatch metrics to destinations such as Amazon S3. Amazon Kinesis Data Firehose can capture, transform,and deliver streaming data into data lakes, data stores,and analytics services. It can directly put the data into Amazon S3, which can then be used for near-real-time updates in a dashboard.
八、Windows file server and AD
A company’s compliance team needs to move its file shares to AWS. The shares run on a Windows Server SMB file share. A self-managed on-premises Active Directory controls access to the files and folders.
The company wants to use Amazon FSx for Windows File Server as part of the solution. The company must ensure that the on-premises Active Directory groups restrict access to the FSx for Windows File Server SMB compliance shares, folders, and files after the move to AWS. The company has created an FSx for Windows File Server file system.
Which solution will meet these requirements?
- ❌ Create an Active Directory Connector to connect to the Active Directory. Map the Active Directory groups to IAM groups to restrict access.
- Assign a tag with a Restrict tag key and a Compliance tag value. Map the Active Directory groups to IAM groups to restrict access.
- Create an IAM service-linked role that is linked directly to FSx for Windows File Server to restrict access.
- ✅ Join the file system to the Active Directory to restrict access.
✨ 关键词:on-premises AD
1️⃣ ❌ -> 4️⃣ ✅
💡 解析:需要将 AWS 上的 Windows 文件系统加入自建的
AD域中。
将亚马逊FSx文件系统加入自我管理的 Microsoft Active Directory 域当你FSx为 Windows 文件服务器创建新的文件系统时,你可以配置 Microsoft Active Directory 集成,使其加入你自行管理的 Microsoft Active Directory 域。为此,请为您的 Microsoft Active Directory 提供以下信息:
- 您的本地 Microsoft Active Directory 目录的完全限定域名 (FQDN)。
- 您的域名DNS服务器的 IP 地址。
- 本地 Microsoft Active Directory 域中的服务账户凭证。Amazon FSx 使用这些凭证加入您自行管理的活动目录。
因此不需要做什么特别的操作,直接将文件系统加入现有 AD 域中即可,即使它是自建的。
👨👨👦👦 社区讨论:D. Join the file system to the Active Directory to restrict access.
Joining the FSx for Windows File Server file system to the on-premises Active Directory will allow the company to use the existing Active Directory groups to restrict access to the file shares, folders,and filesafter the move to AWS.This option allows the company to continue using theirexisting access controlsand management structure, making the transition to AWS more seamless.D.allows the file system to leverage the existing AD infrastructure for authentication and access control.
Option A is incorrect because mapping the AD groups to IAM groups is not applicable in this scenario. IAM is primarily used for managing access to AWS resources, while the requirement is to integrate with the on-premises AD for access control.
Option B is incorrect because assigning a tag with a Restrict tag keyand a Compliance tag value does not provide the necessary integration with the on-premises AD for access control.Tagsare used for organizing and categorizing resourcesand do not provide authentication or access control mechanisms.
Option C is incorrect because creating an IAM service-linked role linked directly to FSx for Windows File Server does not integrate with the on-premises AD. IAM rolesare used within AWS for managing permissionsand do not provide the necessary integration with external AD systems.
九、Health check
A company has a web application hosted over 10 Amazon EC2 instances with traffic directed by Amazon Route 53. The company occasionally experiences a timeout error when attempting to browse the application. The networking team finds that some DNS queries return IP addresses of unhealthy instances, resulting in the timeout error.
What should a solutions architect implement to overcome these timeout errors?
- Create a Route 53 simple routing policy record for each EC2 instance. Associate a health check with each record.
- ❌ Create a Route 53 failover routing policy record for each EC2 instance. Associate a health check with each record.
- Create an Amazon CloudFront distribution with EC2 instances as its origin. Associate a health check with the EC2 instances.
- ✅ Create an Application Load Balancer (ALB) with a health check in front of the EC2 instances. Route to the ALB from Route 53.
✨ 关键词:Amazon Route 53、health check
2️⃣ ❌ -> 4️⃣ ✅
💡 解析:
Route53的 DNS 寻址返回了不可用实例的 IP 导致超时错误。
这里 1️⃣ 和 2️⃣ 其实都对,他们都可以做到将流量分发到实例并开启健康检查:简单 Amazon Route 53 配置中的运行状况检查的工作原理当有两个或更多资源执行相同功能 (例如用于 example.com 的两个或更多 Web 服务器) 时,可使用下列运行状况检查功能,将流量仅路由到运行状况良好的资源。
如果您在记录中指定多个值,则 Route 53 将所有值以随机顺序返回到递归解析程序。
但是 4️⃣ 是个更好的选择,后续扩容也不需要修改 DNS 记录。我也更推崇 4️⃣。
👨👨👦👦 社区讨论:ALB performs health checks on the EC2 instances, so it will only route traffic to healthy instances.Thisavoids the timeout errors.
