来源:AWS解决方案架构师认证-助理级(SAA-C03)仿真练习题
3 题,免费题库,题目质量不高,仅供自己复习使用。
如果侵权请联系删除。
🌟 单词:
- spreadv. 传播,扩散,展开,散布 | n. 传播,蔓延,扩展,散布 | adj. 广大的,大幅的,(宝石)薄而无光泽的
- replican. 复制品, 仿制品
- primaryadj. 首要的,主要的;最初的;原本的;第一手的,直接的;初级的,小学的;初等的 | n. 初选者;原色
- attachv. 系;绑;附上;把…固定;认为有重要性(或意义、价值、分量等);喜欢,依恋
- boundariesn. 分界线,边界
一、Placement groups
A solutions architect is designing a high performance computing (HPC) workload on Amazon EC2. The EC2 instances need to communicate to each other frequently and require network performance with low latency and high throughput.
Which EC2 configuration meets these requirements?
1. ✅ Launch the EC2 instances in a cluster placement group in one Availability Zone.
2. Launch the EC2 instances in a spread placement group in one Availability Zone.
3. Launch the EC2 instances in an Auto Scaling group in two Regions and peer the VPCs.
4. Launch the EC2 instances in an Auto Scaling group spanning multiple Availability Zones.
✨ 关键词:HPC、low latency、high throughput、Placement groups
1️⃣ ✅
💡 解析:When you launch a new EC2 instance, the EC2 service attempts to place the instance in such a way that all of your instances are spread out across underlying hardware to minimize correlated failures. You can use placement groups to influence the placement of a group of interdependent instances to meet the needs of your workload. Depending on the type of workload.
Cluster “” packs instances close together inside an Availability Zone. This strategy enables workloads to achieve the low-latency network performance necessary for tightly-coupled node-to-node communication that is typical of HPC applications.
Reference:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.htmlAmazon EC2 实例的置放群组:
- 为了满足工作负载的需求,您可以将一组相互依赖的 EC2 实例启动到一个置放群组中,以影响它们的置放。
- 创建置放群组无需支付费用。
置放群组 英文 备注 集群 Cluster 将一个可用区内靠近的实例打包在一起。通过使用该策略,工作负载可以实现所需的低延迟网络性能,以满足高性能计算(HPC)应用程序通常使用的紧密耦合的节点到节点通信的要求。 分区 Partition 将实例分布在不同的逻辑分区上,以便一个分区中的实例组不会与不同分区中的实例组使用相同的基础硬件。该策略通常为大型分布式和重复的工作负载所使用,例如,Hadoop、Cassandra 和 Kafka。 分布 Spread 将一小组实例严格放置在不同的基础硬件上,以减少相关的故障。
二、Amazon RDS Read Replicas
An application running on AWS uses an Amazon Aurora Multi-AZ deployment for its database. When evaluating performance metrics, a solutions architect discovered that the database reads are causing high I/O and adding latency to the write requests against the database.
What should the solutions architect do to separate the read requests from the write requests?
1. Enable read-through caching on the Amazon Aurora database.
2. Update the application to read from the Multi-AZ standby instance.
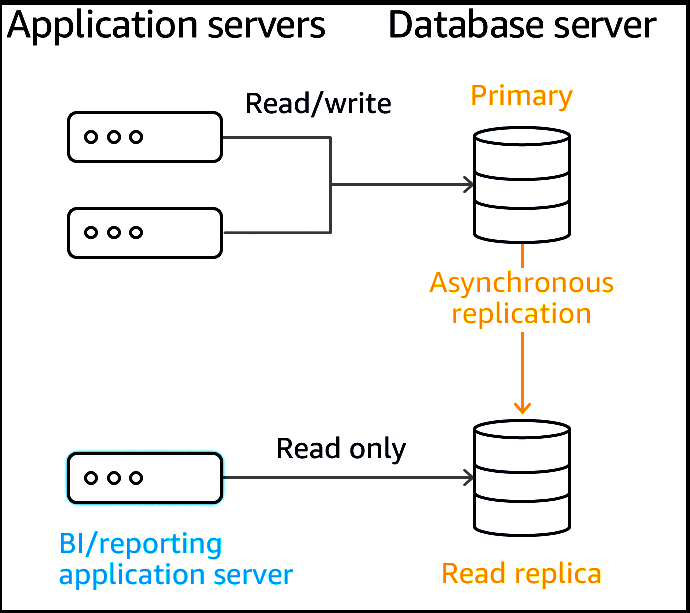
3. ✅ Create a read replica and modify the application to use the appropriate endpoint.
4. ❌ Create a second Amazon Aurora database and link it to the primary database as a read replica.
✨ 关键词:Multi-AZ、Database、读写分离、Amazon RDS Read Replicas
4️⃣ ❌ -> 3️⃣ ✅
💡 解析:Amazon RDS Read Replicas provide enhanced performance and durability for RDS database (DB) instances. They make it easy to elastically scale out beyond the capacity constraints of a single DB instance for read-heavy database workloads. You can create one or more replicas of a given source DB Instance and serve high-volume application read traffic from multiple copies of your data, thereby increasing aggregate read throughput. Read replicas can also be promoted when needed to become standalone DB instances. Read replicas are available in Amazon RDS for MySQL, MariaDB, PostgreSQL, Oracle, and SQL Server as well as Amazon Aurora.
For the MySQL, MariaDB, PostgreSQL, Oracle, and SQL Server database engines, Amazon RDS creates a second DB instance using a snapshot of the source DB instance. It then uses the engines’ native asynchronous replication to update the read replica whenever there is a change to the source DB instance. The read replica operates as a DB instance that allows only read-only connections; applications can connect to a read replica just as they would to any DB instance.
Amazon RDS replicates all databases in the source DB instance. Amazon Aurora further extends the benefits of read replicas by employing an SSD-backed virtualized storage layer purpose-built for database workloads.
Amazon Aurora replicas share the same underlying storage as the source instance, lowering costs and avoiding the need to copy data to the replica nodes. For more information about replication with Amazon Aurora, see the online documentation.
Reference:
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_ReadRepl.html
https://aws.amazon.com/rds/features/read-replicas/
三、IAM Permissions boundaries
A company allows its developers to attach existing IAM policies to existing IAM roles to enable faster experimentation and agility. However, the security operations team is concerned that the developers could attach the existing administrator policy, which would allow the developers to circumvent any other security policies.
How should a solutions architect address this issue?
- Create an Amazon SNS topic to send an alert every time a developer creates a new policy.
- Use service control policies to disable IAM activity across all account in the organizational unit.
- Prevent the developers from attaching any policies and assign all IAM duties to the security operations team.
- ✅ Set an IAM permissions boundary on the developer IAM role that explicitly denies attaching the administrator policy.
✨ 关键词:IAM、permissions boundary、IAM 实体的权限边界
4️⃣ ✅
💡 解析:Reference:
https://docs.aws.amazon.com/IAM/latest/UserGuide/access_policies_boundaries.html
AWS 对于 IAM 实体(用户或角色)支持权限边界。权限边界是一个高级功能,它使用托管策略设置基于身份的策略可以为 IAM 实体授予的最大权限。实体的权限边界仅允许实体执行其基于身份的策略和权限边界同时允许的操作。