ALB provides load balancing across the instances, improving performance and availability.
Route 53 routes to the ALB DNS name, so you don’t have to manage records foreach EC2 instance.
This is a standard and robust architecture for public-facing web applications. The ALB acts as the entry point and handles health checksand scaling.
十、Amazon Aurora Global Database and DR infrastructure
A rapidly growing ecommerce company is running its workloads in a single AWS Region. A solutions architect must create a disaster recovery (DR) strategy that includes a different AWS Region. The company wants its database to be up to date in the DR Region with the least possible latency. The remaining infrastructure in the DR Region needs to run at reduced capacity and must be able to scale up if necessary.
Which solution will meet these requirements with the LOWEST recovery time objective (RTO)?
- Use an Amazon Aurora global database with a pilot light deployment.
- ✅ Use an Amazon Aurora global database with a warm standby deployment.
- Use an Amazon RDS Multi-AZ DB instance with a pilot light deployment.
- ❌ Use an Amazon RDS Multi-AZ DB instance with a warm standby deployment.
✨ 关键词:LOWEST RTO
4️⃣ ❌ -> 2️⃣ ✅
💡 解析:需要在另一个区域部署缩小的架构,并能在灾难发生时扩容到主架构大小。
首先看下Pilot light和Warm standby(温备用)的区别:云中的灾难恢复选项
Pilot Light- 您可以将数据从一个区域复制到另一个区域,并预置核心工作负载基础设施的副本。
支持数据复制和备份所需的资源(如数据库和对象存储)始终处于开启状态。
其他元素(例如应用程序服务器)加载了应用程序代码和配置,处于关闭状态,仅在测试期间或调用灾难恢复故障转移时使用。
不同于备份与还原方法,您的核心基础设施始终可用,而且您始终可以选择通过打开和横向扩展应用程序服务器来快速预置完整的生产环境。Warm standby(温备用)- 温备用方法包括确保在另一个区域中有一个缩减但功能齐全的生产环境副本。
这种方法扩展了Pilot Light的概念,缩短了恢复时间,因为您的工作负载在另一个区域中始终可用。此方法还使您能够更轻松地执行测试或实施连续测试,从而增强从灾难中恢复的信心。注意:Pilot Light 和温备用之间的差异有时难以区分。两者都包含灾难恢复区域中的环境,该环境包含主区域资产的副本。
区别在于,如果不首先执行其他操作,Pilot Light 就无法处理请求,而温备用可以立即处理流量(在产能降低的情况下)。
Pilot Light 方法要求您“打开”服务器,可能还需要部署其他(非核心)基础设施并纵向扩展;而温备用只需纵向扩展(一切均已部署并正在运行)。因此在本题中,无疑需要选择
Warm standby(温备用)。
再来看下Amazon Aurora 全球数据库的概念:Amazon Aurora 全球数据库Amazon Aurora Global Database 针对全球分布式应用程序而设计,允许单个 Amazon Aurora 数据库跨越多个 AWS 区域。它在不影响数据库性能的情况下复制您的数据,在每个区域中实现低延迟的快速本地读取,并且在发生区域级的中断时提供灾难恢复能力。
无论辅助区域的数量和位置如何,您的应用程序都享受快速数据访问,典型的跨区域复制延迟小于 1 秒。这和
DynamoDB的Global Table的概念大致相同:Amazon DynamoDB 全局表DynamoDB 全局表由多个副本表组成。每个副本表存在于不同的区域中,但所有副本都具有相同的名称和主键。当数据写入任何副本表时,DynamoDB 会自动将该数据复制到全局表中的所有其他副本表。
在全局表中,新写入的项目通常会在一秒钟内传播到所有副本表中。
👨👨👦👦 社区讨论:Note:The difference between pilot light and warm standby can sometimes be difficult to understand. Both include an environment in your DR Region with copies of your primary Region assets.The distinction is that pilot light cannot process requests without additional action taken first, whereas warm standby can handle traffic (at reduced capacity levels) immediately.The pilot light approach requires you to “turn on” servers, possibly deployadditional (non-core) infrastructure, and scale up, whereas warm standby only requires you to scale up (everything isalready deployed and running). Use your RTO and RPO needs to help you choose between these approaches.
https://docs.aws.amazon.com/whitepapers/latest/disaster-recovery-workloads-on-aws/disaster-recovery-options-in-the-cloud.html
十一、Database instance out of storage
A company has a multi-tier application deployed on several Amazon EC2 instances in an Auto Scaling group. An Amazon RDS for Oracle instance is the application’ s data layer that uses Oracle-specific PL/SQL functions. Traffic to the application has been steadily increasing. This is causing the EC2 instances to become overloaded and the RDS instance to run out of storage.
The Auto Scaling group does not have any scaling metrics and defines the minimum healthy instance count only. The company predicts that traffic will continue to increase at a steady but unpredictable rate before leveling off.
What should a solutions architect do to ensure the system can automatically scale for the increased traffic? (Choose two.)
- ✅ Configure storage Auto Scaling on the RDS for Oracle instance.
- ❌ Migrate the database to Amazon Aurora to use Auto Scaling storage.
- Configure an alarm on the RDS for Oracle instance for low free storage space.
- ✅ Configure the Auto Scaling group to use the average CPU as the scaling metric.
- Configure the Auto Scaling group to use the average free memory as the scaling metric.
✨ 关键词:Database instance out of storage
2️⃣ 4️⃣ ❌ -> 1️⃣ 4️⃣ ✅
💡 解析:
Amazon RDS for Oracle实例的存储超了,且部署应用的EC2弹性扩容组也需要设置新的指标。
来看下RDS for Oracle的创建过程:
因此我们明确,
RDS的数据库创建是需要指定EC2实例(类型)的。
那它如何实现存储的扩容呢,官方给了解决方案:使用 Amazon RDS 存储自动扩展功能自动管理容量如果您的工作负载是不可预测的,则可以为 Amazon RDS 数据库实例启用存储自动扩展。为此,您可以使用 Amazon RDS 控制台、Amazon RDS API 或 AWS CLI。
如果启用了存储自动扩展,在 Amazon RDS 检测到可用数据库空间不足时,则会自动扩展存储。在以下因素适用时,Amazon RDS 会为启用了自动扩展的数据库实例启动存储修改:
- 可用空间小于或等于所分配的存储空间的 10%。
- 存储空间不足状态至少持续 5 分钟。
- 自上次存储修改以来,至少已过去 6 小时;或在实例上完成存储优化后,至少已过去 6 小时。
因此 1️⃣ 是成立的。
关于 5️⃣,官方并没有支持内存指标,你需要通过安装CloudWatch Agent并做相应配置:How to create an Amazon EC2 Auto Scaling policy based on a memory utilization metric (Linux)
在用户访问的场景下,CPU 指标更简单也更好。
👨👨👦👦 社区讨论:A) Configure storage Auto Scaling on the RDS for Oracle instance.
= Makes sense. With RDS Storage Auto Scaling, you simply set your desired maximum storage limit,and Auto Scaling takes care of the rest.B) Migrate the database to Amazon Aurora to use Auto Scaling storage.
= Scenario specifiesapplication’s data layer uses Oracle-specific PL/SQL functions.This rules out migration to Aurora.C) Configure an alarm on the RDS for Oracle instance for low free storage space.
= You could do this but what does it fix? Nothing.The CW notification isn’t going to trigger anything.D) Configure the Auto Scaling group to use the average CPU as the scaling metric. = Makes sense.The CPU utilization is the precursor to the storage outage. When the ec2 instancesare overloaded, the RDS instance storage hits its limits, too.
十二、Hierarchical structured data
A company wants to create an application to store employee data in a hierarchical按等级划分的 structured有结构的 relationship. The company needs a minimum-latency response to high-traffic queries for the employee data and must protect any sensitive data. The company also needs to receive monthly email messages if any financial information is present in the employee data.
Which combination of steps should a solutions architect take to meet these requirements? (Choose two.)
- Use Amazon Redshift to store the employee data in hierarchies. Unload the data to Amazon S3 every month.
- ✅ Use Amazon DynamoDB to store the employee data in hierarchies. Export the data to Amazon S3 every month.
- ❌ Configure Amazon Macie for the AWS account. Integrate Macie with Amazon EventBridge to send monthly events to AWS Lambda.
- Use Amazon Athena to analyze the employee data in Amazon S3. Integrate Athena with Amazon QuickSight to publish analysis dashboards and share the dashboards with users.
- ✅ Configure Amazon Macie for the AWS account. Integrate Macie with Amazon EventBridge to send monthly notifications through an Amazon Simple Notification Service (Amazon SNS) subscription.
✨ 关键词:minimum-latency response to high-traffic queries for the data、protect sensitive data、receive monthly email messages
3️⃣ 5️⃣ ❌ -> 2️⃣ 5️⃣ ✅
💡 解析:需要快速检索雇员数据,并保护其隐私。如果有财务信息被包含的话,需要按月发信通知。
Amazon Macie 功能
- Amazon Macie 是一种数据安全服务,它使用机器学习和模式匹配来发现敏感数据,提供对数据安全风险的可见性,并使您能够自动防御这些风险。为了帮助您管理 Amazon S3 环境的数据安全状况,Macie 不断评估您的 S3 存储桶的安全性和访问控制,并生成结果,以通知您未加密的存储桶、可公开访问的存储桶以及与您组织外部的 AWS 账户共享的存储桶等问题。
- 然后,Macie 会自动对 S3 存储桶中的对象进行采样和分析,检查它们是否包含个人身份信息(PII)等敏感数据,构建 S3 中敏感数据跨账户所在位置的交互式数据映射,并为每个存储桶提供敏感度分数。
在这里,
Amazon Macie就完成了对雇员敏感信息的甄别需求。
而关于DynamoDB对有层级结构信息的存储,官方是这么解决的:Model hierarchical automotive component data using Amazon DynamoDB
Partition Key (ComponentId) Location on graph (GraphId) Parent-child relationship (ParentId) Path V1 V1#1 – V1 B11 V1#1 V1 V1 M111 V1#1 V1 V1 C1111 V1#1 V1 V1 暂时没看懂 🤦 不过总之
DynamoDB在分层数据建模方面有优势就是了:分层数据建模示例
👨👨👦👦 社区讨论:Data in hierarchies : Amazon DynamoDB
B. Use Amazon DynamoDB to store the employee data in hierarchies.Export the data to Amazon S3 every month.Sensitive Info: Amazon Macie
E. Configure Amazon Macie for the AWS account. Integrate Macie with Amazon EventBridge to send monthly notifications through an Amazon Simple Notification Service (Amazon SNS) subscription.
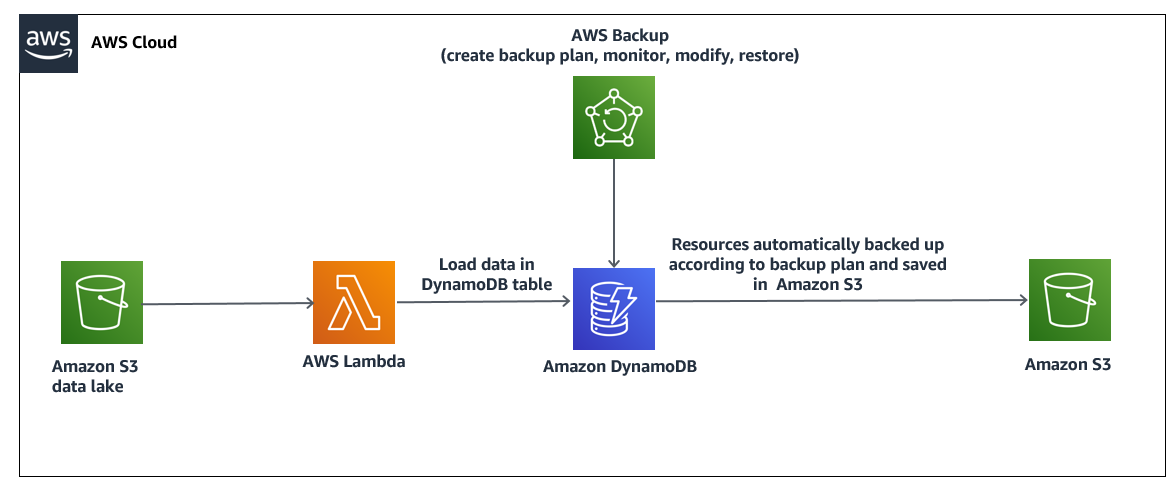
十三、DynamoDB backups
A company has an application that is backed by an Amazon DynamoDB table. The company’s compliance requirements specify that database backups must be taken every month, must be available for 6 months, and must be retained for 7 years.
Which solution will meet these requirements?
- ✅ Create an AWS Backup plan to back up the DynamoDB table on the first day of each month. Specify a lifecycle policy that transitions the backup to cold storage after 6 months. Set the retention period for each backup to 7 years.
- Create a DynamoDB on-demand backup of the DynamoDB table on the first day of each month. Transition the backup to Amazon S3 Glacier Flexible Retrieval after 6 months. Create an S3 Lifecycle policy to delete backups that are older than 7 years.
- Use the AWS SDK to develop a script that creates an on-demand backup of the DynamoDB table. Set up an Amazon EventBridge rule that runs the script on the first day of each month. Create a second script that will run on the second day of each month to transition DynamoDB backups that are older than 6 months to cold storage and to delete backups that are older than 7 years.
- Use the AWS CLI to create an on-demand backup of the DynamoDB table. Set up an Amazon EventBridge rule that runs the command on the first day of each month with a cron expression. Specify in the command to transition the backups to cold storage after 6 months and to delete the backups after 7 years.
✨ 关键词:backup must be available for 6 months、must be retained for 7 years
1️⃣ ✅
💡 解析:需要备份
DynamoDB数据库,6 个月内可用并存档 7 年。
首先看下AWS Backup是否支持定时备份以及生命周期:备份计划选项和配置Backup frequency (备份频率)
备份频率决定了 AWS Backup 创建快照备份的频率。使用控制台,您可从每小时、每 12 个小时、每天、每周或每月中选择频率。您还可以创建 Cron 表达式,以每小时一次的频率创建快照备份。使用 AWS Backup CLI,您可以将快照备份的频率安排为每小时一次。生命周期和存储层 备份将存储您指定的天数(即备份生命周期)。备份可以还原,直到其生命周期结束。
每个备份都已创建并存储在暖存储中。根据您选择的备份存储时间长短,您可能希望将备份转移到成本较低的层(名为“冷存储”)。再看下
AWS Backup的作用范围:
Amazon EBSAmazon EC2Amazon RDSAmazon DynamoDBAmazon EFSAWS Storage GatewayAmazon FSx
EC2、数据库和文件系统,因此 1️⃣ 完全正确。
2️⃣ 似乎也没有错误,且官方也有推荐将存储备份到S3存储桶中:Set up scheduled backups for Amazon DynamoDB using AWS Backup
但是我是觉得只使用
S3 Glacier Flexible Retrieval这个存储桶是不对的,题目明确有访问频率的变化。
👨👨👦👦 社区讨论:Option B mentions using Amazon S3 Glacier Flexible Retrieval, but DynamoDB doesn’t natively support transitioning backups to Amazon S3 Glacier. Options C and D involve custom scripts and EventBridge rules, which add complexity and may not be as reliable or efficient as using AWS Backup for this purpose.
https://docs.aws.amazon.com/aws-backup/latest/devguide/creating-a-backup-plan.html
十四、Amazon FSx for NetApp ONTAP
A research company runs experiments that are powered by a simulation application and a visualization application. The simulation application runs on Linux and outputs intermediate data to an NFS share every 5 minutes. The visualization application is a Windows desktop application that displays the simulation output and requires an SMB file system.
The company maintains two synchronized file systems. This strategy is causing data duplication and inefficient resource usage. The company needs to migrate the applications to AWS without making code changes to either application.
Which solution will meet these requirements?
- Migrate both applications to AWS Lambda. Create an Amazon S3 bucket to exchange data between the applications.
- Migrate both applications to Amazon Elastic Container Service (Amazon ECS). Configure Amazon FSx File Gateway for storage.
- Migrate the simulation application to Linux Amazon EC2 instances. Migrate the visualization application to Windows EC2 instances. Configure Amazon Simple Queue Service (Amazon SQS) to exchange data between the applications.
- ✅ Migrate the simulation application to Linux Amazon EC2 instances. Migrate the visualization application to Windows EC2 instances. Configure Amazon FSx for NetApp ONTAP for storage.
✨ 关键词:SMB、NFS
4️⃣ ✅
💡 解析:需要能够同时支持 SMB 和 NFS 的存储解决方案。
Amazon FSx for NetApp ONTAP通过符合行业标准的 NFS、SMB、iSCSI 和 NVMe-over-TCP 协议向广泛的工作负载和用户提供您的数据。
👨👨👦👦 社区讨论:Amazon FSx for NetApp ONTAP provides shared storage between Linux and Windows file systems.